flume复习(一)
关于flume官方文档介绍可以去:http://flume.apache.org/看看。接下来就介绍一下关于我个人对flume的理解
一、flume介绍:
1.flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统并且可以进行在线分析。
2.支持在日志系统中定制各类数据发送方,用于收集数据,同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
3.flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
4.flume名词解释。
Client:Client生产数据,运行在一个独立的线程。
Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
Flow: Event从源点到达目的点的迁移的抽象。
Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。)
Source: 数据收集组件。(source从Client收集数据,传递给Channel)
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
二、flume核心结构
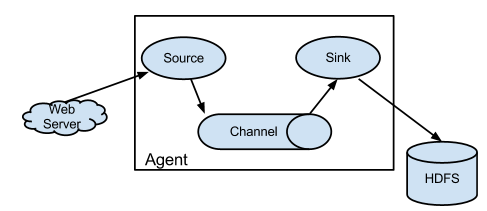
1.Agent:flume运行的核心是agent,运行的最小单位也是agent,一个flume就是一个JVM,他是一个完整的数据收集工具,包含有3个核心组件,source,channel和sink。一个时间Event可以从一个方向流向另一个方向。如下图所示:
2.source:数据的收集端。负责将数据捕获后进行特殊的格式化。source将数据封装到事件(Event)里,然后推入到Channel中,Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
3.channel:接Source和Sink的组件。数据流的临时存放地,对source中的数据进行缓冲,直到sink将其消费掉。
4.sink:从channel提取数据存放到中央化存储(hadoop/hbase)
三、flume命令和配置
1.flume安装
1.下载
2.tar
3.环境变量
4.验证flume是否成功
$>flume-ng version //next generation.下一代.
2.配置flume []
命名agent上的组件
a1.sources=r1; //所有的源
a1.sinks=k1; //所有的sink
a1.channels=c1; //所有的channel
描述源的配置
a1.sources.r1.type=netcat; //源的类型是瑞士军刀
a1.sources.r1.bind=localhost; //绑定本机
a1.sources.r1.port=44444; //绑定44444端口
描述sink
a1.sinks.k1.type=loggger; //将通道中提取的数据存储到日志中去
使用在内存中进行缓冲的通道
a1.channels.c1.type=memory; //
a1.channels.c1.capacity=1000; //内存中可以存储1000个事件
a1.channels.c1.transactionCapacity = 100; //
把源和通道以及sink和通道进行绑定
a1.sources.r1.channels=c1; //一个源可以有多个通道
a1.sinks.k1.channel=c1; //一个sink只能有一个通道
3.运行flume
1)启动flume agent
$> bin/flume-ng agent -f /soft/flume/conf/hello.conf -n a1 -Dflume.root.logger=INFO,console
开启这个端口来接收来自8888端口的数据
2)打开netcat,nc localhost 8888
四、测试source
1.配置seq压力源(源测试)
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type=seq
a1.sources.r1.totalEvents=1000
a1.sinks.k1.type=logger
a1.channels.c1.type=memory
a1.sources.r1.channels=c1
2.批量收集文件
监控一个文件夹,静态文件。在收集完成之后会重命名为一个新的文件.compeleted
1.配置文件[spool-r.conf]
a1.sources=r1
a1.channels=c1;
a1.sinks=k1
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/home/centos/spool
a1.sources.r1.fileHeader=true
a1.sinks.k1.type=loger
a1.channels.c1.type=memory
a1.sources.c1.channels=c1;
a1.sinks.c1.channel=c1;
2.创建目录
$>mkdir ~/spool
3.启动flume
$>bin/flume-ng agent -f /soft/flume/conf/spooldir-r.conf -n a1 -Dflume.root.logger=INFO,console
3.实时日志收集exec(对文件进行实时监控)
1.配置文件[exec-r.conf]
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /home/centos/test.txt
a1.sinks.k1.type=logger
a1.channels.c1.type=memory
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2.启动flume
$>flume-ng agent -f /soft/flume/conf/exec-r.conf -n a1 -Dflume.root.logger=INFO,console
3.在/home/centos下写文件
$>touch test.txt
$>echo hello world >> test.txt
五、.测试sink
1.hdfs
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 8888
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/centos/flume/%y-%m-%d/%H/%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
#是否舍弃,每十分钟会产生一个新的目录
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = day
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.rollInterval=10
a1.sinks.k1.hdfs.rollSize=30
a1.sinks.k1.hdfs.rollCount=3
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.hbase
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=8888
a1.sinks.k1.type=hbase
a1.sinks.k1.table=ns1:t2
a1.sinks.k1.columnFamily=f1
a1.sinks.k1.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer
a1.channels.c1.types=memory
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
3.从source到channels的过程
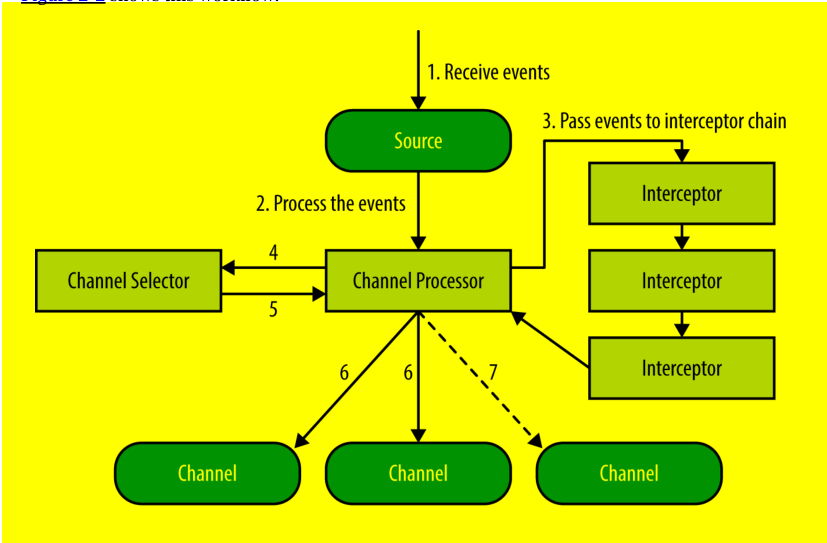
数据从外部进入到源source中来,
4.使用avroSource和avroSink实现越点(agent)代理
--------------------------------------------
1.创建配置文件
#a1
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=netcat
a1.sources.r1.bind=localhost
a1.sources.r1.port=8888
a1.sinks.k1.type=avro
a1.sinks.k1.hostname=localhost
a1.sinks.k1.port=9999
a1.channels.c1.type=memory
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
#a2
a1.sources=r2
a1.sinks=k2
a1.channels=c2
a1.sources.r2.type=avro
a1.sources.r2.bind=localhost
a1.sources.r2.port=9999
a2.sinks.k2.type=logger
a2.channels.c2.type=memory
a2.sources.r2.channels=c2
a2.sinks.k2.channel=c2
2.启动a2:flume-ng agent -f /soft/flume/conf/avro_hop.conf -n a2 -Dflume.root.logger=INFO,console
3.验证a2是否开启
$>netstat -anop | grep 9999
4.开启a1.flume-ng agent -f /soft/flume/conf/avro_hop.conf -n a1
验证是否开启:$>netstat -anop | grep 8888
5.channels
--------------------------------------------------------
1.memory
2.FileChannel
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.channels=c1
a1.channels.c1.type=file
a1.channels.c1.checkpointDir=/home/centos/flume/fc_check
a1.channels.c1.dataDirs=/home/centos/flume/fc_data
flume复习(一)的更多相关文章
- flume复习(二)
一.简介:flume是一种分布式.可靠且可用的系统,能够用于有效的从不同的源收集.聚合和移动大量的日志数据到集中式数据存储.它具有基于流数据的简单灵活的架构,它具有健壮的可靠性机制和许多故障转移和恢复 ...
- kafka复习(1)
一:flume复习 0.JMS(java message service )java消息服务 ----------------------------------------------------- ...
- 大数据入门第二十四天——SparkStreaming(二)与flume、kafka整合
前一篇中数据源采用的是从一个socket中拿数据,有点属于“旁门左道”,正经的是从kafka等消息队列中拿数据! 主要支持的source,由官网得知如下: 获取数据的形式包括推送push和拉取pull ...
- [CDH] Acquire data: Flume and Kafka
Flume 基本概念 一.是什么 Ref: http://flume.apache.org/ 数据源获取:Flume.Google Refine.Needlebase.ScraperWiki.Bloo ...
- Hadoop期末复习
Hadoop期末复习 选择题 以下选项中,哪个程序负责HDFS数据存储. B A.NameNode B.DataNode C.Secondary NameNode D.ResourceManager ...
- iOS总结_UI层自我复习总结
UI层复习笔记 在main文件中,UIApplicationMain函数一共做了三件事 根据第三个参数创建了一个应用程序对象 默认写nil,即创建的是UIApplication类型的对象,此对象看成是 ...
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- vuex复习方案
这次复习vuex,发现官方vuex2.0的文档写得太简略了,有些看不懂了.然后看了看1.0的文档,感觉很不错.那以后需要复习的话,还是先看1.0的文档吧.
- 我的操作系统复习——I/O控制和系统调用
上篇博客介绍了存储器管理的相关知识——我的操作系统复习——存储器管理,本篇讲设备管理中的I/O控制方式和操作系统中的系统调用. 一.I/O控制方式 I/O就是输入输出,I/O设备指的是输入输出设备和存 ...
随机推荐
- IDEA下从零开始搭建SpringBoot工程
SpringBoot的具体介绍可以参看其他网上介绍,这里就不多说了,就这几天的学习,个人理解,简而言之: (1)它是Spring的升级版,Spring容器能做到的事情,它都能做到,而且更简便,从配置形 ...
- java 后台封装json数据学习总结
一.数据封装 1. List集合转换成json代码 List list = new ArrayList(); list.add( "first" ); list.add( &quo ...
- JS 类和继承
function User(name, pass) { this.name = name this.pass = pass } User.prototype.showName = function ( ...
- 第七周总结&第五次实验报告
学习总结 这周我们加深了对抽象类与接口的学习,获得的知识点也比上周多了许多,抽象类与接口很相似,就比如别人还没有做完的是交给你来做,而他那些样式都做好了,你只需要完善即可 但也有不同点. 区别点 抽象 ...
- Linux如何安装卸载软件
Linux 中如何卸载已安装的软件. Linux软件的安装和卸载一直是困扰许多新用户的难题.在Windows中,我们可以使用软件自带的安装卸载程序或在控制面板中的“添加/删除程 序” 来实现.与其相类 ...
- C# 判断两条直线是否相交
直接上代码,过程不复杂 /// <summary> /// 判断两条线是否相交 /// </summary> /// <param name="a"& ...
- PHP 设置Cookie值注意项
Cookie 中的value值只能添加设置为String类型的字符串数据,但我们需要添加如数组,json串等其他类型的数据时,我们就要先对数据进行转换,再存入Cookie里了. Cookie 存储数组 ...
- Android 获取视频照片与刷新媒体库
1.获取本地所有视频 public void getLoadMedia() { Cursor cursor = UILApplication.instance.getApplicationContex ...
- 等式变换java解法
输入一个正整数X,在下面的等式左边的数字之间添加+号或者-号,使得等式成立. 1 2 3 4 5 6 7 8 9 = X 比如: 12-34+5-67+89 = 5 1+23+4-5+6-7-8-9 ...
- Linux配置全局jdk以及Tomcat服务器简单测试
Linux配置全局jdk 1.确保相应文件夹下有apache-tomcat和jdk的压缩文件 注意:jdk文件必须为适应Linux版本的文件 (如果已经有了相应文件,可以跳过以下第2-3个步骤) 2. ...