Python函数学习——递归
递归函数
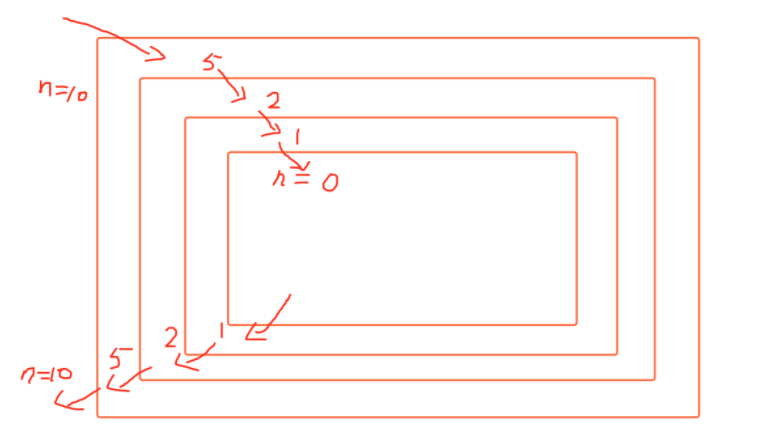
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
函数实现过程
def calc(n):
v = int(n//2)
print(v)
if v > 0:
calc(v)
print(n) calc(10)
输出结果
5
2
1
0
1
2
5
10
为什么是这个结果
递归特性:
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 一般通过return结束递归
- 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
- 堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
递归深度
python默认对最大递归层数做了一个限制:997,但是也可以自己限制
import sys
sys.setrecursionlimit(10000)#修改递归层数
n=0
def f():
global n
n+=1
print(n)
f()
f()
递归应用
1.下面我们来猜一下小明的年龄
小明是新来的同学,丽丽问他多少岁了。
他说:我不告诉你,但是我比滔滔大两岁。
滔滔说:我也不告诉你,我比晓晓大两岁
晓晓说:我也不告诉你,我比小星大两岁
小星也没有告诉他说:我比小华大两岁
最后小华说,我告诉你,我今年18岁了
这个怎么办呢?当然,有人会说,这个很简单啊,知道小华的,就会知道小星的,知道小星的就会知道晓晓的,以此类推,就会知道小明的年龄啦。这个过程已经非常接近递归的思想了。

用递归实现
"""
age(5) = age(4)+2
age(4) = age(3) + 2
age(3) = age(2) + 2
age(2) = age(1) + 2
age(1) = 18
""" def calc_age(n):
if n == 1:
return 18
else:
return calc_age(n-1)+2 print(calc_age(5)) #
2.一个数,除2直到不能整除2
n = 100
def cal(n):
if n == 0:
return
else:
n = int(n // 2)
print(n)
cal(n)
print("退出=", n)
cal(100)
3.一个数,除2直到次数等于5退出
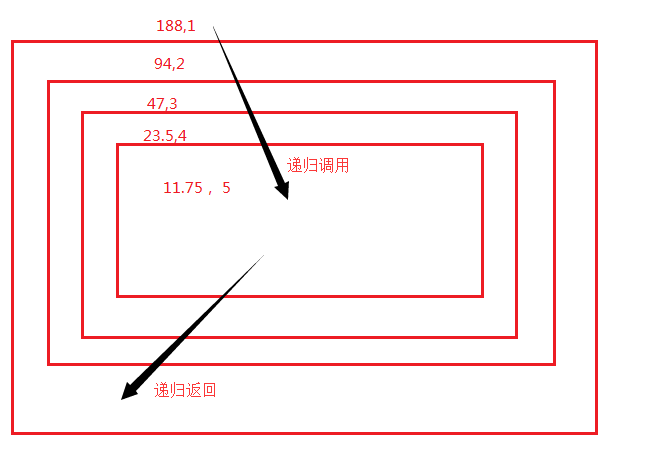
def calc(n,count):
print(n, count)
if count < 5:
r = calc(n / 2, count + 1)
return r # 里层返回为上层,此处不加return 返回None
else:
return n # 最里层返回 res = calc(188, 1)
print('res ', res)
递归调用过程
4.深度查询
menus = [
{
'text': '北京',
'children': [
{'text': '朝阳', 'children': []},
{'text': '昌平', 'children': [
{'text': '沙河', 'children': []},
{'text': '回龙观', 'children': []},
]},
]
},
{
'text': '上海',
'children': [
{'text': '宝山', 'children': []},
{'text': '金山', 'children': []},
]
}
]
# 深度查询
#1. 打印所有的节点
#2. 输入一个节点名字,沙河, 你要遍历找,找到了,就打印它,并返回true,
实现
# 打印所有的节点
def recu_Menu(menu):
for sub_menu in menu:
menu_text = sub_menu['text']
menu_children = sub_menu['children']
print(menu_text)
recu_Menu(menu_children) recu_Menu(menus) # 打印所有的节点,输入一个节点名字,沙河, 你要遍历找,找到了,就打印它,并返回true,
def recu_Menu_node(menu, node, layer):
# if len(menu)>0:
for sub_menu in menu:
menu_text = sub_menu['text']
menu_children = sub_menu['children']
print("menu_text=", menu_text)
if node == menu_text:
print("找到%s在第%s层" % (node, layer)) #返回到外层
return True
else:
if recu_Menu_node(menu_children, node, layer + 1) == True: #如果里层返回True,继续向上返回True
return True
else:
recu_Menu_node(menu_children, node, layer + 1)
node_str = input("输入一个节点名字-> ")
print(recu_Menu_node(menus, node_str, 1)) -》回龙观
找到回龙观在第3层
True
5.猴子吃桃问题
# 题目:猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个
# 第二天早上又将剩下的桃子吃掉一半,又多吃了一个。
# 以后每天早上都吃了前一天剩下的一半零一个。
# 到第10天早上想再吃时,见只剩下一个桃子了。求第一天共摘了多少。 """
下一天等于是前一天吃了一半还多一个剩下的。
所以f(n) = 2 * f(n - 1) + 2
"""
def peach(n):
if n == 1:
return 1
else:
return 2 * peach(n-1) + 2 print(peach(10)) #
6.二分查找算法
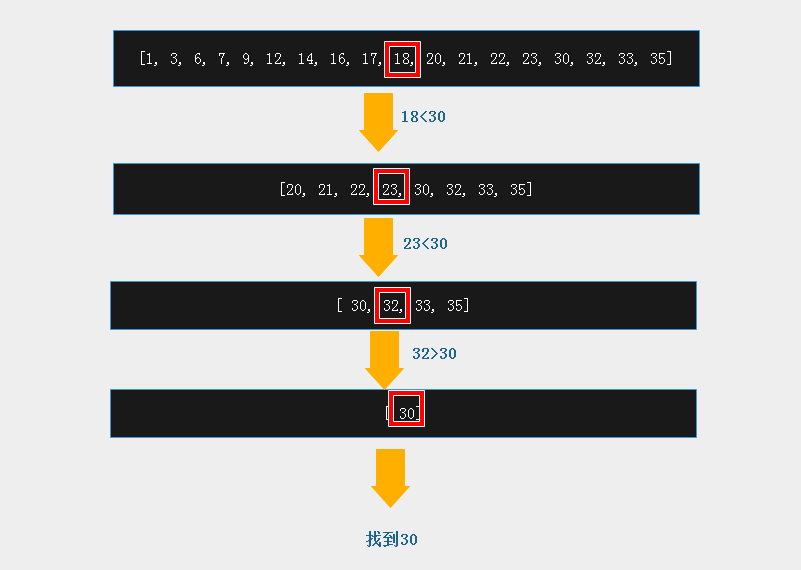
从[1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]序列中找到30的位置
代码实现
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
print('start to find') # 递归二分查找
def binary_search(dataset, start, end, val):
mid = int((start + end)/ 2) # 取中间数
# print(dataset, mid, start, end)
if start <= end:
if dataset[mid] == val: # 判断中间值和要找的那个值的大小关系
print("find val", dataset[mid])
return mid
elif dataset[mid] > val:
print('mid %s is bigger than %s, keep looking in left %s' % (dataset[mid], val, mid))
return binary_search(dataset, start, mid-1, val)
else: # dataset[mid] < val:
print('mid %s is smaller than %s, keep looking in right %s' % (dataset[mid], val, mid))
return binary_search(dataset, mid+1, end, val)
else:
# if dataset[start] == val:
# print('finally find val:', dataset[start])
# return start
# else:
print("data %s doesn't exist in dataset " % val)
return -1 print('start to find')
print(binary_search(data,0,len(data)-1, 30))
输出结果
start to find
mid 17 is smaller than 30, keep looking in right 8
mid 23 is smaller than 30, keep looking in right 13
mid 32 is bigger than 30, keep looking in left 15
find val 30
mid =14 #返回位置为14
另一种实现
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
print('start to find')
def binary_search(dataset, val):
mid = int(len(dataset)/ 2) # 取中间数
print(dataset)
if mid > 0:
if dataset[mid] == val: # 判断中间值和要找的那个值的大小关系
print("find n", dataset[mid])
elif dataset[mid] > val:
new_dataset = dataset[:mid] # 顾头不顾尾
print('mid %s is bigger than %s, keep looking in left %s' % (dataset[mid], val, mid))
binary_search(new_dataset, val)
else: # dataset[mid] < val:
new_dataset = dataset[mid:] # 顾头不顾尾
print('mid %s is smaller than %s, keep looking in right %s' % (dataset[mid], val, mid))
binary_search(new_dataset, val)
else:
if dataset[0] == val:
print('finally find val:', dataset[0])
else:
print("data %s doesn't exist in dataset " % val) binary_search(data,30)
Python函数学习——递归的更多相关文章
- [python 函数学习篇]默认参数
python函数: 默认参数: retries= 这种形式 def ask_ok(prompt, retries=, complaint='Yes or no, please!'): while Tr ...
- python函数学习的总结
python函数 part1 函数的作用: 函数以功能(完成一件事)为导向 随调随用减少代码重复性 增强代码可读性 函数的结构: def 函数名(): 函数体 函数的返回值 return:在函数中遇到 ...
- python函数学习1
函数1 (1)定义: def 函数名(参数列表) 函数体 (2)参数传递: 在python中,一切都是对象,类型也属于对象,变量是没有类型的. a = [1,2,3] a = "hellow ...
- python函数学习之装饰器
装饰器 装饰器的本质是一个python函数,它的作用是在不对原函数做任何修改的同时,给函数添加一定的功能.装饰器的返回值也是一个函数对象. 分类: 1.不带参数的装饰器函数: def wrapper( ...
- Python函数学习遇到的问题
Python函数的关键字参数 Python函数独立星号(*)分隔的命名关键字参数 Python函数中的位置参数 Python中对输入的可迭代对象元素排序的sorted函数 Python中函数的参数带星 ...
- Python 函数之递归
递归函数定义 在函数内部,可以调用其他函数.如果一个函数在内部调用自身本身,这个函数就是递归函数. 我们来计算阶乘 n! = 1 x 2 x 3 x ... x n ,用函数 fact(n) 表示 f ...
- python函数学习(一)
1.parse_known_args()和parse_args()函数 该函数为命令行解析函数,调用时需要import argparse(命令行选项.参数和子命令的解析器). 以下内容摘自python ...
- Python函数学习——初步认识
函数使用背景 假设老板让你写一个监控程序,24小时全年无休的监控你们公司网站服务器的系统状况, 当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警, 你掏空了所有的知识量,写出了以下 ...
- Python函数学习——作用域与嵌套函数
全局与局部变量 在函数中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量. 全局变量作用域是整个程序,局部变量作用域是定义该变量的函数. 当全局变量与局部变量同名时,在定义局部变量的函数内 ...
随机推荐
- Netbeans文件被误删怎么办?
辛辛苦苦写的代码突然不见了,上午还是有的,哪去了?怎么办? 破解办法: 1,良好的版本管理工具(git||svn)使用习惯,代码每天上传更新,技术文件有丢失,也就一天的. 2,Netbeans提供的备 ...
- TP3.2 中使用 PHPMailer 发送邮件
第一步.添加PHPMailer类库 http://pan.baidu.com/s/1o7Zc7V0 第二步.添加发送邮件函数 在common目录中的公共函数文件加入函数 <?php /***** ...
- 【Learning】最小点覆盖(二分图匹配) 与Konig定理证明
(附一道例题) Time Limit: 1000 ms Memory Limit: 128 MB Description 最小点覆盖是指在二分图中,用最小的点集覆盖所有的边.当然,一个二分图的最小 ...
- SpringBoot项目在IntelliJ IDEA中实现热部署
spring-boot-devtools是一个为开发者服务的一个模块,其中最重要的功能就是自动应用代码更改到最新的App上面去.原理是在发现代码有更改之后,重新启动应用,但是速度比手动停止后再启动更快 ...
- 关于adb is down 的两个解决方案
在Android开发过程中经常遇到这样的一个问题,The connection to adb is down, and a severe error has occured. 解决方案一: 1.为了以 ...
- 利用squid 搭建简单的透明代理服务器
环境介绍 虚拟主机1: ip eth0192.168.0.100/24 eth1: 200.168.0.100/24 虚拟主机2(模拟外网) 200.168.0.109/24 (运行web serve ...
- linux内核移植X86平台的例子
bootloader支持启动多个Linux 内核安装(X86平台) 1. cparch/x86/boot/bzImage /boot/vmlinuz-$version 2. cp $initrd /b ...
- AM335x(TQ335x)学习笔记——LCD驱动移植
TI的LCD控制器驱动是非常完善的,共通的地方已经由驱动封装好了,与按键一样,我们可以通过DTS配置完成LCD的显示.下面,我们来讨论下使用DTS方式配置内核完成LCD驱动的思路. (1)初步分析 由 ...
- Linux显示一行显示列总计
Linux显示一行显示列总计 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ free -t total used free shared buffers ca ...
- DirectX--yuv420p上实现的字符叠加
unsigned char *pTemp; BYTE OsdY = 0;BYTE OsdU = 0;BYTE OsdV = 0; void OSDSetTextColor(BYTE OsdR, BYT ...