python基础:multiprocessing的使用
不同于C++或Java的多线程,python中是使用多进程来解决多项任务并发以提高效率的问题,依靠的是充分使用多核CPU的资源。这里是介绍mulitiprocessing的官方文档:https://docs.python.org/2/library/multiprocessing.html
一、多进程并发效果演示
- <span style="font-size:14px;">import multiprocessing
- import time
- def worker_1(ts):
- print "run worker_1"
- time.sleep(ts)
- print "end worker_1"
- def worker_2(ts):
- print "run worker_2"
- time.sleep(ts)
- print "end worker_2"
- def worker_3(ts):
- print "run worker_3"
- time.sleep(ts)
- print "end worker_3"
- def worker_4(ts):
- print 'run worker_4'
- time.sleep(ts)
- print 'end worker_4'
- def worker_5(ts):
- print 'run worker_5'
- time.sleep(ts)
- print 'end worker_5'
- if __name__ == "__main__":
- proc1 = multiprocessing.Process(target = worker_1, args = (1,))
- proc2 = multiprocessing.Process(target = worker_2, args = (2,))
- proc3 = multiprocessing.Process(target = worker_3, args = (3,))
- proc4 = multiprocessing.Process(target = worker_4, args = (3,))
- proc5 = multiprocessing.Process(target = worker_5, args = (3,))
- proc1.start()
- proc2.start()
- proc3.start()
- proc4.start()
- proc5.start()
- print("The number of CPU is:" + str(multiprocessing.cpu_count()))
- for p in multiprocessing.active_children():
- print("child p.name:" + p.name + "\tp.id" + str(p.pid))
- print "main_process finished."</span>
运行结果:
分析:
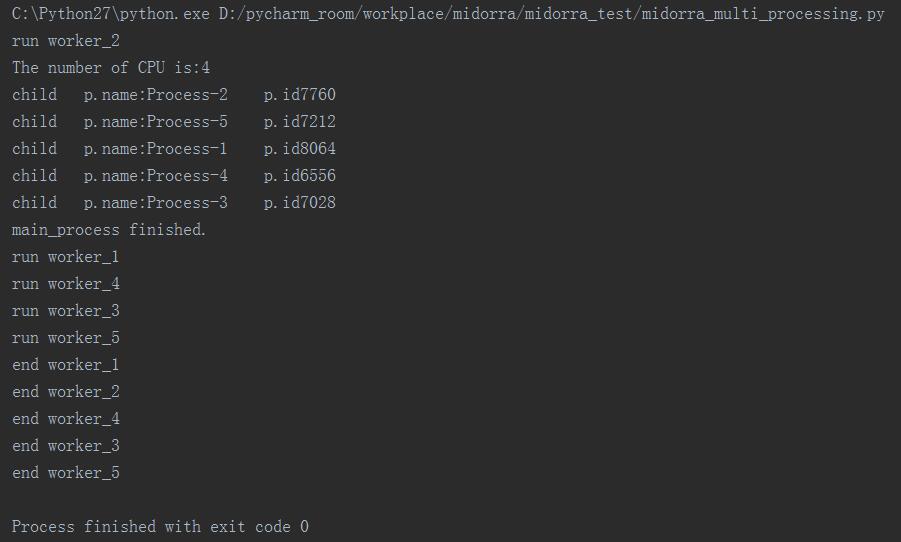
通过上面的运行结果可以看到
(1)在主进程中start启动的5个进程彼此之间以及和主进程均存在并发关系,像上面worker_2在主进程的输出前输出,而且worker1、4、3、5分别无序输出‘run’就是并发最好的说明
(2)由于worker_1和worker_2分别sleep1秒和2秒,所以在主进程结束后依次结束,而worker_3、worker_4、worker_5都是sleep相同的3秒,最后它们三个进程无序输出(end4、end3、end5)更好的演示了并发效果
二、将进程写成class的范例
- <span style="font-size:14px;">import multiprocessing
- import time
- class CounterProcess(multiprocessing.Process):
- def __init__(self, ts, arr):
- multiprocessing.Process.__init__(self)
- self.ts = ts
- self.arr = arr
- def run(self):
- time.sleep(self.ts)
- sum = 0
- for i in self.arr:
- sum += i
- print 'sum = ' + str(sum)
- c_time_cur_loc = time.localtime()
- counter_timestamp = '%04d%02d%02d_%02d%02d%02d' % ( \
- c_time_cur_loc.tm_year, \
- c_time_cur_loc.tm_mon, \
- c_time_cur_loc.tm_mday, \
- c_time_cur_loc.tm_hour, \
- c_time_cur_loc.tm_min, \
- c_time_cur_loc.tm_sec \
- )
- print 'counter_process finished at ' + str(counter_timestamp)
- if __name__ == '__main__':
- arr = [1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
- ts = 2
- counter = CounterProcess(ts, arr)
- counter.start()
- for i in arr:
- print 'arr.member = ' + str(i)
- m_time_cur_loc = time.localtime()
- main_timestamp = '%04d%02d%02d_%02d%02d%02d' % ( \
- m_time_cur_loc.tm_year, \
- m_time_cur_loc.tm_mon, \
- m_time_cur_loc.tm_mday, \
- m_time_cur_loc.tm_hour, \
- m_time_cur_loc.tm_min, \
- m_time_cur_loc.tm_sec \
- )
- print 'main_process finished at ' + str(main_timestamp)</span>
运行结果:
分析:
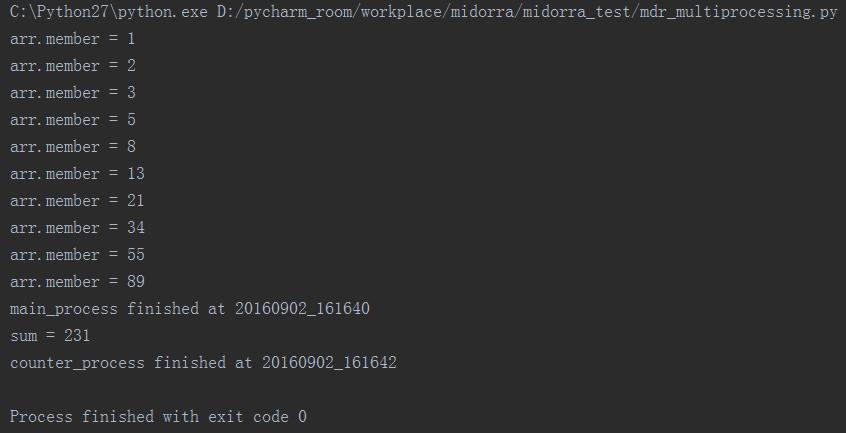
这个范例是在主进程中一次输出数组中的斐波那契数列,然后由一个进程counter去计算该数列的累加和。
其中在进程初始化的时候设置了让该进程sleep两秒,然后在输出的结果中我们也可以看到主进程首先结束,然后在两秒后counter进程完成累加和的运算并且结束(累加和应该不到1ms,直接可以忽略,所以两个进程结束的时间差恰好就是我们预设的2秒)
三、daemon和join
(1)daemon:daemon的作用是控制主线程与其他线程的关系,默认情况下daemon=False,也就是当主进程关闭后,在主进程中start出来的进程会继续正常运行,而如果手动设置daemon=True,那么在主进程结束后,从主进程中start的所有其他进程进程也会立刻随着主进程的结束而结束。
- <span style="font-size:14px;">import multiprocessing
- import time
- class CounterProcess(multiprocessing.Process):
- def __init__(self, ts, arr):
- multiprocessing.Process.__init__(self)
- self.ts = ts
- self.arr = arr
- def run(self):
- time.sleep(self.ts)
- sum = 0
- for i in self.arr:
- sum += i
- print 'sum = ' + str(sum)
- c_time_cur_loc = time.localtime(time.time())
- counter_timestamp = '%04d%02d%02d_%02d%02d%02d' % ( \
- c_time_cur_loc.tm_year, \
- c_time_cur_loc.tm_mon, \
- c_time_cur_loc.tm_mday, \
- c_time_cur_loc.tm_hour, \
- c_time_cur_loc.tm_min, \
- c_time_cur_loc.tm_sec \
- )
- print 'counter_process finished at ' + str(counter_timestamp)
- if __name__ == '__main__':
- arr = [1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
- ts = 2
- counter = CounterProcess(ts, arr)
- counter.daemon = True
- counter.start()
- #counter.join()
- for i in arr:
- print 'arr.member = ' + str(i)
- m_time_cur_loc = time.localtime(time.time())
- main_timestamp = '%04d%02d%02d_%02d%02d%02d' % ( \
- m_time_cur_loc.tm_year, \
- m_time_cur_loc.tm_mon, \
- m_time_cur_loc.tm_mday, \
- m_time_cur_loc.tm_hour, \
- m_time_cur_loc.tm_min, \
- m_time_cur_loc.tm_sec \
- )
- print 'main_process finished at ' + str(main_timestamp)</span>
运行结果:
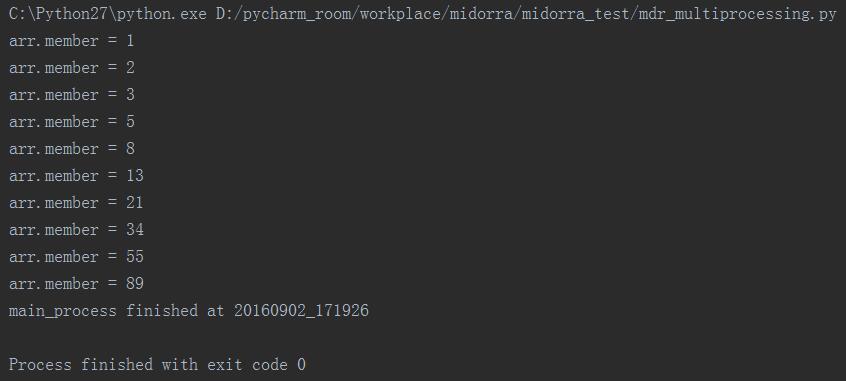
分析:
可以看到,设置了daemon=True后,并没有执行完正在sleep中的counter_process进程,而是随着main_process的结束而终止了。
(2)join:join的作用是阻塞当前进程,直到调用join的那个进程执行完它的运算,回到当前进程下继续执行当前进程。
- <span style="font-size:14px;">import multiprocessing
- import time
- class CounterProcess(multiprocessing.Process):
- def __init__(self, ts, arr):
- multiprocessing.Process.__init__(self)
- self.ts = ts
- self.arr = arr
- def run(self):
- time.sleep(self.ts)
- sum = 0
- for i in self.arr:
- sum += i
- print 'sum = ' + str(sum)
- c_time_cur_loc = time.localtime(time.time())
- counter_timestamp = '%04d%02d%02d_%02d%02d%02d' % ( \
- c_time_cur_loc.tm_year, \
- c_time_cur_loc.tm_mon, \
- c_time_cur_loc.tm_mday, \
- c_time_cur_loc.tm_hour, \
- c_time_cur_loc.tm_min, \
- c_time_cur_loc.tm_sec \
- )
- print 'counter_process finished at ' + str(counter_timestamp)
- if __name__ == '__main__':
- ms_time_cur_loc = time.localtime(time.time())
- main_s_timestamp = '%04d%02d%02d_%02d%02d%02d' % ( \
- ms_time_cur_loc.tm_year, \
- ms_time_cur_loc.tm_mon, \
- ms_time_cur_loc.tm_mday, \
- ms_time_cur_loc.tm_hour, \
- ms_time_cur_loc.tm_min, \
- ms_time_cur_loc.tm_sec \
- )
- print 'main_process started at ' + str(main_s_timestamp)
- arr = [1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
- ts = 2
- counter = CounterProcess(ts, arr)
- counter.daemon = True
- counter.start()
- counter.join()
- for i in arr:
- print 'arr.member = ' + str(i)
- me_time_cur_loc = time.localtime(time.time())
- main_e_timestamp = '%04d%02d%02d_%02d%02d%02d' % ( \
- me_time_cur_loc.tm_year, \
- me_time_cur_loc.tm_mon, \
- me_time_cur_loc.tm_mday, \
- me_time_cur_loc.tm_hour, \
- me_time_cur_loc.tm_min, \
- me_time_cur_loc.tm_sec \
- )
- print 'main_process finished at ' + str(main_e_timestamp)</span>
运行结果:
分析:
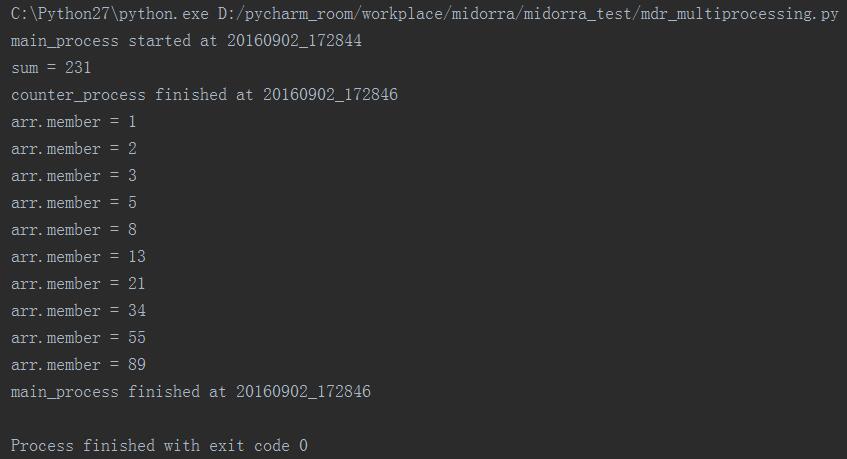
在本次执行的时候加入了主进程开始执行的时间,然后可以发现当在主进程中join了counter_process之后,就阻塞了当前正在运行的主进程,花了两秒时间完成了counter_process的运算,然后才继续进行main_process的运算,直到结束。
四、Lock
既然是并发,一定就会有lock来控制多进程访问共用资源的情况,python中锁有两种状态:被锁(locked)和没有被锁(unlocked),拥有acquire( )和release( )两种方法,并且遵循以下的规则:
1、unlocked的锁 + acquire( ) = locked的锁
2、locked的锁 + acquire( ) = 调用acquire( )的进程将进入阻塞,直到其他进程调用release( )方法释放锁
3、unlocked的锁 + release( ) = 抛出RuntimeError异常
4、locked的锁 + release( ) = 将该锁的状态由locked转变成unlocked
感谢yoyzhou提供了一张很清晰的acquire( )和release( )的逻辑图,引用如下所示:
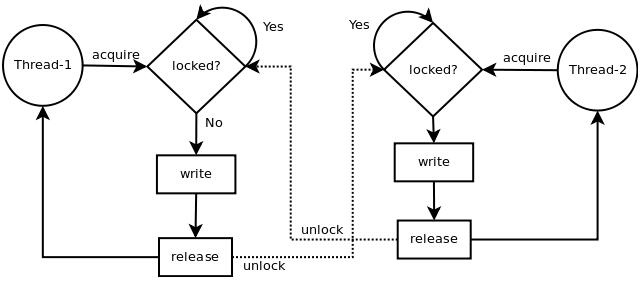
另外:锁(Lock)可以和"with"语句一起使用,锁可以作为上下文管理器(context manager)。
使用with的好处是:当程序执行到"with"语句的时候,acquire( )方法将被调用,当程序执行完"with"语句时,release( )方法将被调用。这样我们就不用显示的调用acqiure( )和release( )方法,而是由with语句根据上下文来管理锁的获取和释放。
- <span style="font-size:14px;">import multiprocessing
- file_strA = 'file_writerA is working'
- file_strB = 'file_writerB is working'
- def file_writerA(lock, file_path):
- print 'file_writerA process started already.'
- with lock:
- fs = open(file_path, 'a+')
- repeat_times = 1000000
- print 'file_writerA start to write.'
- while repeat_times >= 1:
- fs.write(file_strA + '\n')
- repeat_times -= 1
- print 'file_writerA finished writing.'
- fs.close()
- def file_writerB(lock, file_path):
- print 'file_writerB process started already.'
- lock.acquire()
- try:
- fs = open(file_path, 'a+')
- repeat_times = 1000000
- print 'file_writerB start to write.'
- while repeat_times >= 1:
- fs.write(file_strB + '\n')
- repeat_times -= 1
- print 'file_writerB finished writing.'
- fs.close()
- finally:
- lock.release()
- if __name__ == "__main__":
- mdr_lock = multiprocessing.Lock()
- file_path = "E:\\file.txt"
- proc_writerA = multiprocessing.Process(target=file_writerA, args=(mdr_lock, file_path))
- proc_writerB = multiprocessing.Process(target=file_writerB, args=(mdr_lock, file_path))
- proc_writerA.start()
- proc_writerB.start()
- print "main_process is finished."</span>
运行结果:
分析:
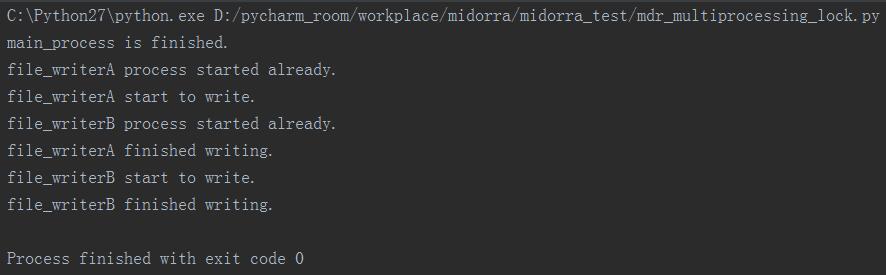
上面程序中分别使用手动acquire( )/release( )和with两种写法控制两个进程去写相同的文件。
通过上面的运行结果可以看到,当file_writerA process启动以后,锁住了文件,此时file_writerB process也启动了,但是由于A没有完成写文件,所以B被阻塞,当A完成了写操作以后,B才开始继续执行自己的写文件命令。
另外需要强调一点,指定相同target的不同进程仍然是不同进程,也会被acquire阻塞住的,如下面实验所示。
- <span style="font-size:14px;">import multiprocessing
- import threading
- file_strA = 'file_writerA is working'
- file_strB = 'file_writerB is working'
- def file_writerA(name, lock, file_path):
- print 'file_writer process ' + name + ' started already.'
- print 'inname = ' + multiprocessing.current_process().name
- with lock:
- fs = open(file_path, 'a+')
- repeat_times = 1000000
- print 'file_writer ' + name + ' start to write.'
- while repeat_times >= 1:
- fs.write(file_strA + '\n')
- repeat_times -= 1
- print 'file_writer ' + name + ' finished writing.'
- fs.close()
- def file_writerB(name, lock, file_path):
- print 'file_writer process ' + name + ' started already.'
- print 'inname = ' + multiprocessing.current_process().name
- lock.acquire()
- try:
- fs = open(file_path, 'a+')
- repeat_times = 1000000
- print 'file_writer ' + name + ' start to write.'
- while repeat_times >= 1:
- fs.write(file_strB + '\n')
- repeat_times -= 1
- print 'file_writer ' + name + ' finished writing.'
- fs.close()
- finally:
- lock.release()
- if __name__ == "__main__":
- mdr_lock = multiprocessing.Lock()
- file_path = "E:\\file.txt"
- proc_writerA1 = multiprocessing.Process(target=file_writerA, args=('A1', mdr_lock, file_path,))
- proc_writerA2 = multiprocessing.Process(target=file_writerA, args=('A2', mdr_lock, file_path,))
- proc_writerB = multiprocessing.Process(target=file_writerB, args=('B', mdr_lock, file_path,))
- proc_writerA1.start()
- proc_writerA2.start()
- proc_writerB.start()
- print 'main_process is finished.'
- </span>
运行结果:
分析:
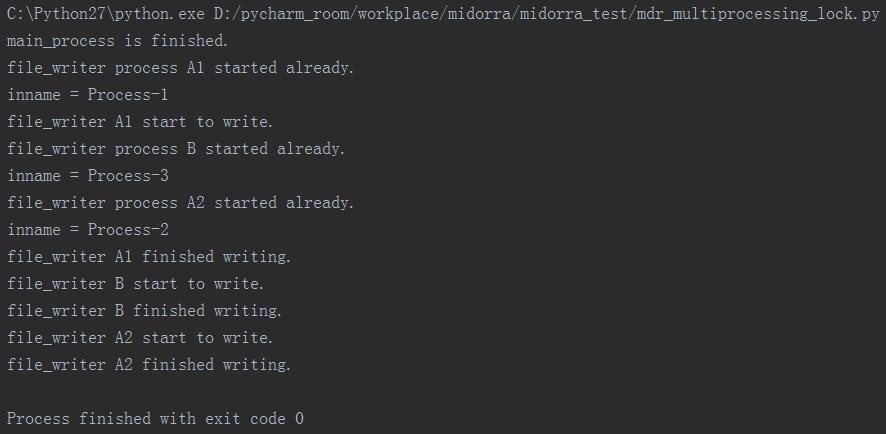
上面的实验可以看到,proc_writerA1和pro_writerA2都是指定targer=file_writerA,但是从运行结果上我们看到A2被阻塞到A1和B都执行完毕才开始执行自己的写操作。
五、RLock
RLock是可重入锁(reetrant lock),和Lock对比:
(1)相同之处:当某一个进程lock.acquire( )后,直到其释放前,其他所有acquire相同lock的进程将被阻塞(包括自身进程)。
(2)区别之处:是同一个进程能够不被阻塞的多次调用rlock.acquire( ),同样需要相等次数的release( )才能释放后,其他进程才可以结束acquire的阻塞。
参考文献:
http://www.cnblogs.com/kaituorensheng/p/4445418.html
http://www.cnblogs.com/lipijin/p/3709903.html
http://yoyzhou.github.io/blog/2013/02/28/python-threads-synchronization-locks/
python基础:multiprocessing的使用的更多相关文章
- python基础教程
转自:http://www.cnblogs.com/vamei/archive/2012/09/13/2682778.html Python快速教程 作者:Vamei 出处:http://www.cn ...
- 周末班:Python基础之并发编程
进程 相关概念 进程 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础.在早期面向进程设计的计算机结构中,进程是程序的基本 ...
- 面试题-python基础
一.Python基础 1.什么是python?使用python有什么好处? python是一种编程语言,它有对象.模块.线程.异常处理和自动内存管理.它简洁,简单.方便.容易扩展.有许多自带的数据结果 ...
- python基础系列教程——Python3.x标准模块库目录
python基础系列教程——Python3.x标准模块库目录 文本 string:通用字符串操作 re:正则表达式操作 difflib:差异计算工具 textwrap:文本填充 unicodedata ...
- Python 基础之 线程与进程
Python 基础之 线程与进程 在前面已经接触过了,socket编程的基础知识,也通过socketserver 模块实现了并发,也就是多个客户端可以给服务器端发送消息,那接下来还有个问题,如何用多线 ...
- python基础31[常用模块介绍]
python基础31[常用模块介绍] python除了关键字(keywords)和内置的类型和函数(builtins),更多的功能是通过libraries(即modules)来提供的. 常用的li ...
- python基础全部知识点整理,超级全(20万字+)
目录 Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https:// ...
- python之最强王者(2)——python基础语法
背景介绍:由于本人一直做java开发,也是从txt开始写hello,world,使用javac命令编译,一直到使用myeclipse,其中的道理和辛酸都懂(请容许我擦干眼角的泪水),所以对于pytho ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
- Python小白的发展之路之Python基础(一)
Python基础部分1: 1.Python简介 2.Python 2 or 3,两者的主要区别 3.Python解释器 4.安装Python 5.第一个Python程序 Hello World 6.P ...
随机推荐
- excle 文件的导入和导出
//excle 文件导出 public function excel(){ try{ include(BASE_PATH."Excel/PHPExcel.php"); // ech ...
- CSS布局方式
1.内边距 padding <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- 005-监控项item详解,手动创建item实例
模板里的监控项都可以用 zabbix-get 命令执行 来获取相应的值,方法如下: [root@linux-node2 ~]# zabbix_get -s 192.168.1.230 -k agent ...
- Linux sed神器
sed -i -c -e '/^#/d'去掉注释行 sed -i -c -e '/^$/d'去掉空行 sed -i -c -e '/^$/d;/^#/'同时去掉空行和注释行 sed -i 's/^/H ...
- python中使用schedule模块定时执行任务
python中有一个轻量级的定时任务调度的库:schedule.他可以完成每分钟,每小时,每天,周几,特定日期的定时任务.因此十分方便我们执行一些轻量级的定时任务. 代码如下: import sche ...
- 关于 html button 点击刷新页面的问题
如果不想点击button 刷新页面的话,需要加个属性 type="button" 如下: <button class="layui-btn" type ...
- axios获取响应头
[转载] 来源:https://segmentfault.com/a/1190000009125333 在用 axios 获取 respose headers 时候获取到的只有的 Object { c ...
- JAVA笔记14-线程
一.概念 线程:是一个程序里面不同的执行路径,每一个分支都叫线程.到现在为止我们所讲的程序分支只有一个,即main方法,称作主线程. 进程:class文件,exe文件.程序的执行过程:程序放入代码区( ...
- postman+newman+jenkins 接口自动化
一:Jenkins安装: jenkins是一款跨平台的持续集成和持续交付.基于Java开发的开源软件,提供任务构建.持续集成监控的功能,可以使开发测试人员更方便的构建软件项目, 我安装是安装程序模式, ...
- priority_queue与multiset
感觉c++最有用的stl是bitset.堆(优先队列)和平衡树,其他的都可以手打 这里主要讲一下堆和平衡树的基本用法和区别所在 priority_queue 堆/优先队列 定义: priority_q ...