HBase简介及原理
HBase简介
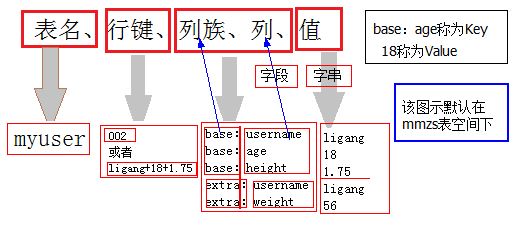
1、HBase是一个万亿行,百万列大表(Big Table),数据存放在hdfs集群中;
写操作使用MapReduce处理,将(增删改)处理结果放入HBase中,读就直接读HBase;
HBase的并发量在1000左右,常用的关系型数据库MySql的并发量在300~500之间,之所以HBase的并发量比较大,原因在于HBase启用了缓存技术;
HBase中的块的单位是64k,每次读取数据,以块为单位将hdfs集群中的数据加载到内存中,加载到内存中的数据形同一个散列表,散列表以Key-Value的键值对方式存储;
HDFS中存储的数据受到HBase的元数据管理,这种管理方式与Hive雷同,即HBase通过Zookeeper集群管理元数据,通过HDFS集群管理业务数据。
2、数据存储以Region作为单位(行的集合),一个Region的默认大小为128M;
3、因为HBase是基于键值对(读时以块为单位读)的一个NOSQL数据库,Redis的读写纯粹是基于键值对,Redis的并发量在十万左右,并发能力高,
但没有副本机制,数据容易丢失;而HBase基于HDFS集群,具有副本机制,数据安全度高;
4、使用关联评估算法(属于机器学习)
5、HBase是一个构建在HDFS上的分布式列存储系统;
HBase是基于Google BigTable模型开发的;
HBase是Apache Hadoop生态系统中的重要一员,主要用于海量结构化数据存储;
从逻辑上讲,HBase将数据按照表、行和列进行存储。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Hbase表的特点
大:一个表可以有数十亿行,上百万列;
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
面向列:面向列(族)的存储和权限控制,列(族)独立检索;
稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
数据类型单一:Hbase中的数据都是字符串,没有类型。
HBase架构原理
大数据学习交流QQ群:217770236 让我们一起学习大数据
1、客户端链接zookeeper集群,申请写数据
2、zookeeper返回一个地址列表给客户端
3、客户端根据地址列表链接slave节点写数据,并反馈状态
------------slave节点会主动上报存储状态及工况信息到master
------------master则主动将元数据上报zookeeper集群
4、客户端告知zookeeper记录和状态
HBase简介及原理的更多相关文章
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- Hbase架构与原理(转)
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利 ...
- HBase简介
HBase简介 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群. HB ...
- Hbase的架构原理、核心概念
Hbase的架构原理.核心概念 1.Hbase的表.行.列.列族 2.核心组件: Table和region Table在行的方向上分割为多个HRegion, 一个region由[startkey,en ...
- HBase底层存储原理
HBase底层存储原理——我靠,和cassandra本质上没有区别啊!都是kv 列存储,只是一个是p2p另一个是集中式而已! 首先HBase不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数 ...
- hbase学习(一)hbase简介
1.hadoop生态系统 2.hbase简介 非关系型数据库知识面扩展 cassandra.hbase.mongodb.redis couchdb,文件存储数据库 Neo4j非关系型图数据库 3.hb ...
- HBase 学习之路(一)—— HBase简介
一.Hadoop的局限 HBase是一个构建在Hadoop文件系统之上的面向列的数据库管理系统. 要想明白为什么产生HBase,就需要先了解一下Hadoop存在的限制?Hadoop可以通过HDFS来存 ...
- Linux系统学习 十二、VSFTP服务—简介与原理
1.简介与原理 互联网诞生之初就存在三大服务:WWW.FTP.邮件 FTP主要针对企业级,可以设置权限,对不同等级的资料针对不同权限人员显示. 但是像网盘这样的基本没有权限划分. 简介: FTP(Fi ...
- 【转帖】HBase简介(梳理知识)
HBase简介(梳理知识) https://www.cnblogs.com/muhongxin/p/9471445.html 一. 简介 hbase是bigtable的开源山寨版本.是建立的hdf ...
随机推荐
- ACM计划
原文 :http://027xbc.blog.163.com/blog/static/128159658201141371343475/ ACM主要是考算法的,主要时间是花在思考算法上,不是花在写程序 ...
- java.lang.OutOfMemoryError: PermGen space (jvm内存泄漏解决办法)
2.在myeclipse根目录 打开myeclipse.ini 3.在myeclipse中配置内存
- 《Java性能调优》学习笔记(1)
性能的参考指标 执行时间 -- 从代码开始运行到结束的时间 CPU时间 -- 函数或者线程占用CPU的时间 内存分配 -- 程序在运行时占用内存的情况 磁盘吞吐量 -- 描述IO的使用情况 网络吞吐量 ...
- MySQL--MHA与GTID
##==========================================## MySQL 5.6版本引入GTID来解决主从切换时BINLOG位置点难定位的问题,MHA从0.56版本开始 ...
- [升级说明] Senparc.Weixin.MP v14.8.11 (微信群发接口调整)
升级内容:添加根据标签群发接口,重构原根据分组群发接口 参考微信文档:https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp14811 ...
- [转]Kaldi语音识别
转:http://ftli.farbox.com/post/kaldizhong-wen-shi-bie Kaldi语音识别 1.声学建模单元的选择 1.1对声学建模单元加入位置信息 2.输入特征 3 ...
- Eclipse 在高分辨率4K显示器下图标按钮过小
买了LG的4K显示器,发现由于分辨率太高,导致好多软件和网站都没进行高分辨率适配,显示比较小,缩放会使好多软件都显示错位.Eclipse就是其中之一. 网上搜了下解决方案如下: 原理 高DPI Win ...
- redis订阅关闭异常解决
redis订阅关闭异常解决 应用程序模块订阅redis运行一段时间出现一直重连Redis服务,日志如下: 2019-04-28 10:06:17,551 ERROR org.springframewo ...
- Centos 基本命令不能用恢复方法
遇到命令都不能用,直接执行下面的语句就可以: export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/roo ...
- 用excel记录测试bug问题总结
前几天与开发在讨论问题的时候,开发提了一个问题,说是已经解决的问题,能否用excel表格总结一下,问了一下原因,感觉想法很好,就总结了一下. 在上家公司的时候,提交bug用的是mantis,现在是禅道 ...