mycat - 水平分表
相对于垂直拆分的区别是:垂直拆分是把不同的表拆到不同的数据库中,而水平拆分是把同一个表拆到不同的数据库中。水平拆分不是将表的数据做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。
例如,分库中的举例,orders表水平分到order_win和order_linux两个库中。
配置mycat的schema.xml
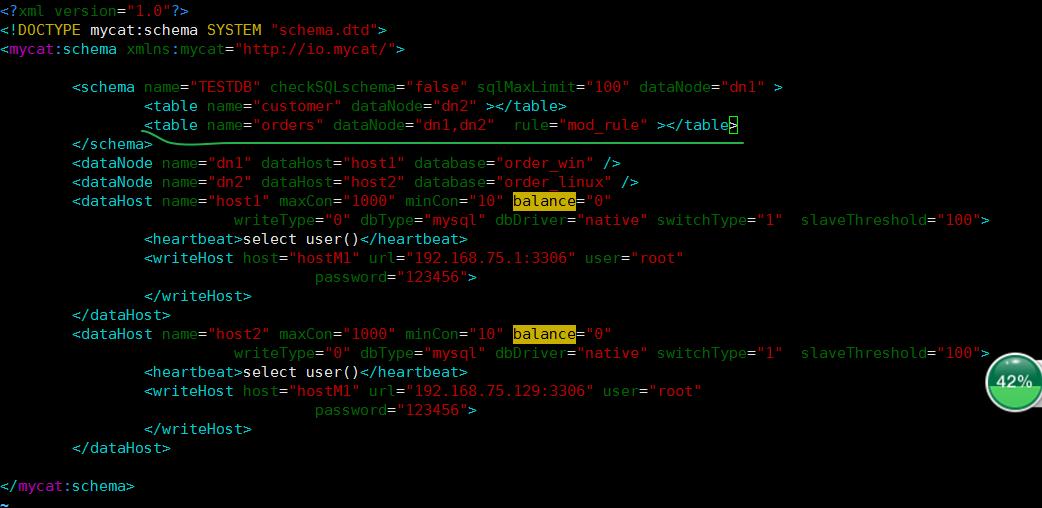
确认两个库中都有orders表,没有就新建下。
配置rule, vim /usr/local/mycat/conf/rule.xml


重启mycat,在mycat中执行测试插入数据。
insert into orders(id,order_type,customer_id,amount)values(1,1,1,1000.00);
insert into orders(id,order_type,customer_id,amount)values(2,1,2,1000.00);
insert into orders(id,order_type,customer_id,amount)values(3,1,3,1000.00);
insert into orders(id,order_type,customer_id,amount)values(4,1,4,1000.00);
insert into orders(id,order_type,customer_id,amount)values(5,1,5,1000.00);
insert into orders(id,order_type,customer_id,amount)values(6,1,6,1000.00);
结果:两个库中的orders各有一部分数据。是根据customer_id通过mod-long算法,计算出要插入哪个库的哪个orders表。
此时有个问题,orders表已经水平分表,然而orders_detail表并没有;此时如果做这两个表的关联查询会报错,因为部分数据不能找到表。
解决思路:把orders_detail也水平分表,但是要求实现订单详细记录要和订单记录在同一库中。
修改:schema.xml,并建立相关表,我的是在orders_linux下创建order_detail。

重启mycat,执行。
insert into orders_detail(id,detail,order_id)values(1,"球鞋一双",1);
insert into orders_detail(id,detail,order_id)values(2,"牙膏1",2);
insert into orders_detail(id,detail,order_id)values(3,"牙刷2",2);
insert into orders_detail(id,detail,order_id)values(4,"T恤",3);
insert into orders_detail(id,detail,order_id)values(5,"手套",3);
insert into orders_detail(id,detail,order_id)values(6,"帽子",3);
insert into orders_detail(id,detail,order_id)values(7,"金克斯",4);
insert into orders_detail(id,detail,order_id)values(8,"卢锡安",4);
insert into orders_detail(id,detail,order_id)values(9,"诺克",5);
insert into orders_detail(id,detail,order_id)values(10,"盲僧",6);
insert into orders_detail(id,detail,order_id)values(11,"狼人",6);
insert into orders_detail(id,detail,order_id)values(12,"赵信",6);
结果:有关此订单的详细记录就会进入同一个库中。
此时订单有状态,描述状态的表,在每个库中都有用,所以需要每个用到的库都保留一份。也称作全局表。
》对于全局表,每个库中都有一份,mycat写操作时所有的库都要同步更新;所以,全局表一般不能是大数据表或者频繁修改的表。一般为字典表,系统表为宜。
全局表配置如下:

新建dict_order_type表,重启mycat,测试插入数据。
insert into dict_order_type values(101,'付款');
insert into dict_order_type values(101,'发货');
在mycat执行后,会发现两个库中的全局表dict_order_type,都会插入数据。注意id需要使用从序列表读出的数据。
insert into orders(id,order_type,customer_id,amount)values(next value for MYCATSEQ_ORDERS,1,1,1000.00);
mycat - 水平分表的更多相关文章
- mycat水平分表
和垂直分库不同,水平分表,是将那些io频繁,且数据量大的表进行水平切分. 基本的配置和垂直分库一样,我们需要改的就是我们的 schema.xml和rule.xml文件配置(server.xml不用做任 ...
- mysql中的优化, 简单的说了一下垂直分表, 水平分表(有几种模运算),读写分离.
一.mysql中的优化 where语句的优化 1.尽量避免在 where 子句中对字段进行表达式操作select id from uinfo_jifen where jifen/60 > 100 ...
- mysql 水平分表技术
这里做的是我的一个笔记. 水平分表比较简单, 理解就是: 合并的表使用的必须是MyISAM引擎 表的结构必须一致,包括索引.字段类型.引擎和字符集 数据表 user1 CREATE TABLE `us ...
- 玩转SpringBoot之整合Mybatis拦截器对数据库水平分表
利用Mybatis拦截器对数据库水平分表 需求描述 当数据量比较多时,放在一个表中的时候会影响查询效率:或者数据的时效性只是当月有效的时候:这时我们就会涉及到数据库的分表操作了.当然,你也可以使用比较 ...
- MySQL常见水平分表技术方案
根据经验,Mysql表数据一般达到百万级别,查询效率会很低,容易造成表锁,甚至堆积很多连接,直接挂掉:水平分表能够很大程度较少这些压力. 1.按时间分表 这种分表方式有一定的局限性,当数据有较强的实效 ...
- mysql使用MRG_MyISAM(MERGE)实现水平分表
在MySQL中数据的优化尤其是大数据量的优化是一门很大的学问,当然其它数据库也是如此,即使你不是DBA,做为一名程序员掌握一些基本的优化信息,也可以让你在自己的程序开发中受益匪浅.当然数据库的优化有很 ...
- mysql数据库的水平分表与垂直分表实例讲解
mysql语句的优化有局限性,mysql语句的优化都是围绕着索引去优化的,那么如果mysql中的索引也解决不了海量数据查询慢的状况,那么有了水平分表与垂直分表的出现(我就是记录一下自己的理解) 水平分 ...
- TDSQL MySQL版基本原理-水平分表 读写分离 弹性扩展 强同步
TDSQL MySQL版(TDSQL for MySQL)是部署在腾讯云上的一种支持自动水平拆分.Shared Nothing 架构的分布式数据库.TDSQL MySQL版 即业务获取的是完整的逻辑库 ...
- Sharding-JDBC 实现水平分表
1.搭建环 (1) 技术: SpringBoot2.2.1+ MyBatisPlus + Sharding-JDBC + Druid 连接池(2)创建 SpringBoot 工程
随机推荐
- linux普通用户提权操作
[root@test1 ~]# vim /etc/sudoers ## Allow root to run any commands anywhere root ALL=(ALL) ALLzhouyu ...
- 第1章 Linux内核简介
1.1 Unix的历史 unix的优点 简介,没有繁冗的系统调用 所有东西都被当成了文件对待,对文件和对设备的操作是通过同样的系统调用的接口实现的 内核和相关工具使用C编写,具有很高的可移至性 创建新 ...
- Python:Day14 集合、函数
浅copy只copy一层 深copy相当于克隆一份 深copy要引入copy,具体如下: import copy wife = copy.copy() #此为浅copy,括号中要加copy的对象,相当 ...
- 【移动端】icon中ng-cordova使用
cordova介绍 Cordova提供了一组设备相关的API,通过这组API,移动应用能够以JavaScript访问原生的设备功能,如摄像头.麦克风等. Cordova支持如下7种移动操作系统:iOS ...
- Python框架学习之用Flask创建一个简单项目
在前面一篇讲了如何创建一个虚拟环境,今天这一篇就来说说如何创建一个简单的Flask项目.关于Flask的具体介绍就不详细叙述了,我们只要知道它非常简洁.灵活和扩展性强就够了.它不像Django那样集成 ...
- StringRedisTemplate操作Redis
在说到StringRedisTemplate操作Redis数据的时候,我们顺便谈谈StringRedisTemplate和RedisTemplate的区别. 一.StringRedisTemplate ...
- <unix网络编程>UDP套接字编程
典型的UDP客户/服务器程序的函数调用如下: 1.缓冲区 发送缓冲区用虚线表示,任何UDP套接字都有发送缓冲区,不过该缓冲区仅能表示写到该套接字的UDP数据报的上限.如果应用进程写一个大于套接字缓冲区 ...
- Python中print和return的区别
有趣的事,Python永远不会缺席! 如需转发,请注明出处:小婷儿的python https://www.cnblogs.com/xxtalhr/p/10742671.html 一.解释 1.ret ...
- java使用Map做缓存你真的用对了吗?弱引用WeakHashMap了解一下
目录 关于缓存我们应该考虑什么?-intsmaze WeakHashMap弱引用-intsmaze 线程安全问题-intsmaze Collections-intsmaze ThreadLocal-i ...
- webpack打包经验——处理打包文件体积过大的问题
前言 最近对一个比较老的公司项目做了一次优化,处理的主要是webpack打包文件体积过大的问题. 这里就写一下对于webpack打包优化的一些经验. 主要分为以下几个方面: 去掉开发环境下的配置 Ex ...