hbase snapshot 表备份/恢复
snapshot其实就是一组metadata信息的集合,它可以让管理员将表恢复到以前的一个状态。snapshot并不是一份拷贝,它只是一个文件名的列表,并不拷贝数据。一个全的snapshot恢复以为着你可以回滚到原来的表schema和创建snapshot之前的数据。
应用场景:
1获取:该操作尝试从指定的表中获取一个snapshot。该操作在regions作balancing,split或者merge等迁移工作的时候可能会失败。
2拷贝:该操作用指定snapshot的schema和数据来创建一个新表。该操作会不会对 原表或者该snapshot造成任何影响。
3恢复: 该操作将一个表的schema和data回滚到创建该snapshot时的状态。
4删除:该操作将一个snapshot从系统中移除,释放磁盘空间,不会对其他拷贝或者snapshot造成任何影响。
5导出:该操作拷贝这个snapshot的data和metadata到另一个集群。该操作仅影响HDFS,并不会和hbase的Master或者Region Server通信(这些操作可能会导致集群挂掉)。
首先我们要理解,HBase的底层存储文件HFile是什么,以及是怎么被生成的、怎么被删除的(或者叫生命周期)。其次就不难理解Snapshot为什么不需要复制业务数据了。
1. HFile是什么
HBase是一个Key-Value数据库,其基本数据操作(如Put、Delete等)最后都化归为Key-Value对,存储在HDFS的一个个文件(HFile)中: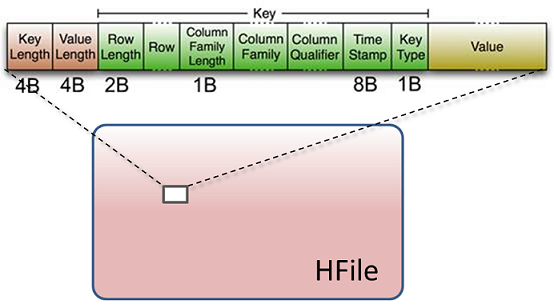
注意上图绿色的Key字段中,最后有个1 Byte的Key Type域,即是用来区分Put和Delete的。
另外更需注意的一点是,HBase的Delete操作并不是立即定位到目标数据将其删除或者做个删除标记,因为HDFS不支持这种随机写。Delete操作也跟Put一样存储,只是Key Type域不一样,以及Value域为空而已。HBase在读取时,会将拥有Delete操作的数据过滤掉。而具体何时删除目标数据,则是在对HFile做Compaction时。
2. HFile的两种生成方式
HFile有两种生成方式,分别是MemStore Flush和Compaction
MemStore Flush
写操作(Put、Delete等)在WAL(Write-Ahead Log)提交成功后,马上会写入对应Region Server的内存缓冲区(MemStore)中。在MemStore里这些操作是按key排好序的。当MemStore写满时,就会将这些数据写入到HDFS中成为一个HFile。
Compaction
HFile内部的数据是按key排好序的,但HFile之间的数据并不能保证key的顺序,也就是说,对于新生成的HFile,其里面的key值并不都比老的HFile的大。因此每次检索时,都需要在所有HFile中检索一次,再将结果合并。虽然HBase针对这个设计了各种加速机制(如Bloom Filter),但HFile文件数目一多还是会比较吃力,因此就需要对HFile做合并操作(Compaction)。Compaction分为minor和major两种级别,本质上都是从几个HFile生成合并后的HFile(类似于合并几个有序数组),然后,老的HFile被删除,起用合并后的HFile。
3. HFile何时会被删除
上面提到过的,在完成Compaction后,老的HFile就会被删除,起用合并后的HFile。
4. Snapshot操作的实现
细心的你是否发现了一个事实,HFile是不会被追加或者修改的!HFile一旦生成,就不会再被改变,只有被拿去合并后,生成了新的HFile,完成自己的使命时才会被删除。
那如果不删除呢?
比如说,我今天建了个表开始跑业务,这个表总共生成了10个HFile,第二天又生成一些HFile,并因此触发了合并操作,现在启用的HFile里有一些是老的没被合并的,有一些是新的由合并产生的。如果昨天那10个HFile还在,那我只要让这个表启用原来的这10个HFile,不就回滚到昨天的状态了嘛。依靠的是什么?就是这10个HFile自从诞生之后就不会被改动,连追加都不会。他们像琥珀一样,记录了这个表昨天的所有数据。
因此,建立Snapshot其实就是把当前所有启用的HFile文件名记录下来,并提醒系统在Compaction时不要删除它们。恢复Snapshot就是重新启用当时的那些HFile。当然这两句话说得不严谨,还有一些细节要处理,比如建Snapshot时要把内存里的东西也存下来先。具体是这样的:
建立Snapshot
1,Master与RegionServer同步,让他们同时进行MemStore flush
2,记录MetaData,即当前表有哪些region,每个region使用的HFile是哪些
3,“标记”HFile以防被删除
*建立Snapshot的过程不需要让表下线。
恢复Snapshot
根据Snapshot对应的MetaData恢复各个region,该表需要先下线
5.HBase Shell: Snapshot 操作
想使用snapshot功能,请确认你的hbase-site.xml中的hbase.snapshot.enabled 配置项为true
<property>
<name>hbase.snapshot.enabled</name>
<value>true</value>
</property>
5.1表上创建snapshot
hbase(main):003:0> snapshot 'abc','spabc'
(abc为表名字,spabc为快照名字)
5.2查看快照
hbase(main):004:0> list_snapshots
5.3恢复快照
hbase(main):012:0> deleteall 'abc','admin'
(删除rowkey为admin 的整行)
hbase(main):013:0> scan 'abc'
hbase(main):016:0> disable 'abc'
hbase(main):017:0> restore_snapshot 'spabc'
(spabc为快照名字)
hbase(main):018:0> enable 'abc'
hbase(main):019:0> scan 'abc'
删除的数据又回来了
5.4删除快照
hbase(main):001:0> delete_snapshot 'spabc'
hbase snapshot 表备份/恢复的更多相关文章
- 云HBase备份恢复,为云HBase数据安全保驾护航
摘要: 介绍了阿里云HBase自研备份恢复功能的基本背景以及基本原理架构和基本使用方法. 云HBase发布备份恢复功能,为用户数据保驾护航.对大多数公司来说数据的安全性以及可靠性是非常重要的,如何 ...
- HBase备份恢复练习
一.冷备 1.创建测试表并插入测试数据 [root@weekend05 ~]# hbase shell hbase(main):005:0> create 'scores','grade','c ...
- 从xtrabackup备份恢复单表
目前对MySQL比较流行的备份方式有两种,一种上是使用自带的mysqldump,另一种是xtrabackup,对于数据时大的环境,普遍使用了xtrabackup+binlog进行全量或者增量备份,那么 ...
- 从完整备份恢复单个innodb表
现在大多数同学在线上采取的备份策略都是xtrabackup全备+binlog备份,那么当某天某张表意外的删除那么如何从xtrabackup全备中恢复呢?从mysql 5.6版本开始,支持可移动表空间( ...
- mysql 数据表备份导出,恢复导入操作实践
因为经常跑脚本的关系, 每次跑完数据之后,相关的测试服数据库表的数据都被跑乱了,重新跑脚本恢复回来速度也不快,所以尝试在跑脚本之前直接备份该表,然后跑完数据之后恢复的方式,应该会方便一点.所以实践一波 ...
- 从xtrabackup备份恢复单表【转】
目前对MySQL比较流行的备份方式有两种,一种上是使用自带的mysqldump,另一种是xtrabackup,对于数据时大的环境,普遍使用了xtrabackup+binlog进行全量或者增量备份,那么 ...
- MySQL 备份恢复(导入导出)单个 innodb表
MySQL 备份恢复单个innodb表呢,对于这种恢复我们我们很多朋友都不怎么了解了,下面一起来看一篇关于MySQL 备份恢复单个innodb表的教程 在实际环境中,时不时需要备份恢复单个或多个表(注 ...
- SYSTEM 表空间管理及备份恢复
标签: systemoraclesqldatabasefile数据库 2010-11-28 18:14 12689人阅读 评论(0) 收藏 举报 分类: -----Oracle备份恢复(16) 版权声 ...
- ORACLE表空间offline谈起,表空间备份恢复
从ORACLE表空间offline谈起,表空间备份恢复将表空间置为offline,可能的原因包括维护.备份恢复等目的:表空间处于offline状态,那么Oracle不会允许任何对该表空间中对象的SQL ...
随机推荐
- 对于一个WEB前端初学者,学前端应该注意,有什么技巧
web前端经验总结需要注意的地方和技巧如下: 1.编程思维 学习web前端开发核心在于一个“编程思维”,因为每段代码都不一样,都需要分别去看,所以只要你掌握了学习web前端的编程思维,那么写程序对于你 ...
- 解决 win10飞行模式 无限自动开关 无法关闭
驱动问题,名为“Insyde Airplane Mode HID Mini-Driver”的驱动,这个驱动是专门用来快捷管理飞行模式的. 卸载完成后重启,无限开关飞行模式问题得到解决!
- Win7系统修改hosts无法保存怎么办?
背景 有的时候我们需要修改hosts文件,但是在某些情况下竟提示保存不了.之前有一次IntelliJ IDEA提示我快到期了,于是我到网上找到了一个激活方法,但需要将一个地址放到hosts文件中去,此 ...
- Luogu P5284 [十二省联考2019]字符串问题
好难写的字符串+数据结构问题,写+调了一下午的说 首先理解题意后我们对问题进行转化,对于每个字符串我们用一个点来代表它们,其中\(A\)类串的点权为它们的长度,\(B\)类串的权值为\(0\) 这样我 ...
- 【死磕 Spring】----- IOC 之深入理解 Spring IoC
在一开始学习 Spring 的时候,我们就接触 IoC 了,作为 Spring 第一个最核心的概念,我们在解读它源码之前一定需要对其有深入的认识,本篇为[死磕 Spring]系列博客的第一篇博文,主要 ...
- PHP内核之旅-5.强大的数组
PHP 内核之旅系列 PHP内核之旅-1.生命周期 PHP内核之旅-2.SAPI中的Cli PHP内核之旅-3.变量 PHP内核之旅-4.字符串 PHP内核之旅-5.强大的数组 PHP内核之旅-6.垃 ...
- Ansible自动化运维工具安装与使用实例
1.准备两台服务器,要确定网络是通的.服务器当然越多越好啦....Ansible的简介和好处我就不多说了,自己看百科去(*╹▽╹*) IP:192.168.139.100 IP:192.168.139 ...
- 【Netty】(5)源码 Bootstrap
[Netty]5 源码 Bootstrap 上一篇讲了AbstractBootstrap,为这篇做了个铺垫. 一.概述 Bootstrap 是 Netty 提供的一个便利的工厂类, 我们可以通过它来完 ...
- DotNetCore跨平台~关于appsettings.json里各种配置项的读取
回到目录 对于dotnet Core来说,依赖注入的集成无疑是最大的亮点,它主要用在服务注册与注入和配置文件注册与注入上面,我们一般会在程序入口先注册服务或者文件,然后在需要的地方使用注入即可,下面主 ...
- VC6.0打开或添加工程时崩溃的解决方法
官方解决办法(英文):http://support.microsoft.com/kb/241396/en-us 网友解决(中文):http://blog.163.com/wjatnx@yeah/blo ...