Spark算子篇 --Spark算子之aggregateByKey详解
一。基本介绍
rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值
3代表每次分完组之后的每个组的初始值。
seqFunc代表combine的聚合逻辑
每一个mapTask的结果的聚合成为combine
combFunc reduce端大聚合的逻辑
ps:aggregateByKey默认分组
二。代码
from pyspark import SparkConf,SparkContext
from __builtin__ import str
conf = SparkConf().setMaster("local").setAppName("AggregateByKey")
sc = SparkContext(conf = conf) rdd = sc.parallelize([(1,1),(1,2),(2,1),(2,3),(2,4),(1,7)],2) def f(index,items):
print "partitionId:%d" %index
for val in items:
print val
return items rdd.mapPartitionsWithIndex(f, False).count() def seqFunc(a,b):
print "seqFunc:%s,%s" %(a,b)
return max(a,b) #取最大值
def combFunc(a,b):
print "combFunc:%s,%s" %(a ,b)
return a + b #累加起来
'''
aggregateByKey这个算子内部肯定有分组
'''
aggregateRDD = rdd.aggregateByKey(3, seqFunc, combFunc)
rest = aggregateRDD.collectAsMap()
for k,v in rest.items():
print k,v sc.stop()
三。详细逻辑
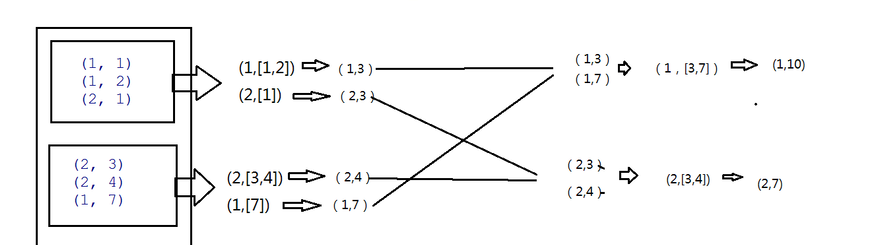
PS:
seqFunc函数 combine篇。
3是每个分组的最大值,所以把3传进来,在combine函数中也就是seqFunc中第一次调用 3代表a,b即1,max(a,b)即3 第二次再调用则max(3.1)中的最大值3即输入值,2即b值 所以结果则为(1,3)
底下类似。combine函数调用的次数与分组内的数据个数一致。
combFunc函数 reduce聚合
在reduce端大聚合,拉完数据后也是先分组,然后再调用combFunc函数
四。结果

持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Spark算子篇 --Spark算子之aggregateByKey详解的更多相关文章
- PowerShell攻防进阶篇:nishang工具用法详解
PowerShell攻防进阶篇:nishang工具用法详解 导语:nishang,PowerShell下并肩Empire,Powersploit的神器. 开始之前,先放出个下载地址! 下载地址:htt ...
- Mysql高手系列 - 第18篇:mysql流程控制语句详解(高手进阶)
Mysql系列的目标是:通过这个系列从入门到全面掌握一个高级开发所需要的全部技能. 这是Mysql系列第18篇. 环境:mysql5.7.25,cmd命令中进行演示. 代码中被[]包含的表示可选,|符 ...
- 精讲RestTemplate第4篇-POST请求方法使用详解
本文是精讲RestTemplate第4篇,前篇的blog访问地址如下: 精讲RestTemplate第1篇-在Spring或非Spring环境下如何使用 精讲RestTemplate第2篇-多种底层H ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- 【Java入门提高篇】Day34 Java容器类详解(十五)WeakHashMap详解
源码详解系列均基于JDK8进行解析 说明 在Java容器详解系列文章的最后,介绍一个相对特殊的成员:WeakHashMap,从名字可以看出它是一个 Map.它的使用上跟HashMap并没有什么区别,所 ...
- 【Java入门提高篇】Day30 Java容器类详解(十二)TreeMap详解
今天来看看Map家族的另一名大将——TreeMap.前面已经介绍过Map家族的两名大将,分别是HashMap,LinkedHashMap.HashMap可以高效查找和存储元素,LinkedHashMa ...
- Android Developer -- Bluetooth篇 开发实例之四 API详解
http://www.open-open.com/lib/view/open1390879771695.html 这篇文章将会详细解析BluetoothAdapter的详细api, 包括隐藏方法, 每 ...
- Java提高篇——equals()与hashCode()方法详解
java.lang.Object类中有两个非常重要的方法: 1 2 public boolean equals(Object obj) public int hashCode() Object类是类继 ...
- iOS开发——网络编程Swift篇&(七)NSURLSession详解
NSURLSession详解 // MARK: - /* 使用NSURLSessionDataTask加载数据 */ func sessionLoadData() { //创建NSURL对象 var ...
随机推荐
- GDAL编译
使用cmd命令行编译 1.首先在“开始菜单\所有程序\Microsoft Visual Studio 2008\Visual Studio Tools\ Visual Studio 2008命令提示” ...
- Cesium几个案例介绍
前言 本文为大家介绍几个Cesium的Demo,通过这几个Demo能够对如何使用Cesium有进一步的了解,并能充分理解Cesium的强大之处和新功能.其他的无需多言,如果还不太了解什么是Cesium ...
- Web、WCF和WS通过Nginx共享80端口
团队中的一个Web项目面对的用户网络环境多是在严格的防火墙安全条件下,通常只开放一些标准的端口如80,21等. 上线初期,因忽略了这个问题,除了Web应用是以80端口提供访问外,WCF和WS是以其他端 ...
- 阅读《Android 从入门到精通》(12)——自己主动完毕文本框
自己主动完毕文本框(AutoCompleteTextView) java.lang.Object; android.view.View; android.view.TextView; android. ...
- 基于C++11的线程池
1.封装的线程对象 class task : public std::tr1::enable_shared_from_this<task> { public: task():exit_(f ...
- hibernate学习笔记之中的一个(JDBC回想-ORM规范)
JDBC回想-ORM规范 JDBC操作步骤 注冊数据库驱动 Class.forName("JDBCDriverClass") 数据库 驱动程序类 来源 Access sun.jdb ...
- 微服务架构之RPC-client序列化细节
通过上篇文章的介绍,知道了要实施微服务,首先要搞定RPC框架,RPC框架的职责要向[调用方]和[服务提供方]屏蔽各种复杂性: (1)让调用方感觉就像调用本地函数一样 (2)让服务提供方感觉就像实现一个 ...
- 摧枯拉朽,说说ES6的三把火
阅读目录 我是 Jser 我骄傲 作用域 模块系统 类(Class) 我是 Jser 我骄傲 JavaScript 如今可谓是屌丝逆袭高富帅的代名词哈,从当初闹着玩似的诞生到现在 Github 上力压 ...
- 稀疏分解中的MP与OMP算法
MP:matching pursuit匹配追踪 OMP:正交匹配追踪 主要介绍MP与OMP算法的思想与流程,解释为什么需要引入正交? !!今天发现一个重大问题,是在读了博主的正交匹配追踪(OMP)在稀 ...
- 将IDEA maven项目中src源代码下的xml等资源文件编译进classes文件夹
如果使用的是Eclipse,Eclipse的src目录下的xml等资源文件在编译的时候会自动打包进输出到classes文件夹.Hibernate和Spring有时会将配置文件放置在src目录下,编译后 ...