Python request库与爬虫框架
Requests库的7个主要方法
requests.request():构造一个请求,支持以下各方法的基础方法
requests.get():获取HTML网页的主要方法,对应于HTTP的GET
requests.head():获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post():向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put():向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch():向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete():向HTML网页提交删除请求,对应于HTTP的Delete
HTTP协议对资源的操作(6种)与以上方法一一对应
GET:请求URL位置的资源
HEAD:请求获取URL位置资源的响应消息报告,即获得该资源的头部信息
POST:请求向URL位置的资源后附加新的数据
PUT:请求向URL位置存储一个资源,覆盖原URL位置的资源
PATCH:请求局部更新URL位置的资源,即改变该处资源的部分内容
DELETE:请求删除URL位置存储的资源
【注】PATCH和PUT的区别
假设URL位置有一组数据UserInfo,包括UserID,UserName等20个字段
需求:用户修改了UserName,其他不变
*采用PATCH方法,仅向URL提交UserName的局部更新请求
*采用PUT方法,由于他会覆盖原有URL位置资源,
所以必须将所有20个字段一并提交到URL,未提交字段被删除
比较PATCH和PUT看出
Patch的最主要好处:节省网络带宽
HTTP协议:HypertextTransferProtocol,超文本传输协议
它是一个基于"请求与相应"模式的、
无状态的(第一次请求和第二次无相关关联)应用层协议
它一般采用URL作为网络资源的标识
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
URL格式如下 http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号,缺省(默认)端口为80P
path:请求资源的路径
当我们向URLPOST一个字典或POST一个键值对时会默认地被存储到表单form的字段下
当我们向URLPOST字符串时会默认地被存储到data的字段下
服务器会根据提交的数据类型不同进行相关的整理
PUT方法相同,但是会把原有数据覆盖掉
'''
requests.request(method,url,**kwargs)
method:请求方式,对应get/put/post等7种
requests.request('GET',url,**kwargs)
requests.request('HEAD',url,**kwargs)
requests.request('POST',url,**kwargs)
requests.request('PUT',url,**kwargs)
requests.request('PATCH',url,**kwargs)
requests.request('delete',url,**kwargs)
requests.request('OPTIONS',url,**kwargs)
#向服务器获取一些与客户端打交道的参数,不与资源直接相关所以使用较少
url:拟获取页面的url链接
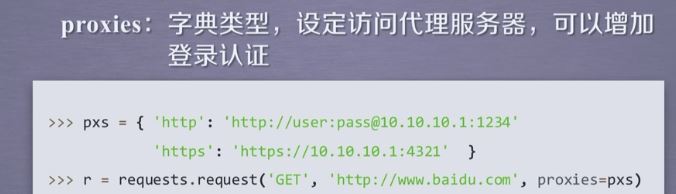
**kwargs:控制访问参数,共13个

'''







#显式定义的参数放在了形参里面,不怎么用的放在了可选里面
'''
###########################最常用
requests.get(url,params=None,**kwargs)
url:拟获取页面的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问参数(request方法中除了param之外的12个)
'''
'''
requests.head(url,**kwargs)
url:拟获取页面的url链接
**kwargs:13个控制访问参数
'''
'''
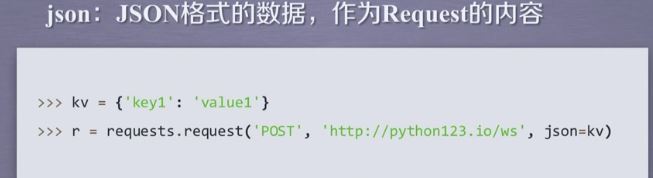
requests.post(url,data=None,json=None,**kwargs)
url:拟获取页面的url链接
data:字典、字节序列或文件,Request的内容
json:JSON格式的数据,Request的内容
**kwargs:11个控制访问参数(除了以上两个的11个)
'''
'''
requests.put(url,data=None,**kwargs)
url:拟获取页面的url链接
data:字典、字节序列或文件,Request的内容
**kwargs:12个控制访问参数(除了以上1个的12个)
'''
'''
requests.patch(url,data=None,**kwargs)
url:拟获取页面的url链接
data:字典、字节序列或文件,Request的内容
**kwargs:12个控制访问参数(除了以上1个的12个)
'''
'''
requests.delete(url,**kwargs)
url:拟获取页面的url链接
**kwargs:13个控制访问参数
'''
'''
爬取网页的通用代码框架
通用代码框架:一组代码,可以准确的爬取网页上的内容
用request库进行网页访问的时候经常用get函数
requests.get(url)获得url的相关内容
但是网络连接有风险
这样的语句并不是一定成立的,所以异常处理很重要
request库支持6种常用的连接异常
'''
#request.ConnectionError:网络连接异常,如DNS查询失败、拒绝连接等
#request.HTTPError:HTTP错误异常
#request.URLRequired:URL缺失异常
#request.TooManyRedirects:超过最大重定向次数,产生重定向异常
#request.ConnectTimeout:连接远程服务器超时异常
#request.TimeOut:请求URL超时,产生超时异常
'''
Response类与异常打交道的方法
r.raise_for_status():如果不是200,产生异常request.HTTPError
判断返回的response类型状态是不是200
'''
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout = 30)#,timeout = 30
r.raise_for_status()#如果状态不是200,引发HTTPError异常
r.encoding = r.apparent_encoding
#防乱码
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))



Python request库与爬虫框架的更多相关文章
- Python的两个爬虫框架PySpider与Scrapy安装
Python的两个爬虫框架PySpider与Scrapy安装 win10安装pyspider: 最好以管理员身份运行CMD,不然可能会出现拒绝访问文件夹的情况! pyspider:pip instal ...
- Python + request + unittest实现接口测试框架
1.为什么要写代码实现接口自动化 大家知道很多接口测试工具可以实现对接口的测试,如postman.jmeter.fiddler等等,而且使用方便,那么为什么还要写代码实现接口自动化呢?工具虽然方便,但 ...
- python接口自动化28-requests-html爬虫框架
前言 requests库的好,只有用过的人才知道,最近这个库的作者又出了一个好用的爬虫框架requests-html.之前解析html页面用过了lxml和bs4, requests-html集成了一些 ...
- Python+Request库+第三方平台实现验证码识别示例
1.登录时经常的出现验证码,此次结合Python+Request+第三方验证码识别平台(超级鹰识别平台) 2.首先到超级鹰平台下载对应语言的识别码封装,超级鹰平台:http://www.chaojiy ...
- 【转】Python练习,网络爬虫框架Scrapy
一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程. 二.组件 1.Scrapy Engine(S ...
- python Request库
命令行查看版本:python --version pip --version pip常用命令// 安装包pip install xxx// 升级包pip install -U xxx// 卸载包pip ...
- python request 库
快速上手 迫不及待了吗?本页内容为如何入门Requests提供了很好的指引.其假设你已经安装了Requests.如果还没有, 去 安装 一节看看吧. 首先,确认一下: Requests 已安装 Req ...
- 介绍一款能取代 Scrapy 的 Python 爬虫框架 - feapder
1. 前言 大家好,我是安果! 众所周知,Python 最流行的爬虫框架是 Scrapy,它主要用于爬取网站结构性数据 今天推荐一款更加简单.轻量级,且功能强大的爬虫框架:feapder 项目地址: ...
- python第三方库,你要的这里都有
Python的第三方库多的超出我的想象. python 第三方模块 转 https://github.com/masterpy/zwpy_lst Chardet,字符编码探测器,可以自动检测文本. ...
随机推荐
- 使用Dockerfile自定义一个包含centos,tomcat的镜像
1.首先建立一个专用的dockerfile目录,方便统一存放将要创建的Dockerfile文件及相关资源, 例如:mkdir mydockerself 2.定位到mydockerself路径下,下载l ...
- React-Native android 开发者记录
1.安装 安装步骤不多废话,按照官网步骤执行即可 安装完之后,react-native run-android发现报错,页面出不来 Error: Unable to resolve module `. ...
- 域名系统DNS以及跨域问题
域名到Ip地址解析是由分布在因特网上的许多域名服务器程序共同完成的.运行域名服务器程序的机器是域名服务器 域名到ip地址的解析过程: 当一个应用进程需要把主机名解析为ip地址时,该应用就调用解析程 ...
- centos7下Etcd3集群搭建
一.环境介绍 etcd主要功能是分布式的存储键值,优点不多说了,分布是集群,自动选举等等,自行百度,主要说下配置方法,折腾了几天,终于优点眉目了,记录下操作方法,本文参考了如下链接 https://w ...
- PowerScript语句
赋值语句 赋值语句可以把一个表达式的结果或者变量和常量的值,赋给一个变量或者对象的属性或成员变量.赋值语句的格式是: variablename = expression 其中variablename代 ...
- 100-days: twenty-seven
Title: Criticism for China's child modeling(代指从事模特行业的人) industry after video of 3-year-old being kic ...
- B/S架构与C/S架构
一,概念: 首先软件体系结构定义了软件的局部和总体计算的构成,以及这些部件之间的相互作用关系.部件包括诸如服务器,客户,数据库,过滤器,程序包,过程,子程序等一切软件的 组成成分. C/ ...
- php 积分抽奖活动(大转盘)
以下是项目代码(公众号,使用积分进行抽奖活动),只可做参考: public function Sncode(){ $tid = I('request.tid', 0, 'intval'); // 大转 ...
- 手机设备上touchstart与click的区别
1.基本定义 touchstart 手指触碰开始就能触发 click 1.手指触碰 2.手指未在屏幕上移动 3.在这个dom上手指离开屏幕 4.触摸和离开屏幕之间的时间间隔较短 因此,click事件有 ...
- SpringBoot集成MongoDB
前言 之前写了各种nosql数据库的比较,以及相关理论,现在我在本地以springboot+MongoDB框架,探究了具体的运行流程,下面总结一下,分享给大家. 运行前准备 安装并启动MongoDB应 ...