谈一谈Elasticsearch的集群部署
Elasticsearch天生就支持分布式部署,通过集群部署可以提高系统的可用性。本文重点谈一谈Elasticsearch的集群节点相关问题,搞清楚这些是进行Elasticsearch集群部署和拓扑结构设计的前提。关于如何配置集群的配置文件不会在本文中提及。(本文写作背景是Elasticsearch 2.3)
节点类型
1. 候选主节点(Master-eligible node)
一个节点启动后,就会使用Zen Discovery机制去寻找集群中的其他节点,并与之建立连接。集群中会从候选主节点中选举出一个主节点,主节点负责创建索引、删除索引、分配分片、追踪集群中的节点状态等工作。Elasticsearch中的主节点的工作量相对较轻,用户的请求可以发往任何一个节点,由该节点负责分发和返回结果,而不需要经过主节点转发。
正常情况下,集群中的所有节点,应该对主节点的选择是一致的,即一个集群中只有一个选举出来的主节点。然而,在某些情况下,比如网络通信出现问题、主节点因为负载过大停止响应等等,就会导致重新选举主节点,此时可能会出现集群中有多个主节点的现象,即节点对集群状态的认知不一致,称之为脑裂现象。为了尽量避免此种情况的出现,可以通过discovery.zen.minimum_master_nodes来设置最少可工作的候选主节点个数,建议设置为(候选主节点数 / 2) + 1, 比如,当有三个候选主节点时,该配置项的值为(3/2)+1=2,也就是保证集群中有半数以上的候选主节点。
候选主节点的设置方法是设置node.mater为true,默认情况下,node.mater和node.data的值都为true,即该节点既可以做候选主节点也可以做数据节点。由于数据节点承载了数据的操作,负载通常都很高,所以随着集群的扩大,建议将二者分离,设置专用的候选主节点。当我们设置node.data为false,就将节点设置为专用的候选主节点了。
node.master = true
node.data = false
2. 数据节点(Data node)
数据节点负责数据的存储和相关具体操作,比如CRUD、搜索、聚合。所以,数据节点对机器配置要求比较高,首先需要有足够的磁盘空间来存储数据,其次数据操作对系统CPU、Memory和IO的性能消耗都很大。通常随着集群的扩大,需要增加更多的数据节点来提高可用性。
前面提到默认情况下节点既可以做候选主节点也可以做数据节点,但是数据节点的负载较重,所以需要考虑将二者分离开,设置专用的数据节点,避免因数据节点负载重导致主节点不响应。
node.master = false
node.data = true
3. 客户端节点(Client node)
按照官方的介绍,客户端节点就是既不做候选主节点也不做数据节点的节点,只负责请求的分发、汇总等等,也就是下面要说到的协调节点的角色。这样的工作,其实任何一个节点都可以完成,单独增加这样的节点更多是为了负载均衡。
node.master = false
node.data = false
4. 协调节点(Coordinating node)
协调节点,是一种角色,而不是真实的Elasticsearch的节点,你没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点,都可以充当协调节点的角色。当一个节点A收到用户的查询请求后,会把查询子句分发到其它的节点,然后合并各个节点返回的查询结果,最后返回一个完整的数据集给用户。在这个过程中,节点A扮演的就是协调节点的角色。毫无疑问,协调节点会对CPU、Memory要求比较高。
分片与集群状态
分片(Shard),是Elasticsearch中的最小存储单元。一个索引(Index)中的数据通常会分散存储在多个分片中,而这些分片可能在同一台机器,也可能分散在多台机器中。这样做的优势是有利于水平扩展,解决单台机器磁盘空间和性能有限的问题,试想一下如果有几十TB的数据都存储同一台机器,那么存储空间和访问时的性能消耗都是问题。
默认情况下,Elasticsearch会为每个索引分配5个分片,但是这并不代表你必须使用5个分片,同时也不说分片越多性能就越好。一切都取决对你的数据量的评估和权衡。虽然跨分片查询是并行的,但是请求分发、结果合并都是需要消耗性能和时间的,所以在数据量较小的情况下,将数据分散到多个分片中反而会降低效率。如果说一定要给一个数据的话,笔者现在的每个分片数据量大概在20GB左右。
关于多分片与多索引的问题。一个索引可以有多个分片来完成存储,但是主分片的数量是在索引创建时就指定好的,且无法修改,所以尽量不要只为数据存储建立一个索引,否则后面数据膨胀时就无法调整了。笔者的建议是对于同一类型的数据,根据时间来分拆索引,比如一周建一个索引,具体取决于数据增长速度。
上面说的是主分片(Primary Shard),为了提高服务可靠性和容灾能力,通常还会分配复制分片(Replica Shard)来增加数据冗余性。比如设置复制分片的数量为1时,就会对每个主分片做一个备份。
通过API( http://localhost:9200/_cluster/health?pretty )可以查看集群的状态,通常集群的状态分为三种:
- Red,表示有主分片没有分配,某些数据不可用。
- Yellow,表示主分片都已分配,数据都可用,但是有复制分片没有分配。
- Green,表示主分片和复制分片都已分配,一切正常。
部署拓扑
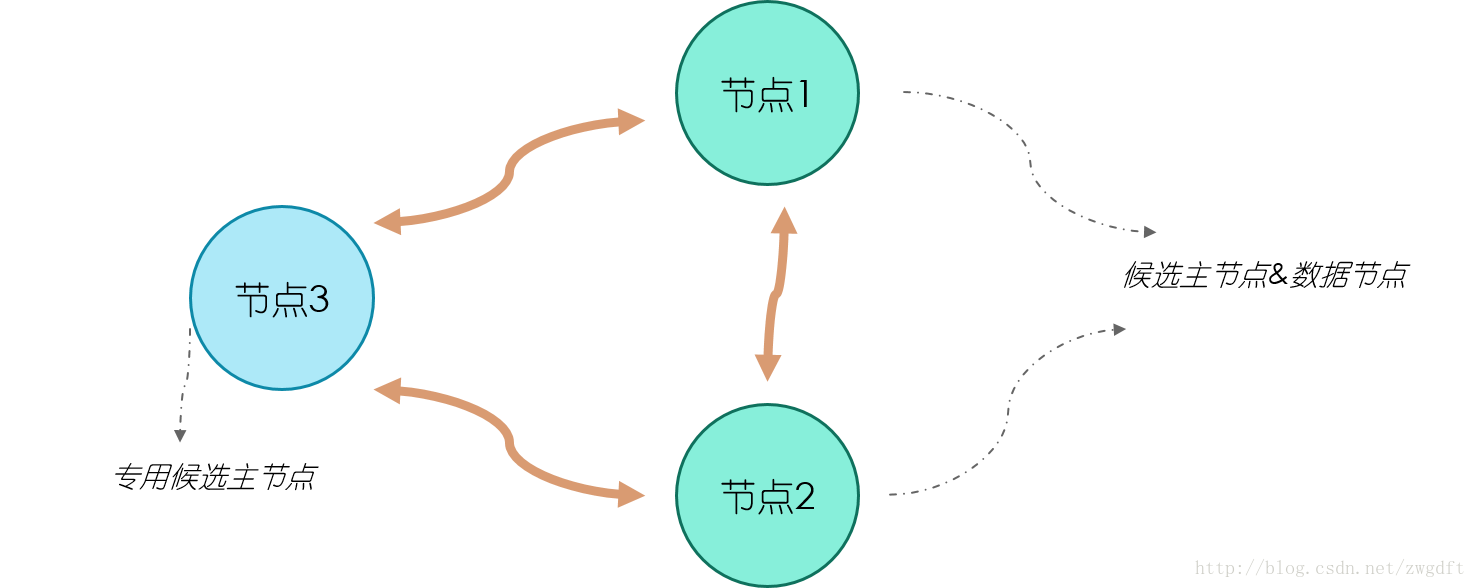
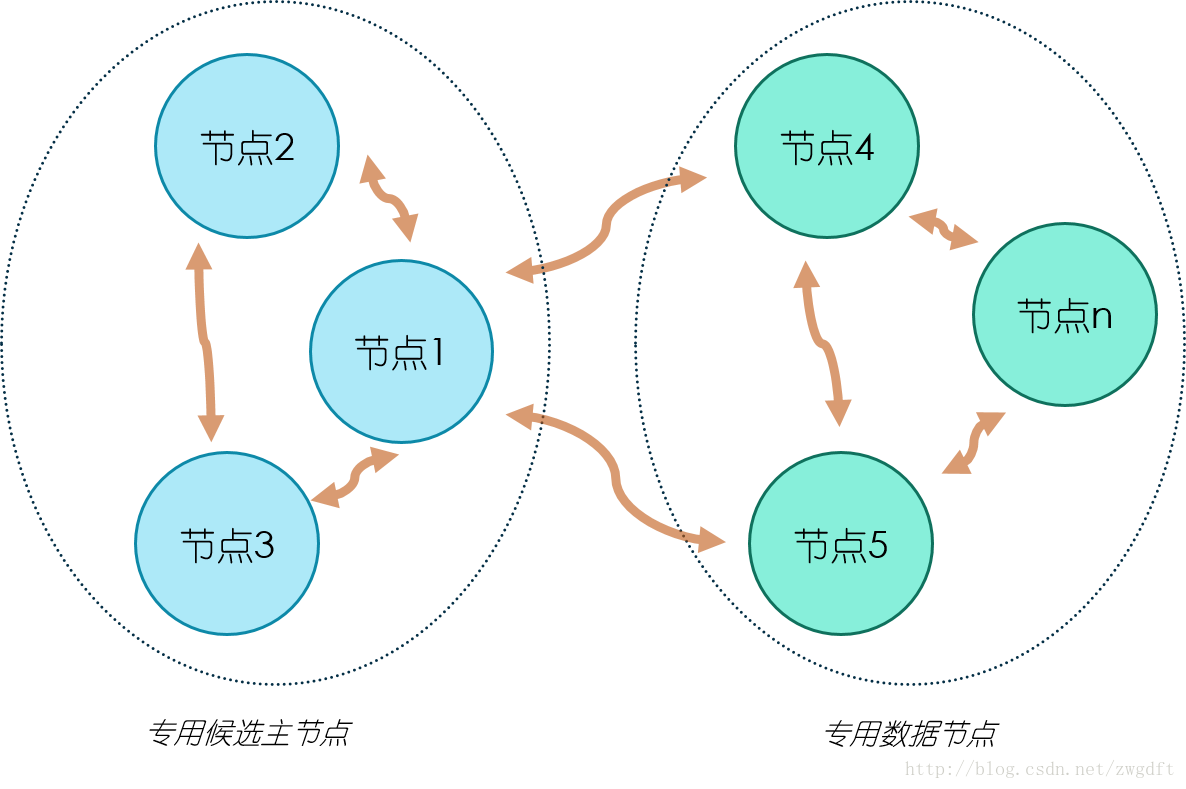
最后,来看两个集群部署的拓扑图,这里我们不考虑单个节点的调优。拓扑图一是一个简单的集群部署,适用于数据量较小的场景。集群中有三个节点,三个都是候选主节点,因此我们可以设置最少可工作候选主节点个数为2。节点1和2同时作为数据节点,两个节点的数据相互备份。这样的部署结构在扩展过程中,通常是先根据需要逐步加入专用的数据节点,最后考虑将数据节点和候选主节点分离,也就发展为了拓扑图二的结构。在拓扑图二中,有三个专用的候选主节点,用来做集群状态维护,数据节点根据需要进行增加,注意只增加专用的数据节点即可。
(全文完,本文地址:http://blog.csdn.net/zwgdft/article/details/54585644 )
Bruce,2017/01/18
</div>谈一谈Elasticsearch的集群部署的更多相关文章
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- elasticsearch集群部署
启动elk: zjtest7-redis:/usr/local/elasticsearch-2.3.4/bin# ./elasticsearch -d 后台运行 访问: http://192.168. ...
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- Elasticsearch学习总结 (Centos7下Elasticsearch集群部署记录)
一. ElasticSearch简单介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- Linux中Elasticsearch集群部署
1.下载安装包elasticsearch-6.3.1 安装包自己下载,网上很多 2.安装位置在cd /usr/local/elasticsearch/目录下 3.因为ES使用root权限运行会报错, ...
- ElasticSearch 深入理解 三:集群部署设计
ElasticSearch 深入理解 三:集群部署设计 ElasticSearch从名字中也可以知道,它的Elastic跟Search是同等重要的,甚至以Elastic为主要导向. Elastic即可 ...
- elasticsearch + kibana + x-pack + logstash_集群部署安装
elasticsearch 部分总体描述: 1.elasticsearch 的概念及特点.概念:elasticsearch 是一个基于 lucene 的搜索服务器.lucene 是全文搜索的一个框架. ...
- Elasticsearch系列---生产集群部署(上)
概要 本篇开始介绍Elasticsearch生产集群的搭建及相关参数的配置. ES集群的硬件特性 我们从开始编程就接触过各种各样的组件,而每种功能的组件,对硬件要求的特性都不太相同,有的需要很强的CP ...
随机推荐
- day5 模拟用户登录
_user= "yangtuo" _passwd = " # passd_authentication = False #flag 标志位 for i in range( ...
- 用webpack2.0构建vue2.0单文件组件超级详细精简实例
npm init -y 初始化项目 //-y 为自动生成package.json,如果需要自行配置,去掉-y即可 安装各种依赖项 npm install --save vue 安装vue2.0 np ...
- python学习日记(函数进阶)
命名空间 内置命名空间 存放了python解释器为我们提供的名字:print,input...等等,他们都是我们熟悉的,拿过来就可以用的方法. 内置的名字在启动解释器(程序运行前)的时候被加载在内存里 ...
- python学习日记(文件操作)
文件操作概述 计算机系统分为:操作系统,计算机硬件,应用程序. 我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序 ...
- 【BZOJ2576】[JSOI2011]序的计数 (动态规划)
[BZOJ2576][JSOI2011]序的计数 (动态规划) 题面 BZOJ 题解 首先构建一个新的虚拟节点连接所有目标节点,强行将其作为第一个被访问的节点,这样子就解决了图不连通的问题. 除了目标 ...
- 739. Daily Temperatures && 单调栈 && Python collections deque
题目大意 给你接下来每一天的气温,求出对于每一天的气温,下一次出现比它高气温的日期距现在要等多少天 解题思路 利用单调栈,维护一个单调递减的栈 将每一天的下标i入栈,维护一个温度递减的下标 若下一个温 ...
- A/D和D/A的学习
从我们学到的知识了解到,我们的单片机是一个典型的数字系统.数字系统只能对输入的数字信号进行处理,其输出信号也是数字信号.但是在工业检测系统和日常生活中的许多物理量都是模拟量,比如温度.长度.压力.速度 ...
- java 数组转字符串 字符串转数组
字符串转数组 使用Java split() 方法 split() 方法根据匹配给定的正则表达式来拆分字符串. 注意: . . | 和 * 等转义字符,必须得加 \\.多个分隔符,可以用 | 作为连字符 ...
- css 圆形头像
方法一:背景图片(推荐) 好处是,图片长宽不等的情况下图片不会变形 .ui-photo { width: 100px; height: 100px; background: url("img ...
- windows蜜汁调音
哈,用的蜂鸣器,我静音了这东西还放. 只能调的很垃圾,但是很好玩. #include<cstdio> #include<windows.h> using namespace s ...