webmagic学习-使用注解编写爬虫
写在前面:
官方文档:http://webmagic.io/docs/zh/posts/ch5-annotation/README.html
WebMagic支持使用独有的注解风格编写一个爬虫,引入webmagic-extension包即可使用此功能。
在注解模式下,使用一个简单的Model对象加上注解,可以用极少的代码量就完成一个爬虫的编写。
注解模式的开发方式是这样的:
- 首先定义你需要抽取的数据,并编写Model类。
- 在类上写明@TargetUrl注解,定义对哪些URL进行下载和抽取。
- 在类的字段上加上@ExtractBy注解,定义这个字段使用什么方式进行抽取。
- 定义结果的存储方式。实现PageModelPipeline即可。
下面是我用webmagic的注解方式对芝麻代理(http://http.zhimaruanjian.com/)网站写的简单爬虫;
1、创建maven项目,引入需要的包;这里是我的pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>webmagic-parent</artifactId>
<groupId>us.codecraft</groupId>
<version>0.5.3</version>
</parent>
<groupId>webmagic</groupId>
<artifactId>webmagic-test</artifactId>
<!-- 这个提示让我remove掉 -->
<version>0.5.3</version>
<packaging>jar</packaging>
<name>webmagic-test</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<webmagic.version>0.5.3</webmagic.version>
</properties>
<dependencies>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>${webmagic.version}</version>
</dependency>
<!-- 根据上文所说的:引入webmagic-extension包即可使用此功能 -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>${webmagic.version}</version>
</dependency>
</dependencies>
</project>
2、上面说了,使用注解方式写webmagic爬虫,需要写一个Model类。这个Model类里面有需要pipeline持久化的字段,字段上通过@ExtractBy注解来指定这个字段抓取的规则;在类名上使用@TargetUrl注解,标识哪些url需要解析(相当于原来的us.codecraft.webmagic.processor.PageProcessor.process(Page)方法);最后写个main方法,并用OOSpider类创建爬虫程序。(别忘了写getter/setter方法)
package com.lacerta.ipproxy.OOpageprocess;
import java.util.List;import us.codecraft.webmagic.Site;import us.codecraft.webmagic.model.OOSpider;import us.codecraft.webmagic.model.annotation.ExtractBy;import us.codecraft.webmagic.model.annotation.TargetUrl;import us.codecraft.webmagic.scheduler.RedisScheduler;
@TargetUrl(value = "(http://http.zhimaruanjian.com/proxylist/(\\d)/)|(http://http.zhimaruanjian.com/inha/(\\d)+/)")
public class IpProxyModel {
@ExtractBy("//td[@data-title='IP']/text()")
List<String> IP;
@ExtractBy("//td[@data-title='PORT']/text()")
List<String> PORT;
@ExtractBy("//td[@data-title='匿名度']/text()")
List<String> 匿名度;
@ExtractBy("//td[@data-title='类型']/text()")
List<String> 类型;
@ExtractBy("//td[@data-title='get/post支持']/text()")
List<String> get_post支持;
@ExtractBy("//td[@data-title='位置']/text()")
List<String> 位置;
@ExtractBy("//td[@data-title='响应速度']/text()")
List<String> 响应速度;
@ExtractBy("//td[@data-title='最后验证时间']/text()")
List<String> 最后验证时间;
public static void main(String[] args) {
OOSpider.create(Site.me().setDomain("OOwww.kuaidaili.com"),
new new ConsolePageModelPipeline()//这里使用的Pipeline是打印到控制台。
, IpProxyModel.class)
.setScheduler(new RedisScheduler("10.2.1.203"))//使用redis做为我的scheduler,参数是redis的ip地址
.addUrl("http://www.kuaidaili.com/proxylist/1/")//
.addUrl("http://http.zhimaruanjian.com/")//
.thread(3)//
.run();
}
//这里省略了所有字段的getter/setter方法。
}
如果不会使用RedisScheduler的童鞋可以使用默认的QueueScheduler(也就是不写.setScheduler(new RedisScheduler("10.2.1.203"))这一行就行了)到这里这个基于注解的webmagic爬虫就写好了。点击F11,让爬虫飞一会。。。。可以在控制台看到打印的结果。如果相应字段打印结果不正确,就要修改@ExtractBy注解的提取规则了。
3、是不是觉得控制台打印的结果太乱了?是不是觉得垂直爬虫爬取的结构化数据应该保存到文件或者数据库中呢?好办,只要实us.codecraft.webmagic.pipeline.PageModelPipeline<T>这个借口就行了。这里我参考官方自带的us.codecraft.webmagic.pipeline.FilePageModelPipeline自己写了一个com.lacerta.ipproxy.OOpageprocess.IpProxyFilePageModelPipeline,这个PageModelPipeline会以我自定义的方式,把爬取的结构化数据保存到文件中。那么,上代码:
package com.lacerta.ipproxy.OOpageprocess;
import java.io.BufferedWriter;import java.io.FileWriter;import java.io.IOException;import java.util.List;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import us.codecraft.webmagic.Task;import us.codecraft.webmagic.model.HasKey;import us.codecraft.webmagic.pipeline.PageModelPipeline;import us.codecraft.webmagic.utils.FilePersistentBase;
public class IpProxyFilePageModelPipeline extends FilePersistentBase implements PageModelPipeline<IpProxyModel> {
private Logger logger = LoggerFactory.getLogger(getClass());
/**
* new JsonFilePageModelPipeline with default path "/data/webmagic/"
*/
public IpProxyFilePageModelPipeline() {
setPath("/data/webmagic/");
}
public IpProxyFilePageModelPipeline(String path) {
setPath(path);
}
private boolean flag = true; // 标志位,如果true就writer.
@Override
public void process(IpProxyModel ipProxyModel, Task task) {
String path = this.path + PATH_SEPERATOR + task.getUUID() + PATH_SEPERATOR;
BufferedWriter writer = null;
try {
String filename;
if (ipProxyModel instanceof HasKey) {
filename = path + ((HasKey) ipProxyModel).key() + ".txt";
} else {
filename = path + "IpProxyFileResult.txt";
}
writer = new BufferedWriter(new FileWriter(getFile(filename), true));
if (flag) {
writer.write("IP\tPORT\t匿名度\t类型\tGet/post支持\t位置\t响应速度\t最后验证时间\r\n");
flag = false;
}
List<String> ip = ipProxyModel.getIP();
List<String> port = ipProxyModel.getPORT();
List<String> 匿名度 = ipProxyModel.get匿名度();
List<String> 类型 = ipProxyModel.get类型();
List<String> get_post支持 = ipProxyModel.getGet_post支持();
List<String> 位置 = ipProxyModel.get位置();
List<String> 响应速度 = ipProxyModel.get响应速度();
List<String> 最后验证时间 = ipProxyModel.get最后验证时间();
if (get_post支持.size() == 0) {
for (int i = 0; i < ip.size(); i++) {
writer.write(ip.get(i) + "\t" + port.get(i) + "\t" + 匿名度.get(i) + "\t" + 类型.get(i) + "\tnull\t"
+ 位置.get(i) + "\t" + 响应速度.get(i) + "\t" + 最后验证时间.get(i) + "\r\n");
}
} else {
for (int i = 0; i < ip.size(); i++) {
writer.write(ip.get(i) + "\t" + port.get(i) + "\t" + 匿名度.get(i) + "\t" + 类型.get(i) + "\t"
+ get_post支持.get(i) + "\t" + 位置.get(i) + "\t" + 响应速度.get(i) + "\t" + 最后验证时间.get(i)
+ "\r\n");
}
}
} catch (IOException e) {
logger.warn("write file error", e);
} finally {
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
其实也没啥,官方提供了us.codecraft.webmagic.pipeline.FilePageModelPipeline,照着抄一个就行了。
最后,看数据吧:(路径:F:\spider\IpProxyModel\OOwww.kuaidaili.com\IpProxyFileResult.txt)这里只复制了前40条记录。
IP PORT 匿名度 类型 Get/post支持 位置 响应速度 最后验证时间218.20.236.249 8118 高匿名 HTTP, HTTPS GET, POST 中国 广东省 广州市 电信 2秒 2分钟前114.227.62.150 8088 高匿名 HTTP, HTTPS GET, POST 中国 江苏省 常州市 电信 1秒 2分钟前183.153.3.96 808 高匿名 HTTP, HTTPS GET, POST 中国 浙江省 台州市 电信 1秒 2分钟前117.86.12.191 808 高匿名 HTTP GET, POST 中国 江苏省 南通市 电信 3秒 2分钟前116.17.136.186 9797 透明 HTTP, HTTPS GET, POST 中国 广东省 惠州市 电信 1秒 1分钟前59.78.17.198 1080 高匿名 HTTP, HTTPS GET, POST 中国 上海市 上海市 教育网 2秒 4分钟前121.35.130.117 9797 透明 HTTP, HTTPS GET, POST 中国 广东省 深圳市 电信 2秒 7分钟前183.141.107.54 3128 高匿名 HTTP, HTTPS GET, POST 中国 浙江省 嘉兴市 电信 3秒 10分钟前115.29.37.86 8088 高匿名 HTTP GET, POST 中国 山东省 青岛市 阿里云 2秒 13分钟前59.66.166.51 8123 高匿名 HTTP, HTTPS GET, POST 中国 北京市 北京市 教育网 1秒 16分钟前27.46.50.22 8888 透明 HTTP, HTTPS GET, POST 中国 广东省 深圳市 联通 3秒 19分钟前60.191.164.83 3128 透明 HTTP GET, POST 中国 浙江省 台州市 电信 0.4秒 23分钟前110.73.40.246 8123 高匿名 HTTP, HTTPS GET, POST 广西壮族自治区南宁市 联通 3秒 26分钟前119.86.48.30 8998 高匿名 HTTP, HTTPS GET, POST 中国 重庆市 重庆市 电信 1秒 28分钟前101.6.52.199 8123 高匿名 HTTP GET, POST 中国 北京市 北京市 教育网 2秒 31分钟前112.92.218.221 9797 透明 HTTP, HTTPS GET, POST 中国 广东省 中山市 联通 3秒 34分钟前119.57.112.130 8080 透明 HTTP, HTTPS GET, POST 中国 北京市 北京市 3秒 38分钟前114.250.48.111 9000 透明 HTTP, HTTPS GET, POST 中国 北京市 北京市 联通 2秒 40分钟前119.122.212.36 9000 透明 HTTP, HTTPS GET, POST 中国 广东省 深圳市 电信 2秒 44分钟前113.245.57.201 8118 高匿名 HTTP, HTTPS GET, POST 中国 湖南省 株洲市 电信 1秒 46分钟前115.200.164.8 8998 高匿名 HTTP, HTTPS GET, POST 中国 浙江省 杭州市 电信 1秒 49分钟前14.112.208.155 9999 透明 HTTP, HTTPS GET, POST 中国 广东省 惠州市 电信 2秒 53分钟前113.110.208.124 9000 透明 HTTP, HTTPS GET, POST 中国 广东省 深圳市 电信 1秒 55分钟前182.37.126.246 808 高匿名 HTTP, HTTPS GET, POST 中国 山东省 日照市 电信 0.4秒 59分钟前123.127.8.248 80 高匿名 HTTP, HTTPS GET, POST 中国 北京市 北京市 联通 2秒 1小时前122.96.59.106 82 高匿名 HTTP GET, POST 江苏省南京市 联通 1秒 1小时前111.13.7.42 82 高匿名 HTTP GET, POST 中国 北京市 北京市 移动 2秒 1小时前219.216.122.250 8998 高匿名 HTTP, HTTPS GET, POST 中国 辽宁省 沈阳市 教育网 2秒 1小时前117.23.248.234 8118 高匿名 HTTP GET, POST 中国 陕西省 宝鸡市 电信 2秒 1小时前171.38.78.27 8123 高匿名 HTTP, HTTPS GET, POST 广西壮族自治区玉林市 联通 1秒 1小时前171.110.218.210 9000 透明 HTTP, HTTPS GET, POST 中国 广西壮族自治区 来宾市 电信 2秒 1小时前183.141.154.125 3128 高匿名 HTTP, HTTPS GET, POST 中国 浙江省 嘉兴市 电信 2秒 1小时前171.11.186.176 8118 高匿名 HTTP GET, POST 中国 河南省 商丘市 电信 2秒 1小时前124.133.154.83 8090 匿名 HTTP GET, POST 中国 山东省 济南市 联通 2秒 1小时前118.81.251.60 9797 透明 HTTP, HTTPS GET, POST 中国 山西省 太原市 联通 0.8秒 1小时前115.229.99.21 808 高匿名 HTTP, HTTPS GET, POST 中国 浙江省 嘉兴市 电信 2秒 1小时前124.193.7.247 3128 透明 HTTP GET, POST 北京市 鹏博士宽带 2秒 1小时前125.33.253.87 9797 透明 HTTP, HTTPS GET, POST 中国 北京市 北京市 联通 0.7秒 1小时前221.227.131.147 8000 高匿名 HTTP GET, POST 中国 江苏省 南通市 电信 3秒 1小时前
4、源码解读:
参考:http://m.blog.csdn.net/article/details?id=51971708
OOSpider这个类继承Spider,但是对于四大组件中的PageProcesser做了更改
Pipeline需要继承PageModelPipeline,OOSpider成员变量有个ModelPipeline,ModelPipeline首先执行,然后调用用户自己实现的PageModelPipeline。
- 初始化一个OOSpider:
public OOSpider(Site site, PageModelPipeline pageModelPipeline, Class... pageModels) {
this(ModelPageProcessor.create(site, pageModels));
this.modelPipeline = new ModelPipeline();
super.addPipeline(modelPipeline);
for (Class pageModel : pageModels) {
if (pageModelPipeline != null) {
this.modelPipeline.put(pageModel, pageModelPipeline);
}
pageModelClasses.add(pageModel);
}
}
- ModelPageProcessor,这个类继承PageProcessor,所以在主流程中将会执行对Page的解析工作, 具体的解析工作是由PageModelExtractor执行,每个包含注解的class都会对应一个PageModelExtractor。
写在后面:
今天其实想做爬虫的ip代理,但是昨天晚上回家路上没事时把官方文档的这一章看完了,正好练习一下。
再说爬虫iP代理:
先说us.codecraft.webmagic.Site.setCycleRetryTimes(int)方法:这个方法在当前url download失败后,会添加到scheduler最后,int参数,就是这样重复的次数。
us.codecraft.webmagic.Site.setHttpProxyPool(List<String[]>)方法用户设置代理连接池;但是设置后从来就没有成功过:
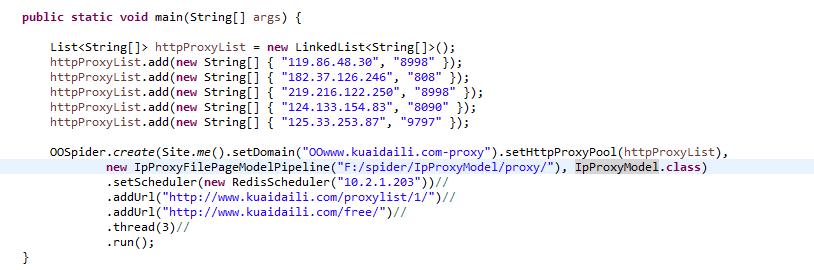
不知道咋回事啊。要上网找一些资料参考一下。
webmagic学习-使用注解编写爬虫的更多相关文章
- SpringMVC学习之使用注解编写SpringMVC程序
SpringMVC介绍 Spring的web框架围绕DispatcherServlet设计.DispatcherServlet的作用是将请求分发到不同的处理器.从Spring 2.5开始,使用Java ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
- Java学习:注解,反射,动态编译
狂神声明 : 文章均为自己的学习笔记 , 转载一定注明出处 ; 编辑不易 , 防君子不防小人~共勉 ! Java学习:注解,反射,动态编译 Annotation 注解 什么是注解 ? Annotat ...
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- 2.学习SpringMVC注解入门篇
一.SpringMVC执行流程 . 二.创建项目学习SpringMVC注解 按照我之前的SpringMVC创建项目,首先创建一个项目springmvc01,配置好pom.xml,web.xml,spr ...
- Java学习之注解篇
Java学习之注解篇 0x00 前言 续上篇文章,这篇文章就来写一下注解的相关内容. 0x01 注解概述 Java注解(Annotation)又称Java标注,是JDK5.0约会的一种注释机制. 和J ...
- python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容
python3.4学习笔记(十七) 网络爬虫使用Beautifulsoup4抓取内容 Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖 ...
- 编写爬虫程序的神器 - Groovy + Jsoup + Sublime
写过很多个爬虫小程序了,之前几次主要用C# + Html Agility Pack来完成工作.由于.NET BCL只提供了"底层"的HttpWebRequest和"中层& ...
- TestNG学习-002-annotaton 注解概述及其执行顺序
此文主要讲述用 TestNG 基础的 annotation (注解)知识,及其执行的顺序,并通过一个 TestNG 简单的实例演示 annotation 的执行顺序. 希望能对初学 TestNG 测试 ...
随机推荐
- oracle 行转列 列转行
行转列 这是一个Oracle的列转行函数:LISTAGG() 先看示例代码: with temp as( select 'China' nation ,'Guangzhou' city from du ...
- Linux crontab任务调度
一.crontab说明 Linux crontab任务调度是在规定的时间频率内去执行相应的任务. 二.crontab文件详情 1.crontab文件在Linux中的/etc/crontab 2.查看c ...
- php根据ip段以及子网掩码,判断某ip是否处于某子网下
为了检测客户端ip是否位于指定的网络里(如防火墙过滤有时候需要用到这个技术),有如下方法: 1.第一种 public function netMatch($client_ip, $server ...
- 运行Vue在ASP.NET Core应用程序并部署在IIS上
前言 项目一直用的ASP.NET Core,但是呢我对ASP.NET Core一些原理也还未开始研究,仅限于会用,不过园子中已有大量文章存在,借着有点空余时间,我们来讲讲如何利用ASP.NET Cor ...
- vuejs2-生命周期
https://segmentfault.com/a/1190000008879966 1 声明周期图示 2 过渡
- 使用jquery-qrcode在页面上生成二维码,支持中文
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Django 模型中自定义Manager和模型方法
1.自定义管理器(Manager) 在语句Book.objects.all()中,objects是一个特殊的属性,通过它来查询数据库,它就是模型的一个Manager. 每个Django模型至少有一个m ...
- linux 计划任务(crontab)
每天写一点,总有一天我这条咸鱼能变得更咸 cron服务是一个linux下 的定时执行工具,可以在无需人工干预的情况下运行作业.频率可以划分为 分钟 小时 天 月 周,格式如下: 1.crontab 服 ...
- 图论 Warshall 和Floyd 矩阵传递闭包
首先我们先说下图论,一般图存储可以使用邻接矩阵,或邻接表,一般使用邻接矩阵在稠密图比较省空间. 我们来说下有向图,一般的有向图也是图,图可以分为稠密图,稀疏图,那么从意思上,稠密图就是点的边比较多,稀 ...
- JS对象深度克隆
首先看一个例子: var student = { name:"yxz", age:25 } var newStudent = student; newStudent.sex = & ...