酷伯伯实时免费HTTP代理ip爬取(端口图片显示+document.write)
分析
打开页面http://www.coobobo.com/free-http-proxy/,端口数字一看就不对劲,老规律ctrl+shift+c选一下:
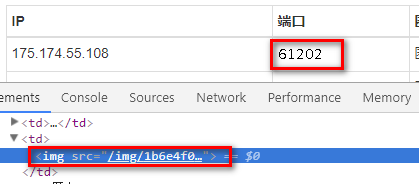
这就很悲剧了,端口数字都是用图片显示的:
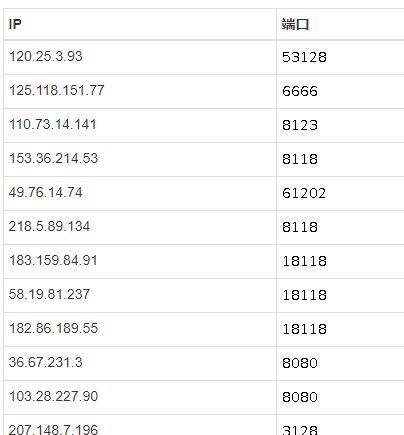
不过没关系,看这些图片长得这么清秀纯天然无杂质,识别是很容易的。
然后再来选一下ip地址:
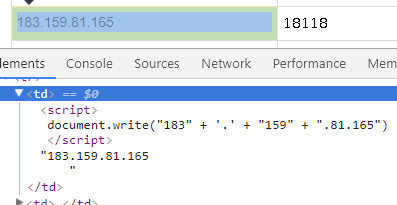
很可能ip地址是用这个js现写进来的,要确定的话还得看一眼返回的原始html,查看源码定位这一个ip:

看来只能从这段js中提取ip地址了,并不是很难,只需要把引号、加号、括号、document.write、空白符抹掉即可,一个正则表达式可以搞定。
代码实现
端口图片比较麻烦,之前写过一个类似的小工具库,对于这种简单字符的识别可以节省一些工作量,这里就使用这个工具库。
因为识别原理就是先收集一些图片标记好谁是啥字符作为依据,然后后面再来的新的都来参考这些已经标记好的,所以需要先收集一些图片来标记:
/**
* 收集需要标注的字符图片
*/
public static void grabTrainImage(String basePath) {
for (int i = 1; i <= 10; i++) {
System.out.println("page " + i);
Document document = getDocument(url + i);
Elements images = document.select("table.table-condensed tbody tr img");
images.forEach(elt -> {
String imgLink = host + elt.attr("src");
byte[] imgBytes = download(imgLink);
try {
String outputPath = basePath + System.currentTimeMillis() + ".png";
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
ImageIO.write(img, "png", new File(outputPath));
System.out.println(imgLink);
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
抓取图片到本地并生成要标注的图片:
public static void main(String[] args) throws IOException {
String rawImageSaveDir = "E:/test/proxy/kubobo/raw/";
String distinctCharSaveDir = "E:/test/proxy/kubobo/char/";
grabTrainImage(rawImageSaveDir);
ocrUtil.init(rawImageSaveDir, distinctCharSaveDir);
}
然后打开E:/test/proxy/kubobo/char/,之前下载的全部图片中用到的所有字符都被分割出来放到了这个目录下:

现在需要将文件名修改为这张图片表示的意思:

需要注意不要标记错了不然后面的就全是错的了。
然后告诉ocrUtil上面这个目录的位置让其知道去哪里加载:
ocrUtil.loadDictionaryMap("E:/test/proxy/kubobo/char/");
然后就可以使用了,只需要把图片传入给ocrUtil.ocr(BufferedImage)即返回这种图片对应的字符,完整的代码如下:
package org.cc11001100.t1; import cc11001100.ocr.OcrUtil;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements; import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List; import static java.util.stream.Collectors.toList; /**
* @author CC11001100
*/
public class KuboboProxyGrab { private static String host = "http://www.coobobo.com";
private static String url = "http://www.coobobo.com/free-http-proxy/"; private static OcrUtil ocrUtil; static {
ocrUtil = new OcrUtil();
ocrUtil.loadDictionaryMap("E:/test/proxy/kubobo/char/");
} /**
* 收集需要标注的字符图片
*/
public static void grabTrainImage(String basePath) {
for (int i = 1; i <= 10; i++) {
System.out.println("page " + i);
Document document = getDocument(url + i);
Elements images = document.select("table.table-condensed tbody tr img");
images.forEach(elt -> {
String imgLink = host + elt.attr("src");
byte[] imgBytes = download(imgLink);
try {
String outputPath = basePath + System.currentTimeMillis() + ".png";
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
ImageIO.write(img, "png", new File(outputPath));
System.out.println(imgLink);
} catch (IOException e) {
e.printStackTrace();
}
});
}
} private static Document getDocument(String url) {
byte[] responseBytes = download(url);
String html = new String(responseBytes, StandardCharsets.UTF_8);
return Jsoup.parse(html);
} private static byte[] download(String url) {
for (int i = 0; i < 3; i++) {
try {
return Jsoup.connect(url).execute().bodyAsBytes();
} catch (IOException e) {
e.printStackTrace();
}
}
return new byte[0];
} public static List<String> grabProxyIpList() {
List<String> resultList = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
System.out.println("page " + i);
Document document = getDocument(url + i);
Elements ipElts = document.select("table.table-condensed tbody tr");
List<String> pageIpList = ipElts.stream().map(elt -> {
String rawText = elt.select("td:eq(0) script").first().data();
String ip = rawText.replaceAll("document.write|[\'\"()+]|\\s+", "").trim(); String imgLink = host + elt.select("td:eq(1) img").attr("src");
byte[] imgBytes = download(imgLink);
try {
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
String port = ocrUtil.ocr(img);
return ip + ":" + port;
} catch (IOException e) {
e.printStackTrace();
}
return "";
}).filter(StringUtils::isNotEmpty).collect(toList());
resultList.addAll(pageIpList);
}
return resultList;
} public static void main(String[] args) throws IOException { // String rawImageSaveDir = "E:/test/proxy/kubobo/raw/";
// String distinctCharSaveDir = "E:/test/proxy/kubobo/char/";
// grabTrainImage(rawImageSaveDir);
// ocrUtil.init(rawImageSaveDir, distinctCharSaveDir); grabProxyIpList().forEach(System.out::println); } }
酷伯伯实时免费HTTP代理ip爬取(端口图片显示+document.write)的更多相关文章
- requests 使用免费的代理ip爬取网站
import requests import queue import threading from lxml import etree #要爬取的URL url = "http://xxx ...
- 蚂蚁代理免费代理ip爬取(端口图片显示+token检查)
分析 蚂蚁代理的列表页大致是这样的: 端口字段使用了图片显示,并且在图片上还有各种干扰线,保存一个图片到本地用画图打开观察一下: 仔细观察蓝色的线其实是在黑色的数字下面的,其它的干扰线也是,所以这幅图 ...
- 代理IP爬取和验证(快代理&西刺代理)
前言 仅仅伪装网页agent是不够的,你还需要一点新东西 今天主要讲解两个比较知名的国内免费IP代理网站:西刺代理&快代理,我们主要的目标是爬取其免费的高匿代理,这些IP有两大特点:免费,不稳 ...
- 代理IP爬取,计算,发放自动化系统
IoC Python端 MySQL端 PHP端 怎么使用 这学期有一门课叫<物联网与云计算>,于是我就做了一个大作业,实现的是对代理IP的爬取,计算推荐,发放给用户等任务的的自动化系统.由 ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- Python爬取谷歌街景图片
最近有个需求是要爬取街景图片,国内厂商百度高德和腾讯地图都没有开放接口,查询资料得知谷歌地图开放街景api 谷歌捷径申请key地址:https://developers.google.com/maps ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
随机推荐
- python 开发之路 - 入门
一. python 介绍 Python是著名的"龟叔"Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言.1991年 发布Python ...
- WebStorm2018破解
参考网站http://www.sdbeta.com/wg/2018/0302/220048.html修改整理如下: webstorm 2018.1正式版破解summary jetbrainscrack ...
- 记录项目中用的laypage分页代码
最终才觉得,好记性不如烂笔头,毕竟已经不是刚毕业时候的巅峰了,精力有所下降,很多时候记不住东西. 参考url:http://www.layui.com/laypage/ 直接上代码了 <scri ...
- HRBUST1522【单调队列+DP】
题目:输入一个长度为n的整数序列(A1,A2,--,An),从中找出一段连续的长度不超过m的子序列,使得这个子序列的和最大. #include<stdio.h> #include<s ...
- Django快速入门
Django 是用 Python 写的一个自由和开放源码 web 应用程序框架.web框架是一套组件,能帮助你更快.更容易地开发web站点.当你开始构建一个web站点时,你总需要一些相似的组件:处理用 ...
- C#:多进程开发,控制进程数量
正在c#程序优化时,如果多线程效果不佳的情况下,也会使用多进程的方案,如下: System.Threading.Tasks.Task task=System.Threading.Tasks.Task. ...
- 使用net.sf.cssbox实现网页截图
需要引用包,在pom.xml中添加引用: <dependency> <groupId>net.sf.cssbox</groupId> <artifactId& ...
- Python3 面向对象编程之程序设计思想发展
概述 1940年以前:面向机器 1940年以前:面向机器 最早的程序设计都是采用机器语言来编写的,直接使用二进制码来表示机器能够识别和执行的指令和数 据.简单来说,就是直接编写 和 的序列来代表程序语 ...
- lsdyna进阶教程-弹性球撞击刚性平板
在lsdyna基础教程中,我们做了一个关于刚性球撞击弹性平板的粒子,现在我们考虑另外一个问题,如果用弹性球撞击刚性地面该怎么做呢?是不是要从头开始建模,操作步骤是不是一样呢?其实很简单,将球和地面的材 ...
- 连接mysql数据库报错java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized...解决方法
今天连接mysql数据库报错如下: java.sql.SQLException: The server time zone value '�й���ʱ��' is unrecognized or r ...