AI学习--机器学习概述
学习框架

01-人工智能概述
- 机器学习、人工智能与深度学习的关系
达特茅斯会议-人工智能的起点
机器学习是人工智能的一个实现途径
深度学习是机器学习的一个方法发展而来(人工神经网络)

从图上可以看出,人工智能最开始是用于实现人机对弈,到后面的开始处理垃圾邮件过滤【机器学习,机器去模仿人工神经网络】,到最后的图片识别效果显著【深度神经网络,在图像识别中取得好的成绩】,也就是人工智能发展的3个历程。
- 机器学习、深度学习的应用
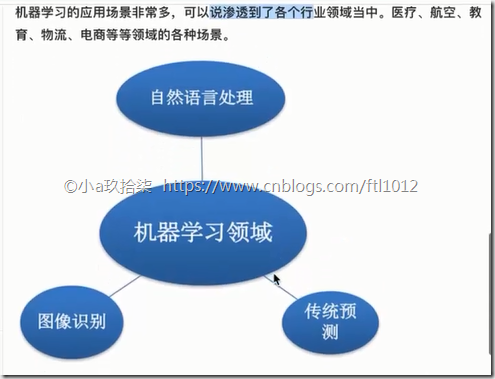
传统预测: 店铺销量预测,移动用户流量消费预测,
图像识别: 人脸识别、无人驾驶
自然语言处理: 英文翻译、文本分类、感情分析、只能客服
02-机器学习
- 什么是机器学习
机器学习就是从数据中自动分析获得模型,并利用模型对未知的数据进行预测
大量的数量 –》 发布预测模型 --》 结果预测

例如,我们将大量的猫图片,利用Py转换为二进制的文件,然后交给机器去学习,去发现一定的规律后,下次机器就可以在大量的图片中发现包含猫的图片。
- 数据集的构成: 特征值 + 目前值
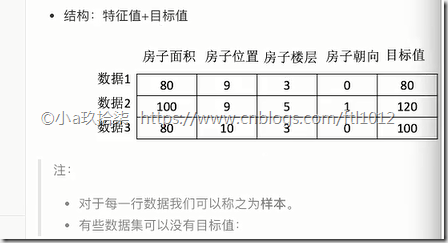
说明:有些数据我们没有目标值,但是也是可以根据他们的特征进行归类(有专门的算法)
03-机器学习算法分类
根据我们机器学习的结果有无目标值分为监督学习和无监督学习。
监督学习根据输入的数据特征分为分类学习和回归学习


监督学习:
目标值:类别 - 分类问题(猫狗的识别)
k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归
目标值:连续型的数据 - 回归问题(房屋价格预测,看做曲线)
线性回归、岭回归无监督学习:
目标值:无 - 无监督学习
聚类 k-means生活案例:
1、预测明天的气温是多少度? 回归
2、预测明天是阴、晴还是雨? 分类
3、人脸年龄预测? 可回归/可分类
4、人脸识别? 分类
04-机器学习开发流程
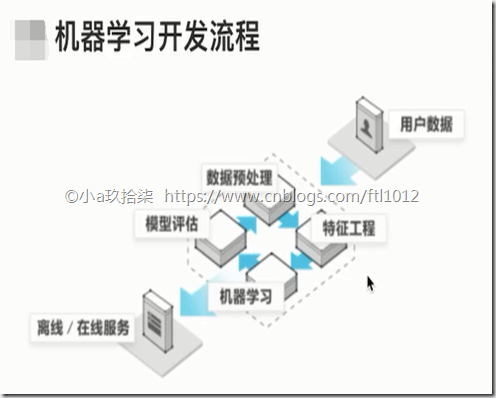
机器学习开发流程:
1)获取数据(数据量越大,数据越精确)
2)数据处理(对不符合要求的数据进行剔除,对不完整的数据进行数据完整)
3)特征工程(把数据处理成符合我们具有特征值的数据)
4)机器学习算法训练 –》 产生模型
5)模型评估(用一系列的方法对产生的模型进行评估,如果符合要求,则继续,否则轮训继续进行数据处理和特征工程)
6)应用(用模型对未知的数据进行预测)

05-学习框架介绍
学习框架和资料介绍:
1)算法是核心,数据与计算是基础【很消耗计算性能,需要能支持它计算的硬件设备,CPU和GPU等】
2)我们做的都是基于专业的算法工程师的基础上进行数据分析、业务分析、常见算法的整合以及结合特征工程进行参数的调优、优化
3) 实战类书籍推荐:
机器学习 -”西瓜书”- 周志华
统计学习方法 - 李航
深度学习 - “花书”
4)开源框架:

06-可用数据集
我们的数据集分为训练集和测试集合,机器学习主要用到了sklearn,下面介绍sklearn数据集
- 可用数据集
互联网公司内部接口: 借用百度
学习阶段可以用的数据集:
1)sklearn
2)kaggle(数据挖掘)
3)UCI(加州大学的一个研究机构)
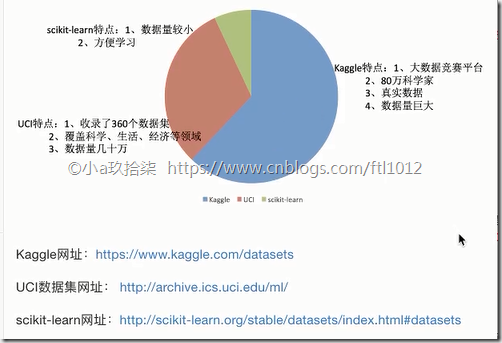
UCI数据集:https://archive.ics.uci.edu/ml/datasets/Iris
- Scikit-learn工具介绍

- Scikit-Learn安装
# 会帮助我们去安装一下中间的插件,例如Numpy, Scipy等库
pip3 install Scikit-learn

- Scikit-learn包含的内容

- sklearn数据集API的使用
load_* 获取小规模数据集,例如后面的鸢尾花, iris = load_iris()
fetch_* 获取大规模数据集

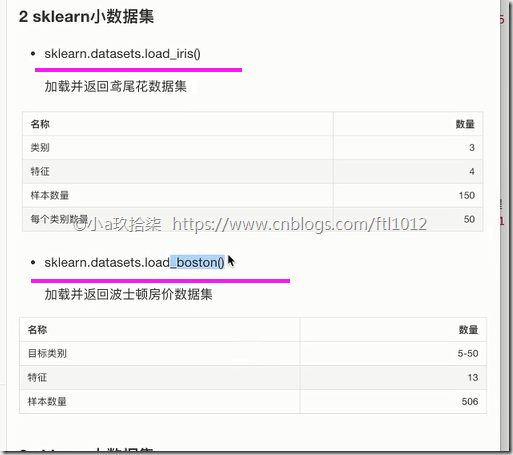
sklearn小数据集(鸢尾花案例)
sklearn.datasets.load_iris()

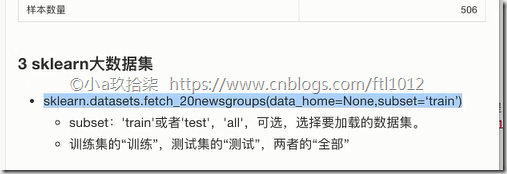
sklearn大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
数据集的返回值
datasets.base.Bunch(继承自字典)
dict["key"] = values
bunch.key = values # 可以根据.属性的方式 获取values值

# 例子1:简单使用
from sklearn.datasets import load_iris
import json
def datasets_demo():
'''
datasets数据集的使用
:return:
'''
iris = load_iris()
print(type(iris.data))
# print("鸢尾花全部数据集:", iris) # 返回值是一个bunch类型
print('查看数据集目标值(利用字典形式)',iris['target_names'])#
# 查看数据集目标值(字典形式) ['setosa' 'versicolor' 'virginica'] print('查收数据集描述信息(利用bunch形式)', iris.DESCR)
'''
=============查收数据集(利用bunch形式)
**Data Set Characteristics:** :Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information: # 花的属性信息
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class: # 目标值,也就是对鸢尾花进行分类
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica :Summary Statistics: # 鸢尾花的信息统计 ============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation(相关系数)
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ==================== :Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
''' print("鸢尾花标本:", iris.data) # 返回时一个ndarray类型,属于numpy类,二维数组
'''
鸢尾花标本:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]]
''' print("查看样本数量:", iris.data.shape) # iris.data是一个numpy.ndarray类型;.shape可以直接看到几行几列
# 查看样本数量: (150, 4) ==》 150个样本,每个样本有4个特征值
return None if __name__ =='__main__':
datasets_demo()
说明:我们获取到的数据不能全部用于训练数据,因为有一部分的数据是需要用来进行对训练出来的模型进行模型评估的。
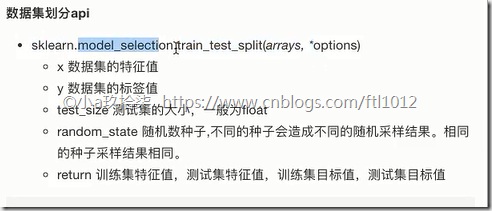
- 数据集的划分

- sklearn中数据集划分API的使用
sklearn.model_selection.train_test_split(arrays, *option)参数:x: 特征值【必须】y: 目标值【必须】test_size: 测试集的大小,一般为浮点数,例如0.2,默认0.25【可选】random_state: 划分数据集的时候,是随机划分的,借助一个随机数种子产生随机,不同的随机数种子产生的结果是不一样的【可选】返回值:x_train, x_test, y_train, y_test训练集特征值、测试集特征值、训练集目标值、测试集目标值
完整版Demo
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
def datasets_demo(): iris = load_iris()
print('查看数据集目标值(利用字典形式)',iris['target_names'])#
print('查收数据集描述信息(利用bunch形式)', iris.DESCR)
print("鸢尾花标本:", iris.data) # 返回时一个ndarray类型,属于numpy类,二维数组
print("查看特征值:", iris.data) # iris.data是一个numpy.ndarray类型;.shape可以直接看到几行几列,共计150,4
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=2019)
print('训练集的特征值x_train', x_train)
print('训练集的特征值x_train有多少行多少列', x_train.shape) # (120,4) 即150*0.8
print('测试集的特征值x_test', x_test) return None if __name__ =='__main__':
datasets_demo()
AI学习--机器学习概述的更多相关文章
- DeepLearning.ai学习笔记(三)结构化机器学习项目--week2机器学习策略(2)
一.进行误差分析 很多时候我们发现训练出来的模型有误差后,就会一股脑的想着法子去减少误差.想法固然好,但是有点headlong~ 这节视频中吴大大介绍了一个比较科学的方法,具体的看下面的例子 还是以猫 ...
- 一张图看懂AI、机器学习和深度学习的区别
AI(人工智能)是未来,是科幻小说,是我们日常生活的一部分.所有论断都是正确的,只是要看你所谈到的AI到底是什么. 例如,当谷歌DeepMind开发的AlphaGo程序打败韩国职业围棋高手Lee Se ...
- 学习笔记DL002:AI、机器学习、表示学习、深度学习,第一次大衰退
AI早期成就,相对朴素形式化环境,不要求世界知识.如IBM深蓝(Deep Blue)国际象棋系统,1997,击败世界冠军Garry Kasparov(Hsu,2002).国际象棋,简单领域,64个位置 ...
- AI学习笔记:特征工程
一.概述 Andrew Ng:Coming up with features is difficult, time-consuming, requires expert knowledge. &quo ...
- DeepLearning.ai学习笔记汇总
第一章 神经网络与深度学习(Neural Network & Deeplearning) DeepLearning.ai学习笔记(一)神经网络和深度学习--Week3浅层神经网络 DeepLe ...
- AI 学习路线
[导读] 本文由知名开源平台,AI技术平台以及领域专家:Datawhale,ApacheCN,AI有道和黄海广博士联合整理贡献,内容涵盖AI入门基础知识.数据分析挖掘.机器学习.深度学习.强化学习.前 ...
- AI - 学习路径(Learning Path)
初见 机器学习图解 错过了这一篇,你学机器学习可能要走很多弯路 这3张脑图,带你清晰人工智能学习路线 一些课程 Andrew Ng的网络课程 HomePage:http://www.deeplearn ...
- AI学习吧
一:AI学习吧 项目描述 系统使用前后端分离的模式,前端使用vue框架,后端使用restframework实现. 项目需求 公司开发AI学习吧,由于公司需要一款线上学习平台,要开发具有线上视频学习.支 ...
- AI学习经验总结
我的人工智能学习之路-从无到有精进之路 https://blog.csdn.net/sinox2010p1/article/details/80467475 如何自学人工智能路径规划(附资源,百分百亲 ...
随机推荐
- Perl和操作系统交互(二):fork
fork + exec fork是低层次的系统调用,通过复制父进程来创建子进程. fork的行为 fork用来拷贝当前进程,生成一个基本完全一样的子进程. my $pid=fork(); 如果fork ...
- Go Web:URLs
URL也是一个结构体: type URL struct { Scheme string Opaque string // encoded opaque data User *Userinfo // u ...
- 翻译:insert on duplicate key update(已提交到MariaDB官方手册)
本文为mariadb官方手册:INSERT ON DUPLICATE KEY UPDATE的译文. 原文:https://mariadb.com/kb/en/insert-on-duplicate-k ...
- Docker之使用Dockerfile创建定制化镜像(四)--技术流ken
前言 在之前的博客<Docker端口映射及创建镜像演示(二)--技术流ken>,演示了如何使用一个现有容器创建一个镜像,以及镜像在阿里云的上传和下载. 但是这样的镜像有很大的局限性,不能根 ...
- 【golang-GUI开发】qt之signal和slot(一)
想了很久,我决定还是先从signal和slot(信号槽)开始讲起. signal和slot大家一定不陌生,先看一段示例(选自文档): class Counter : public QObject { ...
- Tree View控件(添加,移除,设置图标)
添加 父节点,并为父节点添加子节点 private void button1_Click(object sender, EventArgs e) { TreeNode tn1 = treeView1. ...
- PHP生成器细说
之前写过关于生成器的文章,可能还不够详细,正好群里有朋友在讨论.觉得还是有必要再细说下,如果大家做过Python或者其他语言的,对于生成器应该不陌生.生成器是PHP 5.5.才引入的功能,也许大家觉得 ...
- python_文件操作
说明:如有转载,请标明出处!! 一.文件操作 1.文件常用操作方法 open() f=open('文件名','r',encoding='utf-8') #三个参数,第一个文件详细路径,需要写明文件格式 ...
- python面向对象学习(七)单例
目录 1. 单例设计模式 单例设计模式的应用场景 2. __new__ 方法 3. Python 中的单例 只执行一次初始化工作 1. 单例设计模式 设计模式 设计模式 是 前人工作的总结和提炼,通常 ...
- java多线程高并发
旭日Follow_24 的CSDN 博客 ,全文地址请点击: https://blog.csdn.net/xuri24/article/details/81293321 “高并发和多线程”总是被一起提 ...