Writable序列化
序列化:将内存中的对象 转换成字节序列以便于存储在磁盘上或者用于网络传输。
反序列化:将磁盘或者从网络中接受到的字节序列,装换成内存中的对象。
自定义bean对象(普通java对象)要想序列化传输,必须实现序列化接口。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
(3)重写序列化方法
(4)重写反序列化方法
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),且用”\t”分开,方便后续用
(7)如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序
package com.mapreduce.flow; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; /*
* 实现writable 接口
* 目的: 能够序列化和反序列化 用户自定义的bean对象( 用hadoop 的序列化机制 )
*
*/
public class FlowBean implements Writable { private long upFlow;
private long downFlow;
private long sumFlow; public FlowBean(){
super();
} /*
* 序列化对象
*
*/
public void write(DataOutput out) throws IOException {
out.writeLong(this.upFlow);
out.writeLong(this.downFlow);
out.writeLong(this.sumFlow);
}
/*
* 反序列化对象
*
*/
public void readFields(DataInput in) throws IOException { upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
} public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
//7 如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
}
}
Writable序列化的更多相关文章
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
- MapReduce框架原理-Writable序列化
序列化和反序列化 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输. 反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的 ...
- hadoop学习第四天-Writable和WritableComparable序列化接口的使用&&MapReduce中传递javaBean的简单例子
一. 为什么javaBean要继承Writable和WritableComparable接口? 1. 如果一个javaBean想要作为MapReduce的key或者value,就一定要实现序列化,因为 ...
- hadoop中典型Writable类详解
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable.html,转载请注明源地址. Hadoop将很多Writable类归入org.apac ...
- Hadoop中Writable类
1.Writable简单介绍 在前面的博客中,经常出现IntWritable,ByteWritable.....光从字面上,就可以看出,给人的感觉是基本数据类型 和 序列化!在Hadoop中自带的or ...
- hadoop中的序列化
此文已由作者肖凡授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 最近在学习hadoop,发现hadoop的序列化过程和jdk的序列化有很大的区别,下面就来说说这两者的区别都有 ...
- MapReduce02 序列化
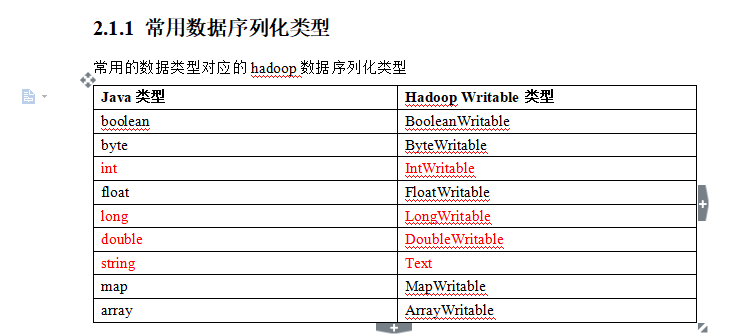
目录 MapReduce 序列化 概述 自定义序列化 常用数据序列化类型 int与IntWritable转化 Text与String 序列化读写方法 自定义bean对象实现序列化接口(Writable ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- 手机号流量统计---Mapreduce项目分析
文档显示: 每行依次是 ~手机号~上行流量~下行流量 需求分析: 需要统计各自的手机号,及上行.下行.总流量 具体做法: 1.定义map输入输出类型 通常情况下map的输入的key-value就是lo ...
随机推荐
- Emacs flycheck插件配置中遇到的若干问题
工欲善其事必先利其器,一个高效的代码检查工具会大大提高我们的开发效率.flycheck是Emacs中常用的一个代码编译检查工具,本文记录配置它的时候遇到的一些问题以及解决方法. flycheck的基本 ...
- Variable used in lambda expression should be final or effectively final
Lambda与匿名内部类在访问外部变量时,都不允许有修改变量的倾向,即若: final double a = 3.141592; double b = 3.141592; DoubleUnaryOpe ...
- [Android App]IFCTT,即:If Copy Then That,一个基于IFTTT的"This"实现
IFCTT,即:If Copy Then That,是一个基于IFTTT(If This Then That)的"This"实现,它打通了"用户手机端操作"与& ...
- spring3-mvc-maven-hello-world-master mvn jetty:run 及 mvn war:war 指令
spring3-mvc-maven-annotation-hello-world-master mvn jetty:run Run this project locally Terminal $ m ...
- 项目通过tomcat部署到服务器,请求数据中文乱码问题
问题: 本地项目请求访问,浏览器中文输出没问题.部署到服务器上面之后,返回到浏览器的中文就乱码了. 尝试办法: 1.修改tomcat下的conf中的service.xml中的配置信息: 重新启动后,没 ...
- 【Spark 深入学习 02】- 我是一个凶残的spark
学一门新鲜的技术,其实过程都是相似的,先学基本的原理和概念,再学怎么使用,最后深究这技术是怎么实现的,所以本章节就带你认识认识spark长什么样的,帅不帅,时髦不时髦(这货的基本概念和原理),接着了解 ...
- FiDDLER教程
FiDDLER教程 摘自:林猪猪的部落格 的 前端工具 1 FIDDLER的使用方法及技巧总结(连载一)FIDDLER快速入门及使用场景 2 FIDDLER的使用方法及技巧总结(连载二)FIDDLER ...
- idea svn 不见的问题
问题一: IntelliJ IDEA打开带SVN信息的项目不显示SVN信息,项目右键SVN以及图标还有Changes都不显示解决方法 在VCS菜单中有个开关,叫Enabled Version Cont ...
- 【iCore4 双核心板_ARM】例程十八:USBD_VCP实验——虚拟串口
实验步骤: 1.将跳线冒跳至USB_OTG,通过Micro USB 线将iCore4 USB-OTG接口与电脑相连. 2.打开设备管理器,可以找到虚拟出来的端口,(特殊情况下如果没有虚拟出端口,我们可 ...
- 【Unity】不能新建项目
问题:Unity5.5.2f1今天遇到个Bug,在启动器点击新建项目没有反应. 办法:先点击新建项目(没有反应),再点击Sign Out退出登录,然后再登录进来,就能跳到新建项目页面.