目标检测(三) Fast R-CNN
引言
之前学习了 R-CNN 和 SPPNet,这里做一下回顾和补充。
问题
R-CNN 需要对输入进行resize变换,在对大量 ROI 进行特征提取时,需要进行卷积计算,而且由于 ROI 存在重复区域,所以特征提取存在大量的重复计算;
SPPNet 针对 R-CNN 进行了改进,其利用空间金字塔池化来解决形变问题,并且只计算一次卷积得到特征图,ROI 的特征从该特征图的对应区域提取;
但是两者采用相同的计算框架,非常繁琐,特别是需要训练SVM分类器,拟合检测框回归,这两步不仅需要分步进行,使得模型变得复杂,而且需要缓存大量的训练样本,占用巨大的存储空间。
补充
ROI:region proposal,给定一张image找出objects可能存在的所有位置。输出大量objects可能位置的 bounding box,这些bbox称之为 region proposal 或者 regions of interest (ROI)。
mAP:mean Average Precision, 即各类别AP的平均值,AP表示PR曲线下面积
fast r-cnn 借鉴了 SPPNet 的思路,对 R-CNN 算法做了进一步的优化。
本文不仅阐述了 fast r-cnn 的原理,也对这三种算法进行比较分析。
Fast R-CNN详解
同样训练和测试分开讲解。
训练过程
1. 有监督预训练
基本同R-CNN
| 样本 | 来源 |
|---|---|
| 正样本 | ILSVRC 20XX |
| 负样本 | ILSVRC 20XX |
作者实验了3个网络:
第一个是 CaffeNet,实质上是 AlexNet,称之为S,即小模型;
第二个是 VGG_CNN_M_1024,其深度和AlexNet一样,但是更宽,称之为M,即中等模型;
第三个是 VGG16,称之为L,即大模型。
2. 特定样本下的微调
| 样本 | 比例 | 来源 |
|---|---|---|
| 正样本 | 25% | 与某类Ground Truth相交IoU∈[0.5,1]的候选框 |
| 负样本 | 75% | 与20类Ground Truth相交IoU中最大值∈[0.1,0.5)的候选框 |
在实际训练中,每个mini-batch包含2张图片和128个ROI,从正样本中挑选约25%,然后采用随机水平翻转进行数据增强;
从负样本中挑选约75% 【正负样本定义见上表】
与R-CNN的区别:
a. 使用了数据增强:50%概率水平翻转
b. R-CNN 使用与第一步相同的网络;Fast R-CNN 需要对第一步的网络做如下修改:
以VGG16为例
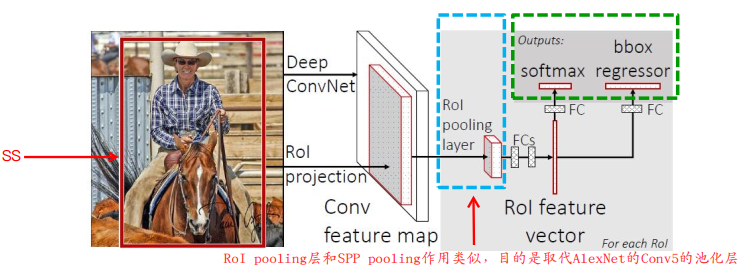
1. 将最后的 maxpooling 替换成 ROI池化层,目的是接受不同尺寸的输入;
2. 将最后一个全连接层和softmax层替换成两个并行层,第一个并行层是全连接层和softmax层,softmax有1000变为21,第二个并行层是全连接层和候选区域边框回归层;
3. 输入由 一系列图像 变成 一系列图像和这些图像的候选区域
图示如下
================ 扩展 ================
ROI Pooling
由于ROI的尺寸不一,无法直接输入全连接层,ROI pooling 就是把ROI的特征池化成一个固定大小的feature map。
具体操作为:假设ROI需要池化成 H x W 的feature map,H W 是个超参数,根据选用网络确定,假设ROI特征图尺寸为 h x w,那么池化野的大小约为 h/H x w/W,即把RIO特征图分成 H x W 份,然后对每一份进行maxpooling。
ROI 特征图有四个参数(r,c,h,w),r、c代表左上角坐标,h、w代表高和宽。
vs SPPNet
ROI的作用类似于SPPNet的SPP层

SPPNet进行多尺度学习,其mAP会高一点,不过计算量成倍增加,主要是全连接参数增多;
单尺度训练的效果更好。
哪些参数需要微调
SPPNet 论文中采用 ZFnet【AlexNet的改进版】这样的小网络,微调阶段仅对全连接层进行了微调,就足以保证较高的精度;
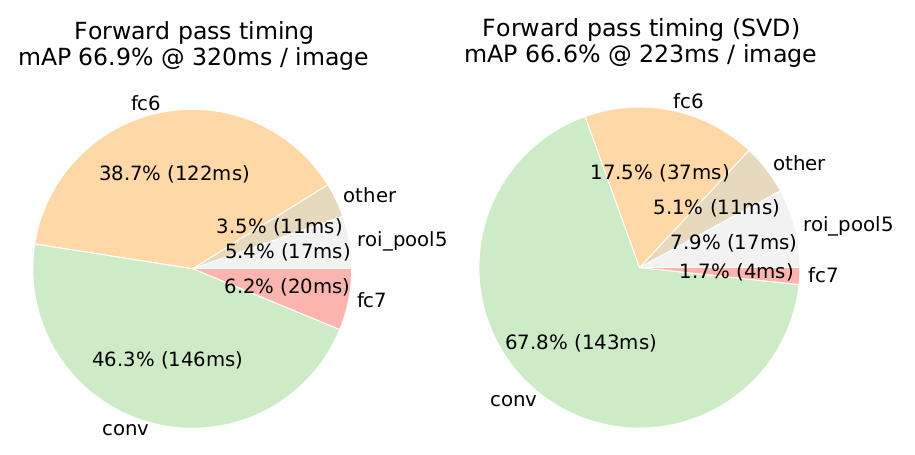
在 Fast R-CNN 中,作者试验了VGG16这样的大网络,若仅做全连接的微调,其mAP会从66.9%下降到61.4%,所以作者也对ROI池化层之前的卷积层进行了微调:
所有的卷积层都需要微调吗?作者进行了实验
对于VGG16,仅需要对conv3_1及以后的卷积进行微调,才使得 mAP、训练速度、训练时GPU占用显存三者得以权衡;
对于AlexNet、VGG_CNN_M_1024,需要从conv2往后微调。
为什么SPPNet 只能更新SPP之后的全连接层,而无法更新前面的卷积层
注意上面讲到SPPNet仅仅更新了全连接层,需要注意的是它只能更新全连接层,无法更新卷积层,为什么呢?
两种解释:
1. SPPNet 的微调阶段卷积计算是离线的,网络训练就像普通的神经网络一样,只是接受了计算好的特征,反向传播而已
2. SPP层求导几乎无法实现,参照下面的 ROI pooling 求导
SGD训练方式的优化
在R-CNN和SPPNet中采用 RoI-centric sampling,网络输入整张图像,然后从每张图像中获取一个ROI,这样在SGD的mini-batch中包含了不同图像的ROI,不同图像之间来回切换,无法共享卷积计算和内存,运算开销很大;
Fast R-CNN采用 image-centric sampling,mini-batch采用层次采样,首先选取N张图片,然后在每张图片选取R/N个ROIS,来自同一张图片的ROI在前向计算和反向传播中共享计算和内存,大大提高了效率。
据作者实验,当N=2,R=128时,这种方法能快64倍。
这种策略可能会减缓训练的收敛,因为同一张图像的ROI可能存在相关性,但实践中这种担忧并未发生。
SGD超参数
除了修改增加的层,原有的层参数已经通过预训练方式初始化;
用于分类的全连接层以均值为0、标准差为0.01的高斯分布初始化,用于回归的全连接层以均值为0、标准差为0.001的高斯分布初始化,偏置都初始化为0;
针对PASCAL VOC 2007和2012训练集,前30k次迭代全局 learning rate为0.001,每层权重学习率为1倍,偏置学习率为2倍,后10k次迭代全局学习率更新为0.0001;
动量momentum设置为0.9,权重衰减weight_decay设置为0.0005。
多任务损失
一个网络包含两个并行的全连接
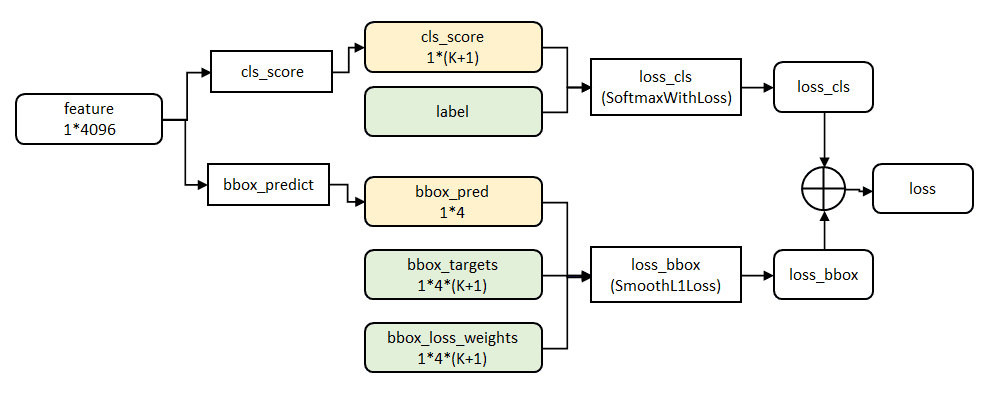
两个输出层
cls_score:图像识别层,输出为 每个ROI 在每个类别上的概率,长度为 k+1 的向量,p=(p0,…,pk)
bbox_predict:边框回归层,用来调整候选区域的标记位置,输出为 tu=(tx,ty,tw,th),x、y表示相对于object proposal 的平移,w、h表示log空间中相对于object proposal 的宽高。
k个类别,每个类别都有这样一个输出,故输出shape为 kx4。
假设u为ROI的真实类别,v为ROI的真实标记 ground truth,则
loss_cls 层评估分类代价,损失函数用 log 损失,即 Lcls(p,u)=-log(pu) 【R-CNN和SPPNet也采用这个损失函数】
loss_bbox 层评价回归损失代价,比较真实类别u对应的预测bbox标记 tu=(tx,ty,tw,th) 与 ground truth v=(vx,vy,vw,vh)之间的差距

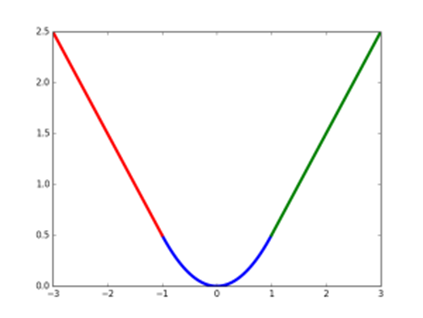
smoothL1曲线如图所示,相对于L2,其对异常值不敏感,可控制梯度的量级使得训练时不易跑飞,梯度爆炸
总的损失为
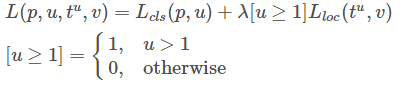
当u>1时为1
当u=0时为0,上式为 Lcls(p,u),表示只有分类误差,u=0是表示ROI为背景,此时只需识别为背景,无需进行bbox
λ控制分类损失和回归损失的权重,作者所用 λ=1

ROI pooling 的反向传播
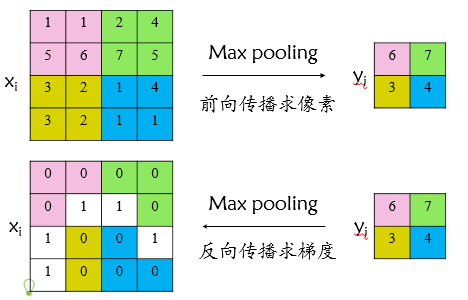
先看看普通 max pooling 如何求导
设xi为输入层节点,yj为输出层节点,损失函数为L,则L对xi的梯度为

判定函数 δ(i,j) 表示输入节点i是否被输出节点j选为最大值输出。
若被选中,则δ(i,j)=ture,其导数为

若没选中,则δ(i,j)=false,有两种可能,一是池化野没有扫描到该节点,二是扫描到了但非最大值,彼此没关系,导数为0
图示如下
ROI pooling 求导
与maxpooling不同的是,ROI有重合区域,设xi为输入层节点,yrj为输出层节点,表示第r个候选区域的第j个输出节点,一个输入层节点对应多个输出层节点。
如图,输入节点7为重合部分,对应两个候选区域

此时节点7的梯度为分别求梯度,相加
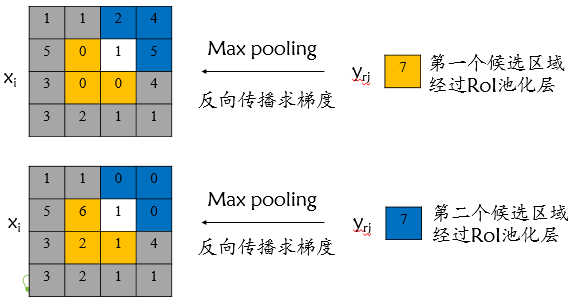
公式为


判定函数 [i=i*(r,j)] 表示 输入层节点i是否被第r个候选区域第j个输出层节点选为最大值输出。
测试过程

1. 输入任意size的图片,卷积池化,得到特征图
2. 在图片上采用 Selective Search 得到2000个建议框
3. 根据建议框在图片中的位置找到对应的特征图中的特征框,并将该特征框 通过 ROI pooling 得到固定大小的特征
4. 将第3步中的特征经过第一个全连接,得到新特征
5. 将第4步中的特征经由各自的全连接层,由SVD实现,得到两个输出:softmax分类得分,bbox边框回归
6. 利用边框得分分别对每一类物体进行非极大值抑制剔除重复建议框,最终得到每个类别中得分最高的边框
================ 扩展 ================
为什么要用SVD
图像分类任务中,卷积的时间要大于全连接的时间,而Fast RCNN 中,卷积的时间小于全连接,因为只卷积一次,全连接2000次。
假设全连接的输入为x,权重矩阵为W,尺寸为u x v,那全连接就是 y=Wx,
若将W进行SVD分解,取前t个特征值,即
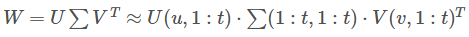
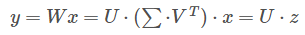
实验表明,SVD使得mAP下降0.3%,速度却提升30%
总结
一幅图概况Fast RCNN

之前讲到的RCNN、SPPNet、Fast RCNN 都是目标检测算法的过去时,都或多或少有问题,基本已经没人用了,所以不必过分探究所有细节,接下来要讲的方法是目标检测比较主流的方法,如 Faster RCNN, yolo等
参考资料:
https://blog.csdn.net/WoPawn/article/details/52463853
https://blog.csdn.net/ibunny/article/details/79397486
https://alvinzhu.xyz/2017/10/10/fast-r-cnn 论文翻译
https://blog.csdn.net/u014380165/article/details/72851319
https://github.com/rbgirshick/fast-rcnn
目标检测(三) Fast R-CNN的更多相关文章
- 第三十节,目标检测算法之Fast R-CNN算法详解
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2 ...
- 目标检测(三)Fast R-CNN
作者:Ross Girshick 该论文提出的目标检测算法Fast Region-based Convolutional Network(Fast R-CNN)能够single-stage训练,并且可 ...
- Faster-rcnn实现目标检测
Faster-rcnn实现目标检测 前言:本文浅谈目标检测的概念,发展过程以及RCNN系列的发展.为了实现基于Faster-RCNN算法的目标检测,初步了解了RCNN和Fast-RCNN实现目标检 ...
- 论文笔记:目标检测算法(R-CNN,Fast R-CNN,Faster R-CNN,FPN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的视觉任务大多数考虑使用SIFT和HOG特征,而近年来CNN和ImageNet的出现使得图像分类问题取得重大突破,那么这方面的 ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- 第三十五节,目标检测之YOLO算法详解
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object de ...
- 第三十四节,目标检测之谷歌Object Detection API源码解析
我们在第三十二节,使用谷歌Object Detection API进行目标检测.训练新的模型(使用VOC 2012数据集)那一节我们介绍了如何使用谷歌Object Detection API进行目标检 ...
- 第三十三节,目标检测之选择性搜索-Selective Search
在基于深度学习的目标检测算法的综述 那一节中我们提到基于区域提名的目标检测中广泛使用的选择性搜索算法.并且该算法后来被应用到了R-CNN,SPP-Net,Fast R-CNN中.因此我认为还是有研究的 ...
随机推荐
- DataGrip连接阿里云的MySQL
参考:https://www.cnblogs.com/i6010/articles/7723503.html 第一步:在/etc/mysql/my.cnf下找到bind-address = 127.0 ...
- entry 遍历 Map 元素
1.书写类 import java.util.HashMap; import java.util.Map; import java.util.Map.Entry; public class test ...
- vue学习-day04(路由)
目录: 1.组件传值-父组件向子组件传值和data与props的区别 2.组件传值-子组件通过事件调用向父组件传值 3.案例:发表评论.使用ref获取DOM元素和组件引用 ...
- (三)mysql -- 逻辑控制
条件控制 CASE validity_date THEN '月' THEN '年' ELSE '季' END CASE THEN '月' THEN '年' ELSE '季' END 循环控制 待补充
- MySQL主从服务器的原理和设置
一 主从配置的原理 mysql的Replication是一个异步的复制过程,从一个mysql instance(Master)复制到另一个mysql instance(Slave), 在mas ...
- 各种sort排序总结
冒泡排序 选择排序 插入排序
- gitlab webhook jenkins 403问题解决方案
1.gitlab webhook 403问题,一般描述为Error 403 anonymous is missing the Job/Build Permission 解决方法: 安装插件:gitla ...
- 【linux】杀掉进程命令
1.找到对应的进程 通过端口查找 lsof -i:端口号 netstat -tunlp | grep 端口 lsof -i:9500 netstat -tunlp | grep 9500 2. ...
- 阶段3 1.Mybatis_09.Mybatis的多表操作_3 完成account的一对一操作-通过写account的子类方式查询
先把多表查询的sql语句写出来 想要显示的字段 创建一个AccountUser类 继承Account.这样它就会从父类上继承一些信息 这里只需要定义username和address就可以了 .然后生成 ...
- Python学习之==>URL编码解码&if __name__ == '__main__'
一.URL编码解码 url的编码解码需要用到标准模块urllib中的parse方法 from urllib import parse url = 'http://www.baidu.com?query ...