WebMagic简介和使用
概览
WebMagic是一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。
WebMagic项目代码分为核心和扩展两部分。
- 核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。这部分提供非常简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫。
- 扩展部分(webmagic-extension)提供一些便捷的功能,例如注解模式编写爬虫等。同时内置了一些常用的组件,便于爬虫开发。
总体架构
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。
WebMagic总体架构图如下:

WebMagic的四个组件
- Downloader:Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
- PageProcessor:PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。在这四个组件中,
PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。 - Scheduler:Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
- Pipeline:Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
用于数据流转的对象
- Request:
Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。 - Page:
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。 - ResultItems:
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
实例
Maven坐标
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
爬取安居客房价信息实例
需求是获取所有小区的房价,先看一下页面截图:
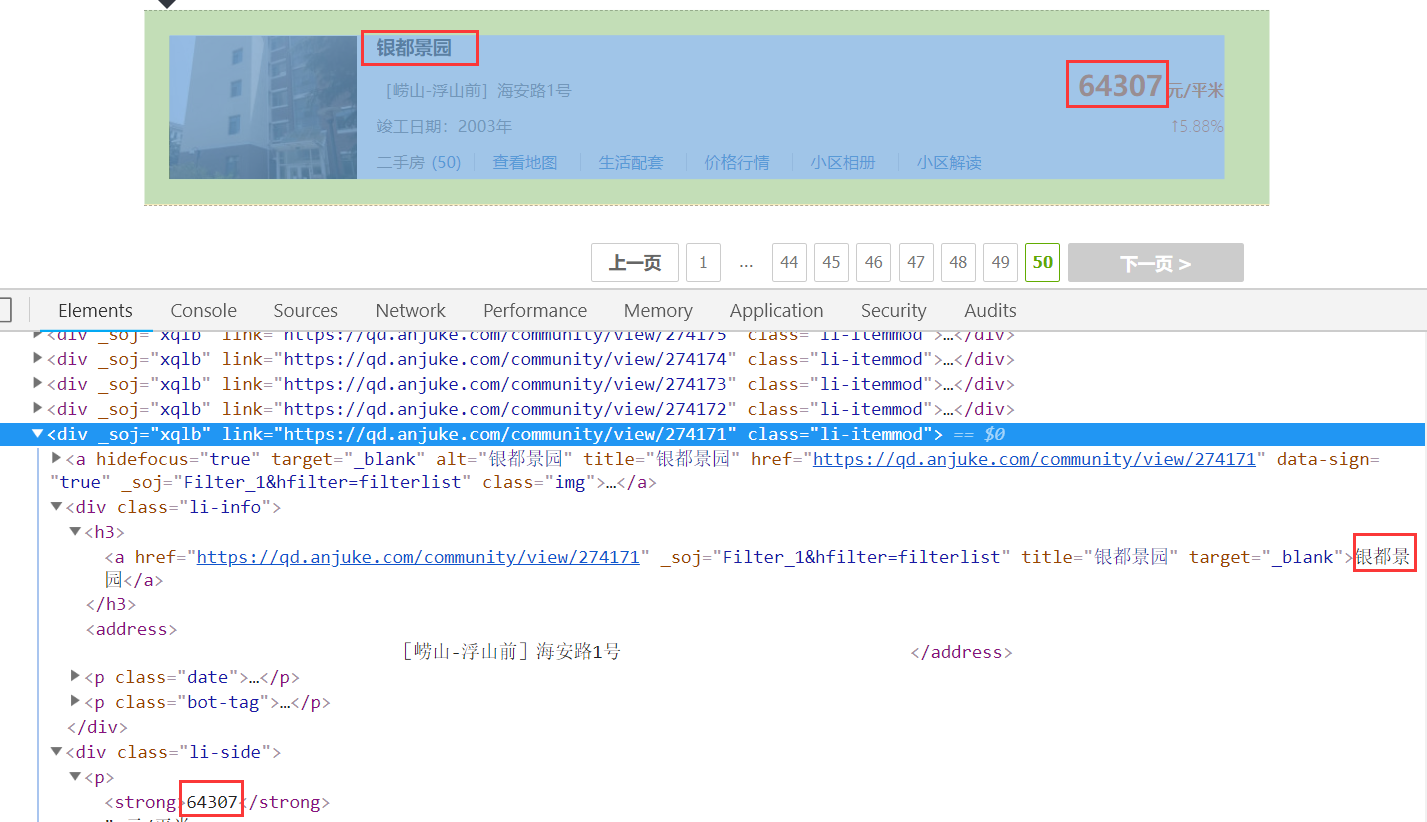
代码:
public class AnjukeProcessor implements PageProcessor {
//抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static int count = 0;
private static List<String> urlList = new ArrayList<>();
@Override
public void process(Page page) {
//从页面发现后续的url地址来抓取
page.addTargetRequests(
page.getHtml().xpath("//div[@class='page-content']/div[@class='multi-page']/a/@href").all());
//判断链接是否符合"https://qd.anjuke.com/community/p任意个数字"格式
if (page.getUrl().regex("https://qd.anjuke.com/community/p[0-9]+").match()) {
//定义如何抽取页面信息,并保存下来
List<Selectable> selectableList = page.getHtml().xpath("//div[@class='list-content']/div[@class='li-itemmod']").nodes();
List<HousePrice> list = new ArrayList<>();
for(Selectable selectable : selectableList){
String name = selectable.xpath("//div[@class='li-info']/h3/a/text()").toString();
String price = selectable.xpath("//div[@class='li-side']/p[1]/strong/text()").toString();
HousePrice housePrice = new HousePrice();
housePrice.setName(name.trim());
housePrice.setPriceStr(price.trim());
list.add(housePrice);
}
page.putField("housePriceList",list);
urlList.add(page.getUrl().toString());
count++;
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new AnjukeProcessor())
.addUrl("https://qd.anjuke.com/community/") //从https://qd.anjuke.com/community/开始爬取
.addPipeline(new HousePricePipeline()) //使用自定义的Pipeline
.thread(5)
.run();
System.out.println("----------抓取了"+count+"条记录");
}
}
public class HousePricePipeline implements Pipeline {
@Override
public void process(ResultItems resultItems, Task task) {
System.out.println("----------get page: " + resultItems.getRequest().getUrl());
List<HousePrice> list = resultItems.get("housePriceList");
System.out.println("----------list size:" + list.size());
}
}
注意事项
在0.7.3版本中,爬取只支持TLS1.2的https站点的时候会报错:
javax.net.ssl.SSLException: Received fatal alert: protocol_version
解决办法:https://github.com/code4craft/webmagic/issues/701
相关文档
WebMagic简介和使用的更多相关文章
- java 之webmagic 网络爬虫
webmagic简介: WebMagic是一个简单灵活的Java爬虫框架.你可以快速开发出一个高效.易维护的爬虫. http://webmagic.io/ 准备工作: Maven依赖(我这里用的Mav ...
- webmagic源码浅析
webmagic简介 webmagic可以说是中国传播度最广的Java爬虫框架,https://github.com/code4craft/webmagic,阅读相关源码,获益良多.阅读作者博客[代码 ...
- 爬虫框架--webmagic
官方有详细的使用文档:http://webmagic.io/docs/zh/ 简介:这只是个java爬虫框架,具体使用需要个人去定制,没有图片验证,不能获取js渲染的网页,但简单易用,可以通过xpat ...
- 基于webmagic的爬虫小应用--爬取知乎用户信息
听到“爬虫”,是不是第一时间想到Python/php ? 多少想玩爬虫的Java学习者就因为语言不通而止步.Java是真的不能做爬虫吗? 当然不是. 只不过python的3行代码能解决的问题,而Jav ...
- Java爬虫框架WebMagic——入门(爬取列表类网站文章)
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 简单搭建webMagic爬虫步骤
1.简介 WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个高效.易维护的爬虫. 官网:http://webmagic.io/ 中文官网:http://web ...
- Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 学校实训作业:Java爬虫(WebMagic框架)的简单操作
项目名称:java爬虫 项目技术选型:Java.Maven.Mysql.WebMagic.Jsp.Servlet 项目实施方式:以认知java爬虫框架WebMagic开发为主,用所学java知识完成指 ...
- ASP.NET Core 1.1 简介
ASP.NET Core 1.1 于2016年11月16日发布.这个版本包括许多伟大的新功能以及许多错误修复和一般的增强.这个版本包含了多个新的中间件组件.针对Windows的WebListener服 ...
随机推荐
- JavaScript正则表达式1
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要.正则表达式就是用于描述这些规则的工具.换句话说,正则表达式就是记录文本规则的代码. 正则表达式可以: •数据有效性验证.可以 ...
- Android中使用UncaughtExceptionHandler来处理未捕获的异常
原文在sparkyuan.me上.转载注明出处:http://sparkyuan.github.io/2016/03/28/使用UncaughtExceptionHandler来处理未捕获的异常/ 全 ...
- day21<IO流+&FIle递归>
IO流(字符流FileReader) IO流(字符流FileWriter) IO流(字符流的拷贝) IO流(什么情况下使用字符流) IO流(字符流是否可以拷贝非纯文本的文件) IO流(自定义字符数组的 ...
- swift - UIAlertController 的用法
ios 8 以后苹果官方建议使用UIAlertController这个类,所以专门去网上找资料,了解了下用法, 1.创建一个alertController let alertController = ...
- 【渗透测试学习平台】 web for pentester -6.命令执行
命令执行漏洞 windows支持: | ping 127.0.0.1|whoami || ping 2 || whoami (哪条名 ...
- Linux wc 命令
wc命令可以用来统计文件的行数 .单词数 .字符数,用法如下: [root@localhost ~]$ wc 1.txt # 统计文件的行数.单词数.字符数 2 4 24 1.txt [root@lo ...
- Qt监控后台服务运行状态
mainwindow.h #ifndef MAINWINDOW_H #define MAINWINDOW_H #include <QMainWindow> #include <QMa ...
- SQL 根据日期精确计算年龄
SQL 根据日期精确计算年龄 第一种: 一张人员信息表里有一人生日(Birthday)列,跟据这个列,算出该人员的年龄 datediff(year,birthday,getdate()) 例:birt ...
- Shell 将两个文件按列合并
file1. 1 2 2 3 3 4 4 5 5 6 file2. a b b c c d d e e f 需要把file2的第二列合并到file1,使File1并成三列. 第一种方法:paste p ...
- 布局的诡异bug合集+解决方法(更新中)
1.元素内部子元素的margin的边界线基准点的问题 论如何生硬起名字!!我反正已经被自己总结的题目绕晕了... “演员”介绍: 外层父元素:蓝色边框: 内部子元素:绿色区域: 粉红色区域是元素内部绿 ...