【JUC源码解析】PriorityBlockingQueue
简介
基于数据结构堆实现的线程安全的无界队列,这个堆的内存结构是数组,结合了数组和二叉树的特点。
堆
以下内容参考《编程珠玑》和《算法导论》有关堆的章节。
数据结构
堆是用来表示元素集合的一种数据结构。
性质
顺序,任何结点的值都小于(大或于)等于其子结点的值。
形状,是一个数组,却可以被看成一个近似的完全二叉树,除了底层外,该树是完全充满的,而且是从左往右填充。

如上图所示,堆使用的是从下标1开始的数组,常见的方法如下:
root = 1
value(i) = x[i]
leftChild(i) = 2*i
rightChild(i) = 2*i + 1
parent(i) = i/2
null(i) = (i < 1) || (i > n)
heap(l, u) 定义如下:
x[i/2] <= x[i], (2*l <= x <= u)
关键方法
siftUp
heap(1,n-1) -> heap(1,n)
当x[1..n-1]是一个堆时,在x[n]中放置一个任意元素可能无法产生heap(1,n),可以使用siftUp函数来重新获得堆性质
尽可能地将新元素向上筛选(交换该结点与其父结点),树的根为x[1],位于树的顶部,x[n]位于数组的底部。
下图(从上到下)演示了新元素13在堆中向上筛选,直到到达合适的位置(这里是成为了根的右子结点)的过程。
步骤一,添加新元素13,橙色结点
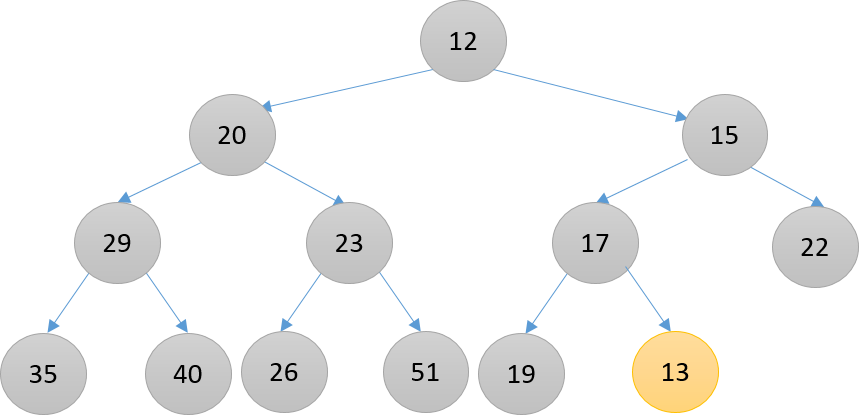
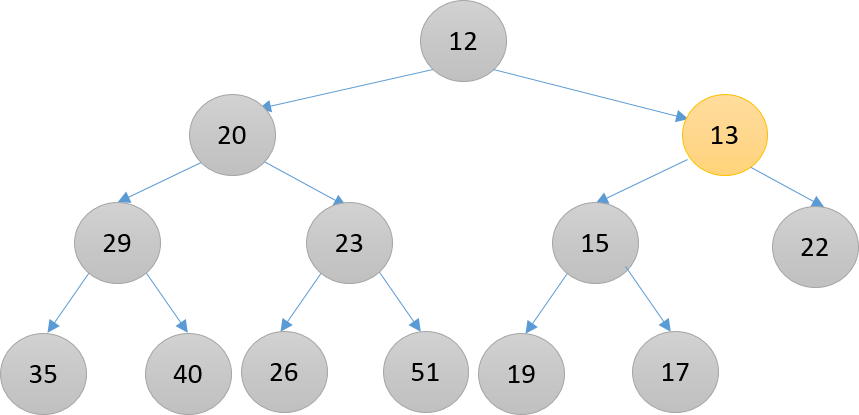
步骤二,比17小,与其父结点17进行交换

步骤三,比15小,与其父节点15结点,到达合适位置(比12大)
代码实现siftUp方法,这里用Java语言实现
它的运行时间和logn成正比,因为堆具有logn层。
void siftUp(int index, int key, int[] array) {
while (index > 0) { // index是新增元素初始时下标,也是数组元素中最大的有效元素下标
int parent = (index - 1) >>> 1; // 其父结点元素下标
int e = array[parent]; // 取出父结点的元素值
if (key > e) // 和当前元素比较
break; // 若当前元素大于其父元素,则达到合适的位置,跳出循环
array[index] = e; // 若当前元素小于等于其父元素,设置index下标上的元素为其父结点元素的值e
index = parent; // 索引上移,继续比较
}
array[index] = key; // 将新元素放在合适的位置,index的最后更新值
}
siftDown
heap(1,n) -> heap(2,n)
当x[1..n]是一个堆时,给x[1]分配一个新值得到heap(2,n),然后调用siftDown使得heap(1,n)为真。
该函数将x[1]向下筛选,直到它没有子结点或小于等于它的子结点
下图(从上到下)演示了18在堆中向下筛选,直到到达合适的位置的过程。
x[1]替换为新元素18
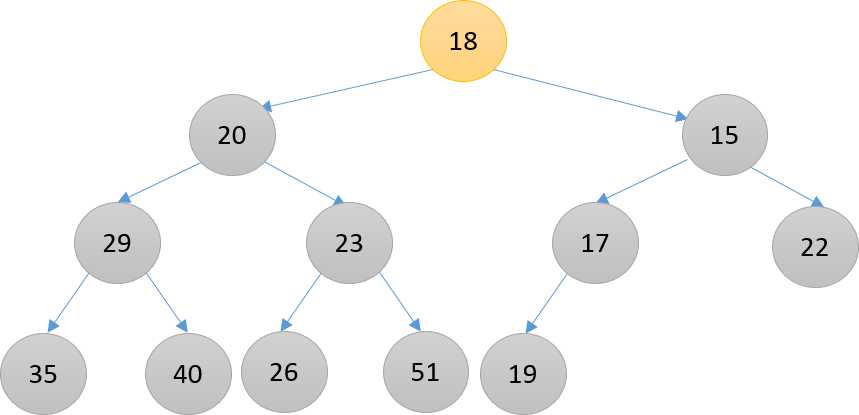
比其右子结点15大,并与其交换
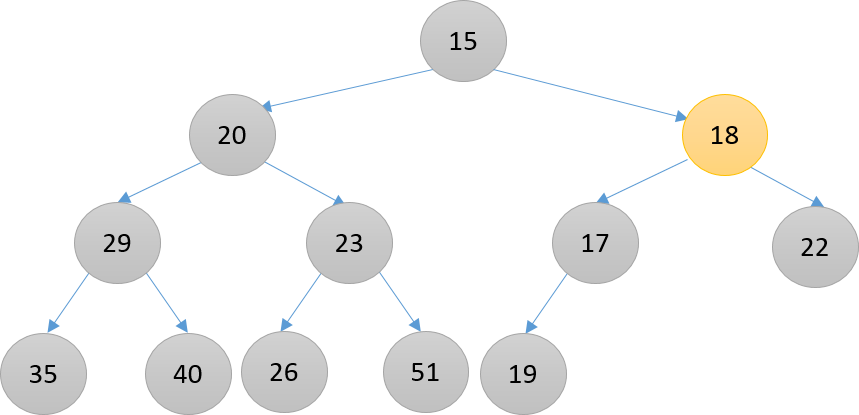
比其左子结点17大,并与其交换,此刻到达合适的位置(比其左子结点19小,没有右子结点)

代码实现siftDown方法,这里用Java语言实现
它的运行时间和logn成正比,因为堆具有logn层。
void siftDown(int index, int key, int[] array, int n) {
if (n > 0) { // n为元素的个数, half = n/2, 表示最后一个拥有子结点的元素结点,index下沉至half的子结点便到底了,所以有while(index < half)
int half = n >>> 1; // 取中间索引作为终结点
while (index < half) {
int child = (index << 1); // 左子结点索引,【注意】,如果索引0处也用的话,这里应改为,int child = (index << 1) + 1;
int c = array[child]; // 左子结点的值
int right = child + 1; // 右子结点索引
if (right < n && c > array[right]) // 如果右子结点索引没有越界,且左子结点的值大于右子结点的值,则更新c和child分别为其右子结点的值和索引
c = array[child = right];
if (key <= c) // 若key小于等于c,说明已经找到合适位置,则跳出循环
break;
array[index] = c; // 若当前元素大于其子结点元素,设置index下标上的元素为其父结点元素的值
index = child; // 索引下移,继续比较
}
array[index] = key; // 将新元素放在合适的位置,index的最后更新值
}
}
siftUp方法和siftDown方法分别对应了插入和删除元素。
源码分析
属性
private static final int DEFAULT_INITIAL_CAPACITY = 11; // 默认容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 最大容量
private transient Object[] queue; // 数组
private transient int size; // 大小
private transient Comparator<? super E> comparator; // 比较器
private final ReentrantLock lock; // 可重入锁
private final Condition notEmpty; // 条件
private transient volatile int allocationSpinLock;
private PriorityQueue<E> q; // 这里仅用于序列化
构造方法
public PriorityBlockingQueue() { // 构造方法,默认容量,无比较器
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityBlockingQueue(int initialCapacity) { // 给定容量,无比较器
this(initialCapacity, null);
}
public PriorityBlockingQueue(int initialCapacity, Comparator<? super E> comparator) { // 给定容量,给定比较器
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
this.comparator = comparator;
this.queue = new Object[initialCapacity];
}
public PriorityBlockingQueue(Collection<? extends E> c) { // 给定集合
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
boolean heapify = true; // 是否需要调整顺序
boolean screen = true; // 是否需要检查空值
if (c instanceof SortedSet<?>) { // 有序集合
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator(); // 获取比较器
heapify = false; // 已经有序,无需调整
} else if (c instanceof PriorityBlockingQueue<?>) { // 优先级阻塞队列的实例
PriorityBlockingQueue<? extends E> pq = (PriorityBlockingQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator(); // 获取比较器
screen = false; // 不必检查空值
if (pq.getClass() == PriorityBlockingQueue.class) // 类型是优先级阻塞队列
heapify = false; // 无需调整顺序
}
Object[] a = c.toArray(); // 取得其数组,真正保存内容的数据结构
int n = a.length; // 数组长度
if (a.getClass() != Object[].class) // 若不是Object类型
a = Arrays.copyOf(a, n, Object[].class); // 复制一份,使其成为Object类型
if (screen && (n == 1 || this.comparator != null)) { // 需要检查null
for (int i = 0; i < n; ++i)
if (a[i] == null)
throw new NullPointerException();
}
this.queue = a;
this.size = n;
if (heapify)
heapify(); // 调整堆,使其符合堆的性质
}
关键方法
heapify()
private void heapify() {
Object[] array = queue; // 数组
int n = size; // 大小
int half = (n >>> 1) - 1; // 只需要调整前一半元素即可,后面的都是叶子节点,无需调整
Comparator<? super E> cmp = comparator; // 比较器
if (cmp == null) { // 若比较器不存在,则使用元素自身的比较器
for (int i = half; i >= 0; i--)
siftDownComparable(i, (E) array[i], array, n);
} else { // 否则,使用比较器比较
for (int i = half; i >= 0; i--)
siftDownUsingComparator(i, (E) array[i], array, n, cmp);
}
}
siftUp()
private static <T> void siftUpComparable(int k, T x, Object[] array) { // 向上调整,使用元素自身比较器
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) {
int parent = (k - 1) >>> 1; // 索引减半,即是父节点索引,注意,这里,索引是从0开始的,所以是k-1
Object e = array[parent]; // 父节点的值
if (key.compareTo((T) e) >= 0) // 大于其父节点,说明已到合适位置,跳出循环
break;
array[k] = e; // 当前索引设置父节点的值
k = parent; // 索引上移动
}
array[k] = key; // key最后放在合适的索引位置
}
private static <T> void siftUpUsingComparator(int k, T x, Object[] array, Comparator<? super T> cmp) { // 同上,使用给定的比较器
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (cmp.compare(x, (T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = x;
}
siftDown()
private static <T> void siftDownComparable(int k, T x, Object[] array, int n) { // 向下调整,使用元素自身的比较器
if (n > 0) {
Comparable<? super T> key = (Comparable<? super T>) x;
int half = n >>> 1; // 只调整到前一半元素即可,后一半均是叶子节点,无需调整
while (k < half) {
int child = (k << 1) + 1; // 左子节点,索引从0开始,所以需要+1
Object c = array[child];
int right = child + 1; // 右子节点
if (right < n && ((Comparable<? super T>) c).compareTo((T) array[right]) > 0) // 如果右子结点索引没有越界,且左子结点的值大于右子结点的值,则更新c和child分别为其右子结点的值和索引
c = array[child = right];
if (key.compareTo((T) c) <= 0) // 若key小于等于c,说明已经找到合适位置,则跳出循环
break;
array[k] = c; // 若当前元素大于其子结点元素,设置index下标上的元素为其父结点元素的值
k = child; // 索引下移,继续比较
}
array[k] = key; // 将新元素放在合适的位置,k的最后更新值
}
}
private static <T> void siftDownUsingComparator(int k, T x, Object[] array, int n, Comparator<? super T> cmp) { // 同上,使用给定的比较器
if (n > 0) {
int half = n >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = array[child];
int right = child + 1;
if (right < n && cmp.compare((T) c, (T) array[right]) > 0)
c = array[child = right];
if (cmp.compare(x, (T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = x;
}
}
tryGrow(Object[] array, int oldCap)
private void tryGrow(Object[] array, int oldCap) { // 扩容
lock.unlock(); // 释放offer方法里加的锁
Object[] newArray = null;
if (allocationSpinLock == 0 && UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset, 0, 1)) { // 自旋锁,50%的概率,因为已经释放锁了,这里用CAS保证只有一个线程能扩容成功
try {
int newCap = oldCap + ((oldCap < 64) ? (oldCap + 2) : // 小于64时,快速增长(oldCap+2),大于等于64,增长缓慢(oldCap/2)
(oldCap >> 1));
if (newCap - MAX_ARRAY_SIZE > 0) { // 检查内存溢出
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array) // 如果没有别的线程抢先扩容,则创建新数组
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) // 扩容失败,让出CPU时间片
Thread.yield();
lock.lock(); // 继续往下执行,如果是让出CPU时间片的线程先获得了锁,等其执行结束,会在offer方法里重新释放锁的
if (newArray != null && queue == array) { // 加锁,扩容
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
如果元素数量 大于等于数组长度,则扩容。
offer(E e)
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
while ((n = size) >= (cap = (array = queue).length)) // 元素数量大于等于数组长度,扩容,无界
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
if (cmp == null)
siftUpComparable(n, e, array); // 添加元素,自底向上调整
else
siftUpUsingComparator(n, e, array, cmp);
size = n + 1; // 数量加1
notEmpty.signal(); // 通知等待拿元素的线程
} finally {
lock.unlock();
}
return true;
}
添加元素,自底向上调整。
dequeue()
private E dequeue() {
int n = size - 1;
if (n < 0)
return null;
else {
Object[] array = queue;
E result = (E) array[0]; // 取优先级最高的首元素
E x = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
siftDownComparable(0, x, array, n); // 删除是自顶向下调整
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
返回优先级最高的元素,也即是数组首元素。
take()
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
while ( (result = dequeue()) == null)
notEmpty.await(); // 阻塞,等待被唤醒
} finally {
lock.unlock();
}
return result;
}
调用take方法的线程,遇到队列为空,则会被添加到Condition队列中,等待被唤醒。
行文至此结束。
尊重他人的劳动,转载请注明出处:http://www.cnblogs.com/aniao/p/aniao_pbq.html
【JUC源码解析】PriorityBlockingQueue的更多相关文章
- 【JUC源码解析】ScheduledThreadPoolExecutor
简介 它是一个线程池执行器(ThreadPoolExecutor),在给定的延迟(delay)后执行.在多线程或者对灵活性有要求的环境下,要优于java.util.Timer. 提交的任务在执行之前支 ...
- 【JUC源码解析】SynchronousQueue
简介 SynchronousQueue是一种特殊的阻塞队列,该队列没有容量. [存数据线程]到达队列后,若发现没有[取数据线程]在此等待,则[存数据线程]便入队等待,直到有[取数据线程]来取数据,并释 ...
- 【JUC源码解析】ForkJoinPool
简介 ForkJoin 框架,另一种风格的线程池(相比于ThreadPoolExecutor),采用分治算法,工作密取策略,极大地提高了并行性.对于那种大任务分割小任务的场景(分治)尤其有用. 框架图 ...
- 【JUC源码解析】DelayQueue
简介 基于优先级队列,以过期时间作为排序的基准,剩余时间最少的元素排在队首.只有过期的元素才能出队,在此之前,线程等待. 源码解析 属性 private final transient Reentra ...
- 【JUC源码解析】CyclicBarrier
简介 CyclicBarrier,一个同步器,允许多个线程相互等待,直到达到一个公共屏障点. 概述 CyclicBarrier支持一个可选的 Runnable 命令,在一组线程中的最后一个线程到达之后 ...
- 【JUC源码解析】ConcurrentLinkedQueue
简介 ConcurrentLinkedQueue是一个基于链表结点的无界线程安全队列. 概述 队列顺序,为FIFO(first-in-first-out):队首元素,是当前排队时间最长的:队尾元素,当 ...
- 【JUC源码解析】Exchanger
简介 Exchanger,并发工具类,用于线程间的数据交换. 使用 两个线程,两个缓冲区,一个线程往一个缓冲区里面填数据,另一个线程从另一个缓冲区里面取数据.当填数据的线程将缓冲区填满时,或者取数据的 ...
- Jdk1.6 JUC源码解析(12)-ArrayBlockingQueue
功能简介: ArrayBlockingQueue是一种基于数组实现的有界的阻塞队列.队列中的元素遵循先入先出(FIFO)的规则.新元素插入到队列的尾部,从队列头部取出元素. 和普通队列有所不同,该队列 ...
- Jdk1.6 JUC源码解析(13)-LinkedBlockingQueue
功能简介: LinkedBlockingQueue是一种基于单向链表实现的有界的(可选的,不指定默认int最大值)阻塞队列.队列中的元素遵循先入先出 (FIFO)的规则.新元素插入到队列的尾部,从队列 ...
随机推荐
- POJ3690 Constellations
嘟嘟嘟 哈希 刚开始我一直在想二维哈希,但发现如果还是按行列枚举的话会破坏子矩阵的性质.也就是说,这个哈希只能维护一维的子区间的哈希值. 所以我就开了个二维数组\(has_{i, j}\)表示原矩阵\ ...
- python沙箱逃逸的几道题
第一道 from __future__ import print_function print("Welcome to my Python sandbox! Enter commands b ...
- [转]TortoiseSVN客户端的安装
TortoiseSVN是windows平台下Subversion的免费开源客户端. 一般我们都是先讲讲服务器的配置,然后再讲客户端的使用,但是在TortoiseSVN上,却可以反过来.因为,如果你的要 ...
- 修改linux系统的默认语言
修改linux系统的默认语言: 1.全局修改: 所有用户都是同一种统一的语言设置 修改/etc/sysconfig/i18n文件 vi /etc/s ...
- Linux下Java性能监控
Linux下Java性能监控 一.JVM堆内存使用监控 获取thread dump的3种方法: 1)使用$JAVA_HOME/bin/jcosole中的MBean,到MBean>com.sun. ...
- 算法的泛化过程(摘自《STL源码剖析》)
将一个叙述完整的算法转化为程序代码,不是什么难事.然而,如何将算法独立与其所处理的数据结构之外,不受数据结构的羁绊呢?换个说法,如何将我们所写的程序算法适用于任何(或者大部分)未知的数据结构(比如ar ...
- 使用interface与类型诊断机制判断一个类型是否实现了某个方法
Golang中的interface通常用来定义接口,在接口里提供一些方法,其他类型可以实现(implement)这些方法,通过将接口指针指向不同的类型实例实现多态(polymorphism),这是in ...
- 使用XWAF框架(1)——Web项目的代码分层
建议在Eclipse环境下使用XWAF框架来开发用户的Web项目,并遵循以下步骤和约定. 1.获取XWAF框架压缩包文件 程序员点击下列地址免费下载XWAF框架的压缩包文件:XWAF框架压缩文件 2. ...
- MySQL----MySQL数据库入门----第五章 多表操作
5.1 外键 比如说有两个数据表,分别是学生信息表student和年级表grade.在student表中有存储学生年级的字段gid(外键),在grade表也有存储学生年级的字段id(主键),stude ...
- centos7 远程连接mongodb时,27017端口连接不上的解决办法
一.问题描述:centos 7 上安装mongogdb,然后通过另外一台电脑用pymongo连接mongodb时,报错:连接拒绝 解决过程: 1.修改mongo.conf文件 命令:sudo vi ...