mycat - 水平分表
相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。
例如,分库中的举例,orders表水平分到order_win和order_linux两个库中。
配置mycat的schema.xml
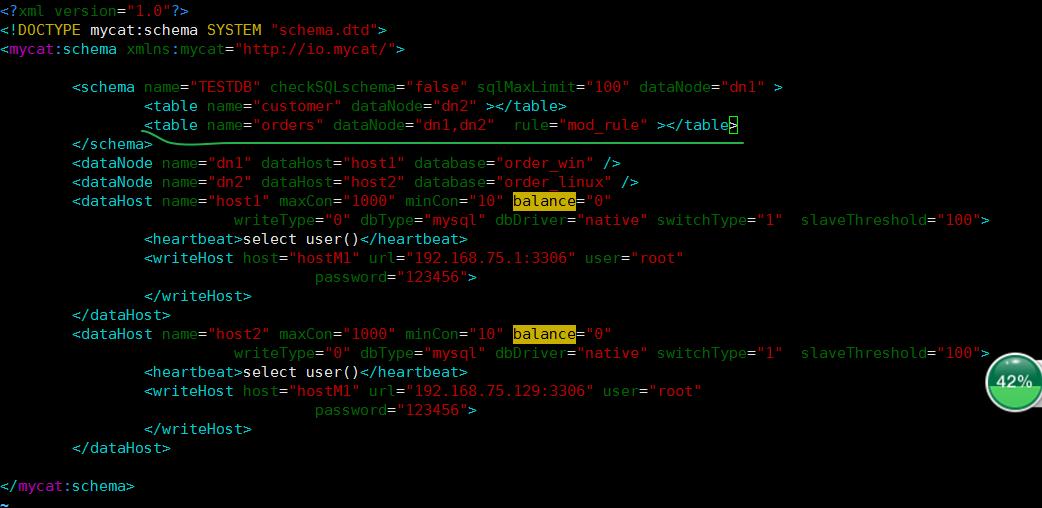
确认两个库中都有orders表,没有就新建下。
配置rule, vim /usr/local/mycat/conf/rule.xml


重启mycat,在mycat中执行测试插入数据。
insert into orders(id,order_type,customer_id,amount)values(1,1,1,1000.00);
insert into orders(id,order_type,customer_id,amount)values(2,1,2,1000.00);
insert into orders(id,order_type,customer_id,amount)values(3,1,3,1000.00);
insert into orders(id,order_type,customer_id,amount)values(4,1,4,1000.00);
insert into orders(id,order_type,customer_id,amount)values(5,1,5,1000.00);
insert into orders(id,order_type,customer_id,amount)values(6,1,6,1000.00);
结果:两个库中的orders各有一部分数据。是根据customer_id通过mod-long算法,计算出要插入哪个库的哪个orders表。
此时有个问题,orders表已经水平分表,然而orders_detail表并没有;此时如果做这两个表的关联查询会报错,因为部分数据不能找到表。
解决思路:把orders_detail也水平分表,但是要求实现订单详细记录要和订单记录在同一库中。
修改:schema.xml,并建立相关表,我的是在orders_linux下创建order_detail。

重启mycat,执行。
insert into orders_detail(id,detail,order_id)values(1,"球鞋一双",1);
insert into orders_detail(id,detail,order_id)values(2,"牙膏1",2);
insert into orders_detail(id,detail,order_id)values(3,"牙刷2",2);
insert into orders_detail(id,detail,order_id)values(4,"T恤",3);
insert into orders_detail(id,detail,order_id)values(5,"手套",3);
insert into orders_detail(id,detail,order_id)values(6,"帽子",3);
insert into orders_detail(id,detail,order_id)values(7,"金克斯",4);
insert into orders_detail(id,detail,order_id)values(8,"卢锡安",4);
insert into orders_detail(id,detail,order_id)values(9,"诺克",5);
insert into orders_detail(id,detail,order_id)values(10,"盲僧",6);
insert into orders_detail(id,detail,order_id)values(11,"狼人",6);
insert into orders_detail(id,detail,order_id)values(12,"赵信",6);
结果:有关此订单的详细记录就会进入同一个库中。
此时订单有状态,描述状态的表,在每个库中都有用,所以需要每个用到的库都保留一份。也称作全局表。
》对于全局表,每个库中都有一份,mycat写操作时所有的库都要同步更新;所以,全局表一般不能是大数据表或者频繁修改的表。一般为字典表,系统表为宜。
全局表配置如下:

新建dict_order_type表,重启mycat,测试插入数据。
insert into dict_order_type values(101,'付款');
insert into dict_order_type values(101,'发货');
在mycat执行后,会发现两个库中的全局表dict_order_type,都会插入数据。注意id需要使用从序列表读出的数据。
insert into orders(id,order_type,customer_id,amount)values(next value for MYCATSEQ_ORDERS,1,1,1000.00);
mycat - 水平分表的更多相关文章
- mycat水平分表
和垂直分库不同,水平分表,是将那些io频繁,且数据量大的表进行水平切分. 基本的配置和垂直分库一样,我们需要改的就是我们的 schema.xml和rule.xml文件配置(server.xml不用做任 ...
- mysql中的优化, 简单的说了一下垂直分表, 水平分表(有几种模运算),读写分离.
一.mysql中的优化 where语句的优化 1.尽量避免在 where 子句中对字段进行表达式操作select id from uinfo_jifen where jifen/60 > 100 ...
- mysql 水平分表技术
这里做的是我的一个笔记. 水平分表比较简单, 理解就是: 合并的表使用的必须是MyISAM引擎 表的结构必须一致,包括索引.字段类型.引擎和字符集 数据表 user1 CREATE TABLE `us ...
- 玩转SpringBoot之整合Mybatis拦截器对数据库水平分表
利用Mybatis拦截器对数据库水平分表 需求描述 当数据量比较多时,放在一个表中的时候会影响查询效率:或者数据的时效性只是当月有效的时候:这时我们就会涉及到数据库的分表操作了.当然,你也可以使用比较 ...
- MySQL常见水平分表技术方案
根据经验,Mysql表数据一般达到百万级别,查询效率会很低,容易造成表锁,甚至堆积很多连接,直接挂掉:水平分表能够很大程度较少这些压力. 1.按时间分表 这种分表方式有一定的局限性,当数据有较强的实效 ...
- mysql使用MRG_MyISAM(MERGE)实现水平分表
在MySQL中数据的优化尤其是大数据量的优化是一门很大的学问,当然其它数据库也是如此,即使你不是DBA,做为一名程序员掌握一些基本的优化信息,也可以让你在自己的程序开发中受益匪浅.当然数据库的优化有很 ...
- mysql数据库的水平分表与垂直分表实例讲解
mysql语句的优化有局限性,mysql语句的优化都是围绕着索引去优化的,那么如果mysql中的索引也解决不了海量数据查询慢的状况,那么有了水平分表与垂直分表的出现(我就是记录一下自己的理解) 水平分 ...
- TDSQL MySQL版基本原理-水平分表 读写分离 弹性扩展 强同步
TDSQL MySQL版(TDSQL for MySQL)是部署在腾讯云上的一种支持自动水平拆分.Shared Nothing 架构的分布式数据库.TDSQL MySQL版 即业务获取的是完整的逻辑库 ...
- Sharding-JDBC 实现水平分表
1.搭建环 (1) 技术: SpringBoot2.2.1+ MyBatisPlus + Sharding-JDBC + Druid 连接池(2)创建 SpringBoot 工程
随机推荐
- UVA12113-Overlapping Squares(二进制枚举)
Problem UVA12113-Overlapping Squares Accept:116 Submit:596 Time Limit: 3000 mSec Problem Descripti ...
- docker 9 docker的容器命令
有镜像才能创建容器,这是根本的前提 下面我们以下载一个centos镜像来做演示. [root@t-docker chenzx]# docker images REPOSITORY TAG IMAGE ...
- oradebug 10046
一.对当前的session使用oradebug命令: SQL> conn / as sysdba Connected. SQL> oradebug setmypid Statement p ...
- leetcode 4:Median of Two Sorted Arrays
public double FindMedianSortedArrays(int[] nums1, int[] nums2) { int t=nums1.Length+nums2.Length; in ...
- 前端面试送命题(二)-callback,promise,generator,async-await
前言 本篇文章适合前端架构师,或者进阶的前端开发人员:我在面试vmware前端架构师的时候,被问到关于callback,promise,generator,async-await的问题. 首先我们回顾 ...
- 纯手写AJAX
function ajax(){ //http相应对象 var xmlhttp; //判断浏览器 if(window.XMLHttpRequest){ xmlhttp = new XMLHttpReq ...
- Jquery遍历之获取子级元素、同级元素和父级元素
Jquery遍历之获取子级元素.同级元素和父级元素 Jquery的遍历,其实就当前位置的元素相对于其他元素的位置的关系进行查找或选取HTML元素.以某项选择开始,并沿着这条线进行移动,或向上(父级). ...
- Python-Urllib库详解
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib: Urllib是python内置的HTTP请求库: urllib.requ ...
- R语言绘制QQ图
无论是直方图还是经验分布图,要从比较上鉴别样本是否处近似于某种类型的分布是困难的 QQ图可以帮我们鉴别样本的分布是否近似于某种类型的分布 R语言,代码如下: > qqnorm(w);qqline ...
- 小小知识点(一)——利用电脑自带的BitLocker对磁盘加密
1.利用电脑自带的BitLocker可以对固定的或移动的磁盘加密 网上有很多的使用方法步骤,可参考百度经验:https://jingyan.baidu.com/article/636f38bb4fac ...