Writable序列化
序列化:将内存中的对象 转换成字节序列以便于存储在磁盘上或者用于网络传输。
反序列化:将磁盘或者从网络中接受到的字节序列,装换成内存中的对象。
自定义bean对象(普通java对象)要想序列化传输,必须实现序列化接口。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
(3)重写序列化方法
(4)重写反序列化方法
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),且用”\t”分开,方便后续用
(7)如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序
package com.mapreduce.flow; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; /*
* 实现writable 接口
* 目的: 能够序列化和反序列化 用户自定义的bean对象( 用hadoop 的序列化机制 )
*
*/
public class FlowBean implements Writable { private long upFlow;
private long downFlow;
private long sumFlow; public FlowBean(){
super();
} /*
* 序列化对象
*
*/
public void write(DataOutput out) throws IOException {
out.writeLong(this.upFlow);
out.writeLong(this.downFlow);
out.writeLong(this.sumFlow);
}
/*
* 反序列化对象
*
*/
public void readFields(DataInput in) throws IOException { upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
} public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
//7 如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
}
}
Writable序列化的更多相关文章
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
- MapReduce框架原理-Writable序列化
序列化和反序列化 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输. 反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的 ...
- hadoop学习第四天-Writable和WritableComparable序列化接口的使用&&MapReduce中传递javaBean的简单例子
一. 为什么javaBean要继承Writable和WritableComparable接口? 1. 如果一个javaBean想要作为MapReduce的key或者value,就一定要实现序列化,因为 ...
- hadoop中典型Writable类详解
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable.html,转载请注明源地址. Hadoop将很多Writable类归入org.apac ...
- Hadoop中Writable类
1.Writable简单介绍 在前面的博客中,经常出现IntWritable,ByteWritable.....光从字面上,就可以看出,给人的感觉是基本数据类型 和 序列化!在Hadoop中自带的or ...
- hadoop中的序列化
此文已由作者肖凡授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 最近在学习hadoop,发现hadoop的序列化过程和jdk的序列化有很大的区别,下面就来说说这两者的区别都有 ...
- MapReduce02 序列化
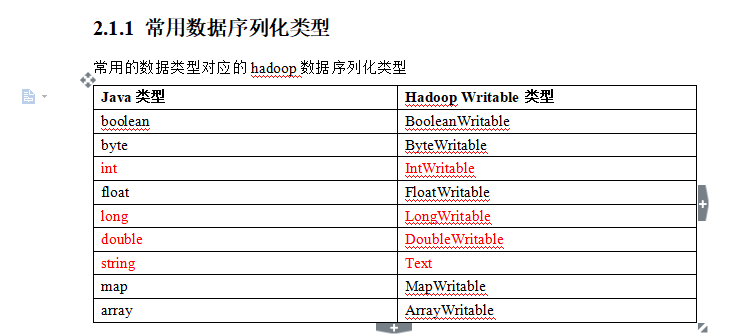
目录 MapReduce 序列化 概述 自定义序列化 常用数据序列化类型 int与IntWritable转化 Text与String 序列化读写方法 自定义bean对象实现序列化接口(Writable ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- 手机号流量统计---Mapreduce项目分析
文档显示: 每行依次是 ~手机号~上行流量~下行流量 需求分析: 需要统计各自的手机号,及上行.下行.总流量 具体做法: 1.定义map输入输出类型 通常情况下map的输入的key-value就是lo ...
随机推荐
- 【MySQL】MySQL视图创建、查询。
视图是指计算机数据库中的视图,是一个虚拟表.关系型数据库中的数据是由一张一张的二维关系表所组成,简单的单表查询只需要遍历一个表,而复杂的多表查询需要将多个表连接起来进行查询任务.对于复杂的查询事件,每 ...
- NDK配置
NDK 配置 Android SDK中下载NDK, LLDB Android.mk 和 Application.mk 简单来说 Android.mk 用来描述需要生成哪些模块的 .so 文件 Appl ...
- Mysql依赖库Boost的源码安装,linux下boost库的安装
boost‘准标准库’安装过程.安装的是boost_1_60_0. (1)首先去下载最新的boost代码包,网址www.boost.org. (2)进入到自己的目录,解压: bzip2 -d bo ...
- 译: 1. RabbitMQ Spring AMQP 之 Hello World
本文是译文,原文请访问:http://www.rabbitmq.com/tutorials/tutorial-one-spring-amqp.html RabbitMQ 是一个Brocker (消息队 ...
- (Java编程思想)Thinking in Java
1. 为什么突然想去研读<Thinking in Java>? 最近终于下定决心撸了一本<Thinking in Java>第四版,虽然在此之前我就久闻这本书的大名,但一直未曾 ...
- 每日英语:The Right Way to Network
With startup-themed conferences, hackathons, meet-ups and cocktail hours regularly taking place, ent ...
- tensorflow 笔记10:tf.nn.sparse_softmax_cross_entropy_with_logits 函数
函数:tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None,name=None) ...
- python 中的map,dict,lambda,reduce,filter
1.map(function,sequence) 对sequence 中的item依次执行function(item), 见执行结果组成一个List返回 例如: #!/usr/bin/python # ...
- Angularjs中config中置入以下拦截器
$httpProvider.interceptors.push(['$rootScope', '$q', '$localStorage', function ($rootScope, $q, $loc ...
- 怎样从Javaproject师成长为架构师?
工作1-5年.当我们向老板提出加薪的时候,或者跳槽去"捡"offer的时候.我们底气够吗? 敢不敢不给涨薪就"挥一挥衣袖.不带走一个bug"?是不是提出要求 ...