zList一个块状链表算法可以申请和释放同种对象指针,对于大数据量比直接new少需要差不多一半内存
zList是一个C++的块状内存链表,特点:
1、对于某种类别需要申请大量指针,zList是一个很好的帮手,它能比new少很多内存。
2、它对内存进行整体管理,可以将数据和文件快速互操作
3、和vector对象存储对比,vector存储的对象不能使用其指针,因为vector内容变化时vector存储对象的指针会变化
4、zList也可以当做顺序的数组使用,它有自己的迭代器,可以遍历整个数组
下面是申请5千万个RECT指针对比结果:
zList申请五千万RECT指针内存占用: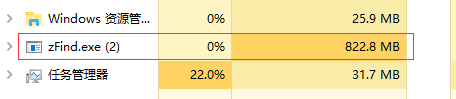
直接new五千万RECT指针内存占用: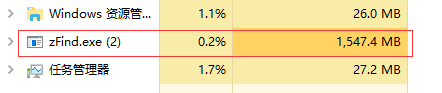
从对比看节省了724.6M的内存
下面是zList实现代码:
#include "stdafx.h"
#include <set>
#include <map>
#include <string>
#include <vector>
#include <windows.h>
using namespace std; template <class T>
struct zElem
{
zElem() { memset(this, , sizeof(zElem)); }
int has() //查找空闲的位置
{
return extra < ? extra : -;
}
bool empty() { return == size; };
bool full() { return == size; };
T *add(int i, const T &r)
{
bit[i] = ;
R[i] = r;
size++;
if (extra == i)//指向下一个位置
{
extra++;
while (extra < )
{
if (bit[extra] == )break;
extra++;
}
}
return R + i;
}
void remove(T *r)
{
int i = (int)(r - R);
if (i >= && i < )
{
bit[i] = ;
if (extra > i)extra = (unsigned short)i;
size--;
}
}
bool in(T *r)
{
int i = (int)(r - R);
return i >= && i < ;
}
T* get(int i)
{
int ind = getInd(i);
return ind == - ? NULL : R + ind;
}
int getInd(int i)
{
if (i >= && i < extra)return i;
int k = extra + , t = extra;
while (k < )
{
if (bit[k] != )
{
if (t == i)return k;
t++;
}
k++;
}
return -;
}
bool getInd(size_t &ind, size_t &off, size_t n)
{
if (ind + n < extra)
{
ind += n;
off = ind;
return true;
}
while (++ind < )
{
if (bit[ind] != )
{
n--;
off++;
if (n==)return true;
}
}
return false;
}
unsigned short extra;//指向当前空闲位置
unsigned short size; //当前已有数据个数
byte bit[]; //标记是否使用
T R[]; //数据存储
};
template <class T>
struct zList
{
struct iterator
{
T* operator *()
{
return p ? &p->head[ind]->R[zind] : NULL;
}
T* operator ->()
{
return p ? &p->head[ind]->R[zind] : NULL;
}
iterator& operator ++()
{
bool bend = true;
if (p&&p->head.size() > ind)
{
for (; ind < p->head.size(); ind++)
{
zElem<T>*a = p->head[ind];
if (zsize + < a->size)
{
a->getInd(zind,zsize,);
bend = false;
break;
}
zind = zsize = -;
}
}
if (bend)
{
ind = zsize = zind = ; p = ;
}
return (*this);
}
bool operator ==(const iterator &data)const
{
return ind == data.ind&&zind == data.zind&&zsize == data.zsize&&p == data.p;
}
bool operator !=(const iterator &data)const
{
return ind != data.ind||zind != data.zind||zsize != data.zsize||p != data.p;
}
explicit operator bool() const
{
return (!p);
}
size_t ind; //p的位置
size_t zind; //zElem中的R位置
size_t zsize; //zElem中zind位置所在的次序
zList *p; //指向链表的指针
};
zList() :size(), extra() { }
~zList()
{
for (auto &a: head)
{
delete a;
}
}
T *add(const T &r)
{
zElem<T>* e;
if (extra >= head.size())
{
e = new zElem<T>();
head.push_back(e);
}
else
{
e = head[extra];
}
int i = e->has();
T *R = e->add(i, r);
size++;
while (extra < head.size() && e->full())
{
e = head[extra];
extra++;
}
return R;
}
void remove(T *r)
{
if (r == NULL)return;
zElem<T> *rem;
size_t i = ;
for (; i < head.size(); i++)
{
rem = head[i];
if (rem->in(r))
{
size--;
rem->remove(r);
if (rem->empty())//删除当前节点
{
head.erase(head.begin() + i);
if (extra == i)
{
//往后查找空闲的位置
while (extra < head.size())
{
if (!head[extra]->full())break;
extra++;
}
}
delete rem;
}
else if(extra > i)
{
extra = i;
}
break;
}
}
}
T* get(int i)
{
for (auto &a : head)
{
if (i < a->size)
{
return a->get(i);
}
i -= a->size;
}
return NULL;
}
void clear()
{
for (auto &a : head)
{
delete a;
}
head.clear();
size = extra = ;
}
iterator begin()
{
iterator it = { ,,,NULL };
if (head.size() > )
{
int i = ;
for (;it.ind < head.size(); it.ind++)
{
zElem<T>*a = head[it.ind];
if (i < a->size)
{
it.p = this;
it.zind = a->getInd(i);
break;
}
i -= a->size;
}
}
return it;
}
iterator end()
{
iterator it = {,,,NULL};
return it;
}
size_t size; //个数
vector<zElem<T>*> head; //开头
size_t extra; //有空余位置的
};
使用方法如下:
int main()
{
zList<RECT> z;
for (int i = ; i < ; i++)
{
//1、申请内存
RECT r = { rand(), rand(), rand(), rand() };
RECT *p = z.add(r);
//2、可以对p进行使用...
//3、释放内存
z.remove(p);
}
getchar();
return ;
}
对zList进行元素遍历,迭代器方法:
int t = ;
zList<RECT>::iterator its = z.begin();
zList<RECT>::iterator ite = z.end();
for (; its != ite; ++its)
{
RECT *p = *its;
t = p->left;
}
对zList进行随机访问遍历,效率没有迭代器高:
int t = ;
for (int i = ; i < z.size; i++)
{
RECT *p = z.get(i);
t = p->left;
}
zList一个块状链表算法可以申请和释放同种对象指针,对于大数据量比直接new少需要差不多一半内存的更多相关文章
- php 大数据量及海量数据处理算法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目, ...
- 解决WCF大数据量传输 ,System.Net.Sockets.SocketException: 远程主机强迫关闭了一个现有的连接
开发中所用的数据需要通过WCF进行数据传输,结果就遇到了WCF大量传输问题 也就是提示System.Net.Sockets.SocketException: 远程主机强迫关闭了一个现有的连接 网上解决 ...
- 大数据量表中,增加一个NOT NULL的新列
这次,发布清洗列表功能,需要对数据库进行升级.MailingList表加个IfCleaning字段,所有的t_User*表加个IfCleaned字段. 脚本如下 对所有的t_User表执行 a ...
- 【POJ2887】【块状链表】Big String
Description You are given a string and supposed to do some string manipulations. Input The first lin ...
- 读<大数据日知录:架构与算法>有感
前一段时间, 一个老师建议我能够学学 '大数据' 和 '机器学习', 他说这必定是今后的热点, 学会了, 你就是香饽饽.在此之前, 我对大数据, 机器学习并没有非常深的认识, 总觉得它们是那么的缥缈, ...
- php获胜的算法的概率,它可用于刮,大转盘等彩票的算法
php获胜的算法的概率,它可用于刮,大转盘等彩票的算法. easy,代码里有具体凝视说明.一看就懂 <?php /* * 经典的概率算法, * $proArr是一个预先设置的数组. * 假设数组 ...
- 滴滴大数据算法大赛Di-Tech2016参赛总结
https://www.jianshu.com/p/4140be00d4e3 题目描述 建模方法 特征工程 我的几次提升方法 从其他队伍那里学习到的提升方法 总结和感想 神经网络方法的一点思考 大数据 ...
- parquet文件格式——本质上是将多个rows作为一个chunk,同一个chunk里每一个单独的column使用列存储格式,这样获取某一row数据时候不需要跨机器获取
Parquet是Twitter贡献给开源社区的一个列数据存储格式,采用和Dremel相同的文件存储算法,支持树形结构存储和基于列的访问.Cloudera Impala也将使用Parquet作为底层的存 ...
- 教你做一个牛逼的DBA(在大数据下)
一.基本概念 大数据量下,搞mysql,以下概念需要先达成一致 1)单库,不多说了,就是一个库 2)分片(sharding),水平拆分,用于解决扩展性问题,按天拆分表 3)复制(replication ...
随机推荐
- .NET Core IdentityServer4实战 第一章-入门与API添加客户端凭据
内容:本文带大家使用IdentityServer4进行对API授权保护的基本策略 作者:zara(张子浩) 欢迎分享,但需在文章鲜明处留下原文地址. 本文将要讲述如何使用IdentityServer4 ...
- js-刮刮卡效果,由jquery-eraser源码改的vue组件
vue-eraser 一款用于vue刮刮卡的组件 github地址: vue-eraser npm地址: vue-eraser 在网上有看到过几个版本的组件,都有点问题 1.拉快了,就会断,连不起来( ...
- [翻译 EF Core in Action 1.6]你的第一个EF Core应用程序
Entity Framework Core in Action Entityframework Core in action是 Jon P smith 所著的关于Entityframework Cor ...
- sympy科学计算器
SymPy库常用函数 简介 本文抄于https://www.cnblogs.com/baby123/p/6296629.html SymPy是一个符号计算的Python库.它的目标是成为一个全功能的计 ...
- 免费开源ERP-成功案例分析(1)
Odoo用户案例 Odoo用户概要 关于Odoo全球的用户,我们来看一些数据: Odoo目前全球有300万使用者 Odoo系统上每天新创建的数据库超过1000个 Odoo和Word.Excel.Pow ...
- android---动画入门(一)
android 动画分为两类,View Animation(视图动画)和property Animation(属性动画),View Animation(视图动画)包含了Tween Animation和 ...
- sql语句 汉字转拼音首字母
(1)------------------------------------------------------------------------------------------------- ...
- SQL基础语法
数据库: 结构化查询语言(Structured Query Language)简称SQL: 数据库管理系统(Database Management System)简称DBMS: 数据库管理员(Data ...
- Install Windows 2016 on VirtualBox
Download ISO file for Windows 2016 (180 days free). https://www.microsoft.com/en-us/evalcenter/eval ...
- 网络流 P3358 最长k可重区间集问题
P3358 最长k可重区间集问题 题目描述 对于给定的开区间集合 I 和正整数 k,计算开区间集合 I 的最长 k可重区间集的长度. 输入输出格式 输入格式: 的第 1 行有 2 个正整数 n和 k, ...