R_针对churn数据用id3、cart、C4.5和C5.0创建决策树模型进行判断哪种模型更合适
data(churn)导入自带的训练集churnTrain和测试集churnTest
用id3、cart、C4.5和C5.0创建决策树模型,并用交叉矩阵评估模型,针对churn数据,哪种模型更合适
决策树模型 ID3/C4.5/CART算法比较 传送门
data(churn)为R自带的训练集,这个data(chun十分特殊)
先对data(churn)训练集和测试集进行数据查询
churnTest数据
奇怪之处,不能存储它的数据,不能查看数据的维度 ,不能查看数据框中每个变量的属性!!
> data(churn)
> Gary<-data(churn)
>
> dim(data(churn))
NULL
> dim(Gary)
NULL
>
> str(data(churn))
chr "churn"
> str(Gary)
chr "churn"
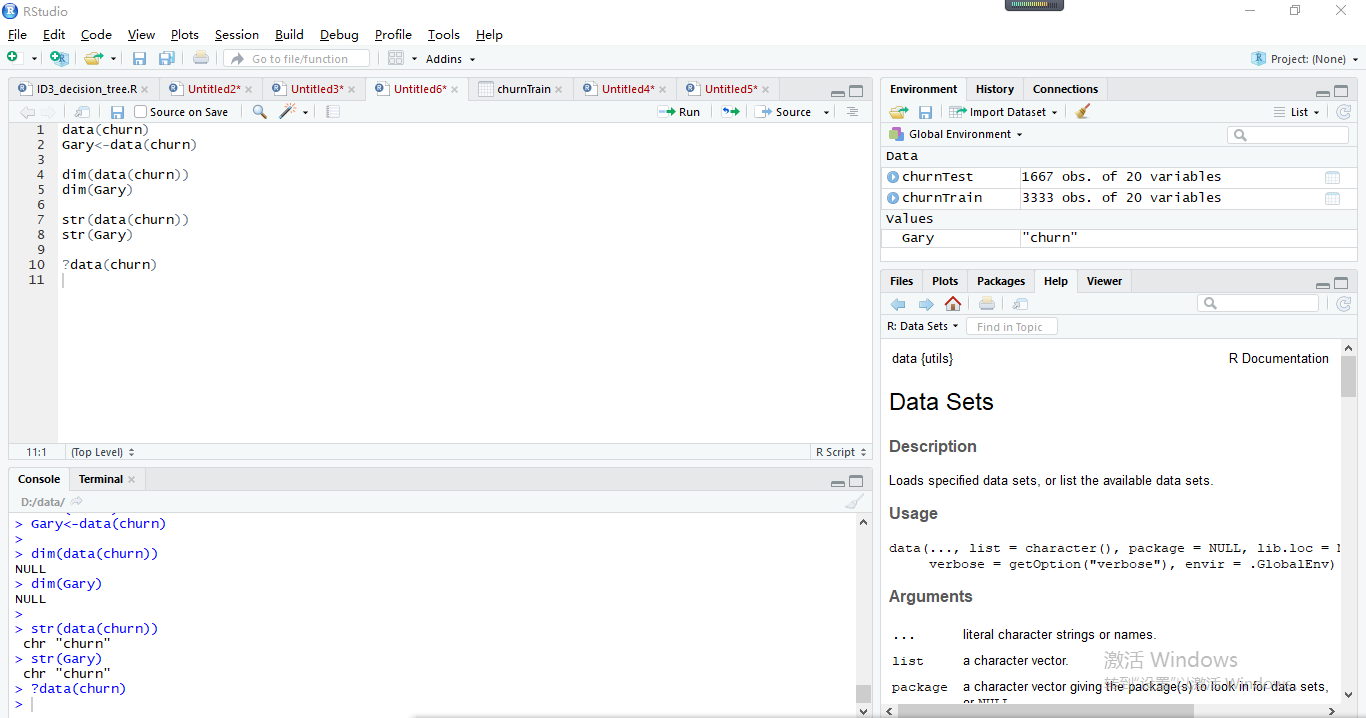
官方我只看懂了它是一个数据集:加载指定的数据集,或列出可用的数据集(英文文档真是硬伤∑=w=)
用不同决策树模型去预测它churn数据集,比较一下哪种模型更合适churn数据
比较评估模型(预测)的正确率
#正确率
sum(diag(tab))/sum(tab)
id3创建决策树模型
#加载数据
data(churn) #随机抽样设置种子,种子是为了让结果具有重复性
set.seed(1) library(rpart) Gary1<-rpart(churn~.,data=churnTrain,method="class", control=rpart.control(minsplit=1),parms=list(split="information"))
printcp(Gary1) #交叉矩阵评估模型
pre1<-predict(Gary1,newdata=churnTrain,type='class')
tab<-table(pre1,churnTrain$churn)
tab #评估模型(预测)的正确率
sum(diag(tab))/sum(tab)
Gary1.Script
pre1 yes no
yes 360 27
no 123 2823 > sum(diag(tab))/sum(tab)
[1] 0.9549955
cart创建决策树模型
data(churn) set.seed(1) library(rpart) Gary1<-rpart(churn~.,data=churnTrain,method="class", control=rpart.control(minsplit=1),parms=list(split="gini"))
printcp(Gary1) #交叉矩阵评估模型
pre1<-predict(Gary1,newdata=churnTrain,type='class')
tab<-table(pre1,churnTrain$churn)
tab #评估模型(预测)的正确率
sum(diag(tab))/sum(tab)
Gary2.Script
pre1 yes no
yes 354 35
no 129 2815 > sum(diag(tab))/sum(tab)
[1] 0.9507951
C4.5创建决策树模型
data(churn) library(RWeka) #oldpar=par(mar=c(3,3,1.5,1),mgp=c(1.5,0.5,0),cex=0.3) Gary<-J48(churn~.,data=churnTrain) tab<-table(churnTrain$churn,predict(Gary))
tab
#评估模型(预测)的正确率
sum(diag(tab))/sum(tab)
Gary3.Script
yes no
yes 359 124
no 24 2826
> sum(diag(tab))/sum(tab)
[1] 0.9555956
C5.0创建决策树模型
data(churn)
treeModel <- C5.0(x = churnTrain[, -20], y = churnTrain$churn) ruleModel <- C5.0(churn ~ ., data = churnTrain, rules = TRUE) tab<-table(churnTest$churn,predict(ruleModel,churnTest))
tab
#评估模型(预测)的正确率
sum(diag(tab))/sum(tab)
Gary4.Script
yes no
yes 149 75
no 15 1428
> sum(diag(tab))/sum(tab)
[1] 0.9460108
实现过程
id3创建决策树模型:
加载数据,随机抽样设置种子,种子是为了让结果具有重复性
data(churn) set.seed(1)
使用rpart包创建决策树模型
> Gary1<-rpart(churn~.,data=churnTrain,method="class", control=rpart.control(minsplit=1),parms=list(split="information"))
> printcp(Gary1) Classification tree:
rpart(formula = churn ~ ., data = churnTrain, method = "class",
parms = list(split = "information"), control = rpart.control(minsplit = 1)) Variables actually used in tree construction:
[1] international_plan number_customer_service_calls state
[4] total_day_minutes total_eve_minutes total_intl_calls
[7] total_intl_minutes voice_mail_plan Root node error: 483/3333 = 0.14491 #根节点错误:483/3333=0.14491 n= 3333 CP nsplit rel error xerror xstd #错误的XSTD
1 0.089027 0 1.00000 1.00000 0.042076
2 0.084886 1 0.91097 0.95445 0.041265
3 0.078675 2 0.82609 0.90269 0.040304
4 0.052795 4 0.66874 0.72878 0.036736
5 0.022774 7 0.47412 0.51139 0.031310
6 0.017253 9 0.42857 0.49068 0.030719
7 0.012422 12 0.37681 0.46170 0.029865
8 0.010000 17 0.31056 0.43892 0.029171
交叉矩阵评估模型
> pre1<-predict(Gary1,newdata=churnTrain,type='class')
> tab<-table(pre1,churnTrain$churn)
> tab pre1 yes no
yes 360 27
no 123 2823
对角线上的数据实际值和预测值相同,非对角线上的值为预测错误的值
评估模型(预测)的正确率
> sum(diag(tab))/sum(tab)
[1] 0.9549955
diag(x = 1, nrow, ncol) diag(x) <- value 解析: x:一个矩阵,向量或一维数组,或不填写。 nrow, ncol:可选 行列。 value :对角线的值,可以是一个值或一个向量
diag()函数
cart创建决策树模型:
与id3区别parms=list(split="gini"))
Gary1<-rpart(churn~.,data=churnTrain,method="class", control=rpart.control(minsplit=1),parms=list(split="gini"))
解释略
> data(churn)
>
> set.seed(1)
>
> library(rpart)
>
> Gary1<-rpart(churn~.,data=churnTrain,method="class", control=rpart.control(minsplit=1),parms=list(split="gini"))
> printcp(Gary1) Classification tree:
rpart(formula = churn ~ ., data = churnTrain, method = "class",
parms = list(split = "gini"), control = rpart.control(minsplit = 1)) Variables actually used in tree construction:
[1] international_plan number_customer_service_calls state
[4] total_day_minutes total_eve_minutes total_intl_calls
[7] total_intl_minutes voice_mail_plan Root node error: 483/3333 = 0.14491 n= 3333 CP nsplit rel error xerror xstd
1 0.089027 0 1.00000 1.00000 0.042076
2 0.084886 1 0.91097 0.96273 0.041414
3 0.078675 2 0.82609 0.90062 0.040265
4 0.052795 4 0.66874 0.72050 0.036551
5 0.023810 7 0.47412 0.49896 0.030957
6 0.017598 9 0.42650 0.53416 0.031942
7 0.014493 12 0.36853 0.51553 0.031426
8 0.010000 14 0.33954 0.48654 0.030599
>
> #交叉矩阵评估模型
> pre1<-predict(Gary1,newdata=churnTrain,type='class')
> tab<-table(pre1,churnTrain$churn)
> tab pre1 yes no
yes 354 35
no 129 2815
>
> #评估模型(预测)的正确率
> sum(diag(tab))/sum(tab)
[1] 0.9507951
C4.5创建决策树模型:
读取数据,加载party包
data(churn) library(RWeka)
使用rpart包J48()创建决策树模型
> Gary<-J48(churn~.,data=churnTrain) > tab<-table(churnTrain$churn,predict(Gary))
> tab yes no
yes 359 124
no 24 2826 > #评估模型(预测)的正确率
> sum(diag(tab))/sum(tab)
[1] 0.9555956
C5.0创建决策树模型:
C5.0算法则是C4.5算法的商业版本,较C4.5算法提高了运算效率,它加入了boosting算法,使该算法更加智能化
解释略
> data(churn)
> treeModel <- C5.0(x = churnTrain[, -20], y = churnTrain$churn)
>
> ruleModel <- C5.0(churn ~ ., data = churnTrain, rules = TRUE)
>
> tab<-table(churnTest$churn,predict(ruleModel,churnTest))
> tab yes no
yes 149 75
no 15 1428
> #评估模型(预测)的正确率
> sum(diag(tab))/sum(tab)
[1] 0.9460108
diag(x = 1, nrow, ncol)
diag(x) <- value
解析:
x:一个矩阵,向量或一维数组,或不填写。
nrow, ncol:可选 行列。
value :对角线的值,可以是一个值或一个向量
R_针对churn数据用id3、cart、C4.5和C5.0创建决策树模型进行判断哪种模型更合适的更多相关文章
- 决策树之ID3、C4.5、C5.0等五大算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- C5.0决策树之ID3.C4.5.C5.0算法 ...
- 决策树之ID3、C4.5
决策树是一种类似于流程图的树结构,其中,每个内部节点(非树叶节点)表示一个属性上的测试,每个分枝代表该测试的一个输出,而每个树叶节点(或终端节点存放一个类标号).树的最顶层节点是根节点.下图是一个典型 ...
- 小啃机器学习(1)-----ID3和C4.5决策树
第一部分:简介 ID3和C4.5算法都是被Quinlan提出的,用于分类模型,也被叫做决策树.我们给一组数据,每一行数据都含有相同的结构,包含了一系列的attribute/value对. 其中一个属性 ...
- 机器学习总结(八)决策树ID3,C4.5算法,CART算法
本文主要总结决策树中的ID3,C4.5和CART算法,各种算法的特点,并对比了各种算法的不同点. 决策树:是一种基本的分类和回归方法.在分类问题中,是基于特征对实例进行分类.既可以认为是if-then ...
- 决策树(ID3、C4.5、CART)
ID3决策树 ID3决策树分类的根据是样本集分类前后的信息增益. 假设我们有一个样本集,里面每个样本都有自己的分类结果. 而信息熵可以理解为:“样本集中分类结果的平均不确定性”,俗称信息的纯度. 即熵 ...
- 2. 决策树(Decision Tree)-ID3、C4.5、CART比较
1. 决策树(Decision Tree)-决策树原理 2. 决策树(Decision Tree)-ID3.C4.5.CART比较 1. 前言 上文决策树(Decision Tree)1-决策树原理介 ...
- 决策树(上)-ID3、C4.5、CART
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读,方可全面了解决策树): 1.https://zhuanlan.zhihu.com/p/85731206 2.https://zhuanla ...
- ID3、C4.5、CART、RandomForest的原理
决策树意义: 分类决策树模型是表示基于特征对实例进行分类的树形结构.决策树可以转换为一个if_then规则的集合,也可以看作是定义在特征空间划分上的类的条件概率分布. 它着眼于从一组无次序.无规则的样 ...
- ID3、C4.5、CART决策树介绍
决策树是一类常见的机器学习方法,它可以实现分类和回归任务.决策树同时也是随机森林的基本组成部分,后者是现今最强大的机器学习算法之一. 1. 简单了解决策树 举个例子,我们要对”这是好瓜吗?”这样的问题 ...
随机推荐
- python之成像库pillow
目录 python之成像库pillow 官方文档 图像模块(Image.Image) Image模块的功能 Image.new(mode,size,color): Image.open(file,mo ...
- 3d旋转焦点图
在线演示 本地下载
- BM求线性递推模板(杜教版)
BM求线性递推模板(杜教版) BM求线性递推是最近了解到的一个黑科技 如果一个数列.其能够通过线性递推而来 例如使用矩阵快速幂优化的 DP 大概都可以丢进去 则使用 BM 即可得到任意 N 项的数列元 ...
- 最新省市区地区数据sql版本(2019年1月)
版本 统计标准2017版 来源 http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/ 建表 CREATE TABLE `area` ( `id` varc ...
- js制作留言板
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- delegate作为操作符的使用
lambda表达式的出现基本上取代了delegate操作符的使用 public MainWindow() { InitializeComponent(); this.button1.Click += ...
- Git复习(十二)之命令专场
命令 git init -> 初始化一个git仓库 git clone -> 克隆一个本地库 git pull -> 拉取服务器最新代码 git fetch –p -> 强行拉 ...
- wex5打包详解
1.模式选择 模式一:主要针对是简单的运用,进行智能更新,也就是说即使服务器更新了,客户端也不会立即更新,不适合产品类型的APP. 模式二:服务器资源更新了,客户端也会立即更新. 模式三:调试模式. ...
- 06 Django之模型层---多表操作
一 创建模型 表和表之间的关系 一对一.多对一.多对多 ,用book表和publish表自己来想想关系,想想里面的操作,加外键约束和不加外键约束的区别,一对一的外键约束是在一对多的约束上加上唯一约束. ...
- Redis分布式之前篇
第一篇:初识Redis 一.Redis是什么? Redis 是一个开源(BSD许可)的,使用ANSI C语言编写的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 它支持多种类型的数据 ...