NHibernate教程(7)--并发控制
本节内容
- 什么是并发控制?
- 悲观并发控制(Pessimistic Concurrency)
- 乐观并发控制(Optimistic Concurrency)
- NHibernate支持乐观并发控制
- 实例分析
- 结语
什么是并发控制?
当许多人试图同时修改数据库中的数据时,必须实现一个控制系统,使一个人所做的修改不会对他人所做的修改产生负面影响。这称为并发控制。
简单的理解就是2个或多个用者同时编辑相同的数据。这里的用者可能是:实际用户、不同服务、不同的代码段(使用多线程),及其在断开式和连接式情况下可能发生的情况。
并发控制理论根据建立并发控制的方法而分为两类:
悲观并发控制(Pessimistic Concurrency)
一个锁定系统,可以阻止用户以影响其他用户的方式修改数据。如果用户执行的操作导致应用了某个锁,只有这个锁的所有者释放该锁,其他用户才能执行与该锁冲突的操作。这种方法之所以称为悲观并发控制,是因为它主要用于数据争用激烈的环境中,以及发生并发冲突时用锁保护数据的成本低于回滚事务的成本的环境中。
简单的理解通常通过“独占锁”的方法。获取锁来阻塞对于别的进程正在使用的数据的访问。换句话说,读者和写者之间是会互相阻塞的 ,这可能导致数据同步冲突。
乐观并发控制(Optimistic Concurrency)
在乐观并发控制中,用户读取数据时不锁定数据。当一个用户更新数据时,系统将进行检查,查看该用户读取数据后其他用户是否又更改了该数据。如果其他用户更新了数据,将产生一个错误。一般情况下,收到错误信息的用户将回滚事务并重新开始。这种方法之所以称为乐观并发控制,是由于它主要在以下环境中使用:数据争用不大且偶尔回滚事务的成本低于读取数据时锁定数据的成本。
(以上摘自SQL Server2008 MSDN文档)
NHibernate支持乐观并发控制
NHibernate提供了一些方法来支持乐观并发控制:在映射文件中定义了<version> 节点和<timestamp>节点。其中<version> 节点用于版本控制,表明表中包含附带版本信息的数据。<timestamp>节点用于时间截跟踪,表明表中包含时间戳数据。时间戳本质上是一种对乐观锁定不是特别安全的实现。但是通常而言,版本控制方式是首选的方法。当然,有时候应用程序可能在其他方面使用时间戳。
下面用两幅图显示这两个节点映射属性:
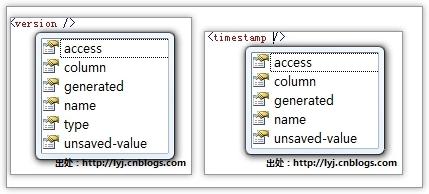
看看它们的意义:
- access(默认为property):NHibernate用于访问特性值的策略。
- column(默认为特性名):指定持有版本号的字段名或者持有时间戳的字段名。
- generated:生成属性,可选never和always两个属性。
- name:持久化类的特性名或者指定类型为.NET类型DateTime的特性名。
- type(默认为Int32):版本号的类型,可选类型为Int64、Int32、Int16、Ticks、Timestamp、TimeSpan。注意:<timestamp>和<version type="timestamp">是等价的。
- unsaved-value(在版本控制中默认是“敏感”值,在时间截默认是null):表示某个实例刚刚被实例化(尚未保存)时的版本特性值,依靠这个值就可以把这种情况和已经在先前的会话中保存或装载的游离实例区分开来。(undefined指明使用标识特性值进行判断)
实例分析
下面用一个例子来实现乐观并发控制,这里使用Version版本控制。
1.修改持久化Customer类:添加Version属性
public class Customer
{
public virtual int CustomerId { get; set; }
//版本控制
public virtual int Version { get; set; }
public virtual string Firstname { get; set; }
public virtual string Lastname { get; set; }
}
2.修改映射文件:添加Version映射节点
<?xml version="1.0" encoding="utf-8" ?>
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2"
assembly="DomainModel" namespace="DomainModel">
<class name ="DomainModel.Entities.Customer,DomainModel" table="Customer">
<id name="CustomerId" column="CustomerId" type="Int32" unsaved-value="0">
<generator class ="native"></generator>
</id>
<version name="Version" column="Version" type="integer" unsaved-value="0"/>
<property name="Firstname" column ="Firstname" type="string" length="50" not-null="false"/>
<property name ="Lastname" column="Lastname" type="string" length="50" not-null="false"/>
</class>
</hibernate-mapping>
3.修改数据库,添加Version字段
具体参数:[Version] [int] NOT NULL 默认值为1,当然了修改数据库是最原始的方式了,如果你会使用SchemaExport,可以直接利用持久化类和映射文件生成数据库,以后在介绍如何使用这个。
4.并发更新测试
在测试之前,我们先看看数据库中什么数据,预知一下:
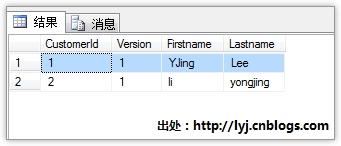
编写并发更新测试代码:
查询2次CustomerId为1的客户,这里就是上面的第一条数据,第一个修改为"CnBlogs",第二个修改为"www.cnblogs.com",两者同时更新提交。你想想发生什么情况?
[Test]
public void UpdateConcurrencyViolationCanotThrowException()
{
Customer c1 = _transaction.GetCustomerById(1);
Customer c2 = _transaction.GetCustomerById(1);
c1.Name.Firstname = "CnBlogs";
c2.Name.Firstname = "www.cnblogs.com"; _transaction.UpdateCustomerTransaction(c1);
_transaction.UpdateCustomerTransaction(c2);
}
让我们去看看数据库吧,一目了然:

我们发现CustomerId为1的客户更新了FirstName数据,并且Version更新为2。你知道什么原理了吗?看看这步NHibernate生成的SQL语句(我的可能比你的不一样):先查询数据库,在直接更新数据,看看NHibernate多么实在,明显做了一些优化工作。
SELECT customer0_.CustomerId as CustomerId3_0_,
customer0_.Version as Version3_0_,
customer0_.Firstname as Firstname3_0_,
customer0_.Lastname as Lastname3_0_,
customer0_1_.OrderDiscountRate as OrderDis2_4_0_,
customer0_1_.CustomerSince as Customer3_4_0_,
case
when customer0_1_.CustomerId is not null then 1
when customer0_.CustomerId is not null then 0
end
as clazz_0_ FROM Customer
customer0_ left outer join PreferredCustomer customer0_1_
on customer0_.CustomerId=customer0_1_.CustomerId
WHERE customer0_.CustomerId=@p0; @p0 = '1' UPDATE Customer SET Version = @p0, Firstname = @p1, Lastname = @p2
WHERE CustomerId = @p3 AND Version = @p4;
@p0 = '2', @p1 = 'www.cnblogs.com', @p2 = 'Lee', @p3 = '1', @p4 = '1'
5.并发删除测试
我们再来编写一个测试用于并发删除。查询2次CustomerId为2的客户,这里就是上面的第二条数据,两者同时删除数据。你想想发生什么情况?
[Test]
[ExpectedException(typeof(NHibernate.StaleObjectStateException))]
public void DeleteConcurrencyViolationCanotThrowException()
{
Customer c1 = _transaction.GetCustomerById(2);
Customer c2 = _transaction.GetCustomerById(2); _transaction.DeleteCustomerTransaction(c1);
_transaction.DeleteCustomerTransaction(c2);
}
同理,看看数据库里的数据,第二条数据不见了。

其生成SQL的查询语句同上面一样,只是一条删除语句:
DELETE FROM Customer WHERE CustomerId = @p0 AND Version = @p1; @p0 = '2', @p1 = '1'
好了,这里通过两个简单的实例说明了在NHibernate中对并发控制的支持。相信有了一定的了解,大家也可以编写一些有趣的测试来试试NHibernate中的乐观并发控制。
结语
这一篇我们初步探索了NHibernate中的并发控制,并用一个典型的实例分析了具体怎么做。我想这只是蜻蜓点水,更多的乐趣就自己探索吧。比如在不同的Session中的并发啊,更新啊,删除啊......
NHibernate教程(7)--并发控制的更多相关文章
- NHibernate教程
NHibernate教程 一.NHibernate简介 在今日的企业环境中,把面向对象的软件和关系数据库一起使用可能是相当麻烦.浪费时间的.NHibernate是一个面向.Net环境的对象/关系数据库 ...
- [转]NHibernate之旅(7):初探NHibernate中的并发控制
本节内容 什么是并发控制? 悲观并发控制(Pessimistic Concurrency) 乐观并发控制(Optimistic Concurrency) NHibernate支持乐观并发控制 实例分析 ...
- NHibernate之旅(7):初探NHibernate中的并发控制
本节内容 什么是并发控制? 悲观并发控制(Pessimistic Concurrency) 乐观并发控制(Optimistic Concurrency) NHibernate支持乐观并发控制 实例分析 ...
- NHibernate教程(9)一1对n关联映射
本节内容 引入 NHibernate中的集合类型 建立父子关系 父子关联映射 结语 引入 通过前几篇文章的介绍,基本上了解了NHibernate,但是在NHibernate中映射关系是NHiberna ...
- 通俗易懂的Nhibernate教程(2) ---- 配置之Nhibernate配置
在上一个教程中,我们讲了Nhibernate的基本使用!So,让我们回顾下Nhibernate使用基本的步骤吧 1.NHibernate配置 ----- 这一步我们告诉了Nhibernate:数据库 ...
- NHibernate教程(21)——二级缓存(下)
本节内容 引入 使用NHibernate二级缓存 启用缓存查询 管理NHibernate二级缓存 结语 引入 这篇我还继续上一篇的话题聊聊NHibernate二级缓存剩下的内容,比如你修改.删除数据时 ...
- NHibernate教程(20)——二级缓存(上)
本节内容 引入 介绍NHibernate二级缓存 NHibernate二级缓存提供程序 实现NHibernate二级缓存 结语 引入 上一篇我介绍了NHibernate内置的一级缓存即ISession ...
- NHibernate教程(19) —— 一级缓存
本节内容 引入 NHibernate一级缓存介绍 NHibernate一级缓存管理 结语 引入 大家看看上一篇了吗?对象状态.这很容易延伸到NHibernate的缓存.在项目中我们灵活的使用NHibe ...
- NHibernate教程(18)--对象状态
本节内容 引入 对象状态 对象状态转换 结语 引入 在程序运行过程中使用对象的方式对数据库进行操作,这必然会产生一系列的持久化类的实例对象.这些对象可能是刚刚创建并准备存储的,也可能是从数据库中查询的 ...
随机推荐
- 在webpack中使用Code Splitting--代码分割来实现vue中的懒加载
当Vue应用程序越来越大,使用Webpack的代码分割来懒加载组件,路由或者Vuex模块, 只有在需要时候才加载代码. 我们可以在Vue应用程序中在三个不同层级应用懒加载和代码分割: 组件,也称为异步 ...
- zzuli--2134: 维克兹的进制转换(规律)
2134: 维克兹的进制转换 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 287 Solved: 63SubmitStatusWeb Board D ...
- java.lang.NoSuchMethodError:android.content.Context.getDrawable
今天在开发的时候,这个代码在源码中是可以看到的,但是在android 4.3手机上面会报错,具体错误信息和代码如下: setBackgroundDrawable(context.getDrawable ...
- Linux 组配置文件(/etc/group)
一.概述 Linux 组配置(/etc/group)文件分为4个字段,分别为: 组名.组密码.GID和组成员. 二.示例 用户apple和banana的默认组为fruit. [root@titan ~ ...
- 友盟崩溃日志分析工具 - dSYMTools
公司的项目中集成了UM的统计功能,UM统计可以统计app的用户新增,版本分布,日志崩溃等信息,打开错误分析按钮,则可能会看到很多崩溃的日志信息 选择编辑可以选择更多的版本号 点击列表中的一个崩溃日志, ...
- React Native 系列(九) -- Tab标签组件
前言 本系列是基于React Native版本号0.44.3写的.很多的App都使用了Tab标签组件,例如QQ,微信等等,就是切换不同的选项,显示不同的内容.那么这篇文章将介绍RN中的Tab标签组件. ...
- python学习===从键盘输入一些字符,逐个把它们写到磁盘文件上,直到输入一个 # 为止。
#!/usr/bin/python # -*- coding: UTF-8 -*- if __name__ == '__main__': from sys import stdout filename ...
- oracle 错误码 ORA-00119 / ORA-00130
今天启动oracle时居然报错,错误信息如下: SQL> startup ORA-00119: invalid specification for system parameter LOCAL_ ...
- HTML中直接写js 函数
1.在HTML中直接写JS函数: <body onload="javascript:{window.location.href='http://www.baidu.com/'}&quo ...
- JavaScript正则表达式检验与递归函数实际应用
JS递归函数(菲波那切数列) 实例解析: 一组数字:0 1 1 2 3 5 8 13 0 1 2 3 4 5 6 7 sl(0)=0; sl ...