Python学习---深入编码学习1225
1.1. Python2
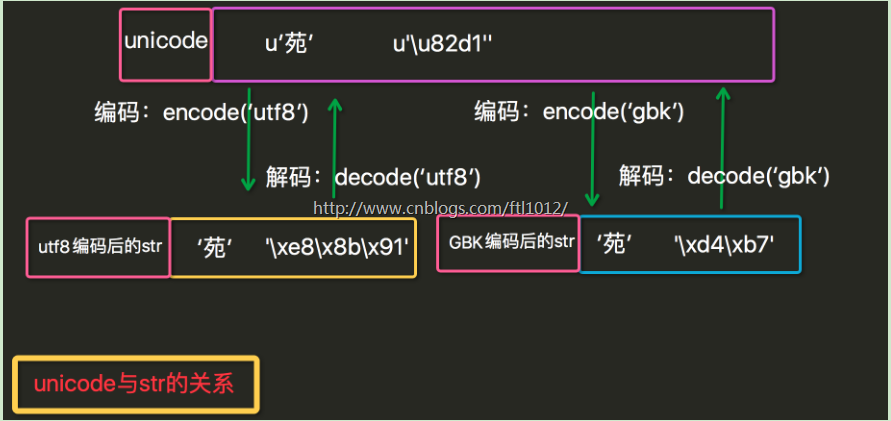
Py2中只有2中数据类型,Str和Unicode,而且str中保存的是bytes,Unicode中保存的是unicode
一切我们能看到的明文都是unicode数据类型, bytes是计算机识别 的内容
Py2特点:
Py2是ASCII编码,只能将ASCII里面的字符做转换,其他的会报错
严格意义上说,str其实是字节串, unicode是一个字符串,str是unicode这个字符串经过编码(utf8,gbk等)后的字节组成的序列。
unicode才是真正意义上的字符串
py2编码的最大特点是Python 2 将会自动的将bytes数据解码成 unicode 字符串,不区分str和unicode
所以在2里我们可以将字节与字符串拼接, 对字节串str使用正确的字符编码进行解码后获得,并且len(u'苑') == 1
# coding:utf-8 # Py2不添加直接报错
print '我是谁' # 一切我们能看到的明文都是unicode数据类型[utf-8 ->Unicode -> Unicode]
# bytes = str
print '我是Jackie' # str 类型内存中是bytes
print repr('我是Jackie') #'\xe6\x88\x91\xe6\x98\xafJackie' 一个汉字等于3个字节
print type('我是Jackie') # <type 'str'> print u'我是Jackie' # 我是Jackie
print type(u'我是Jackie') # <type 'unicode'> print 'hello' + u'world' # world是Unicode编码,但打印成功,因为print里面做了处理,将‘hello'的byte类型转换为了unicode
# print (u'我是'+'谁') # 因为中文的unicode无法做ASCII转换,所以报错,需要手动解码 # UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6
# in position 0: ordinal not in range(128)
1.2. Python3
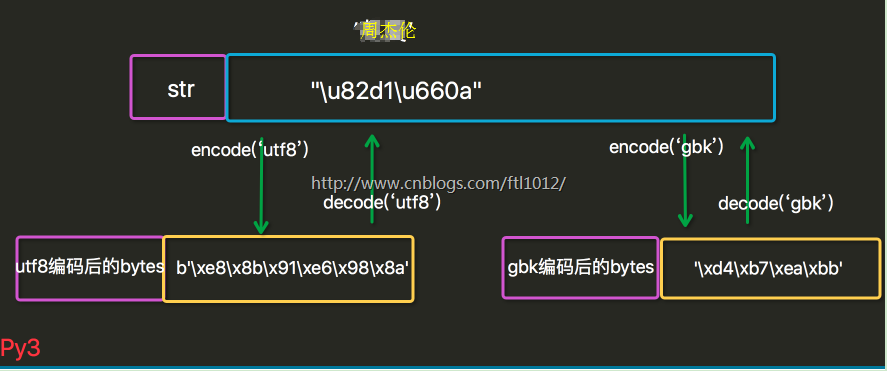
Py3中只有2中数据类型,Bytes和Unicode, 而且str中保存的是unicode,Bytes中保存的是bytes
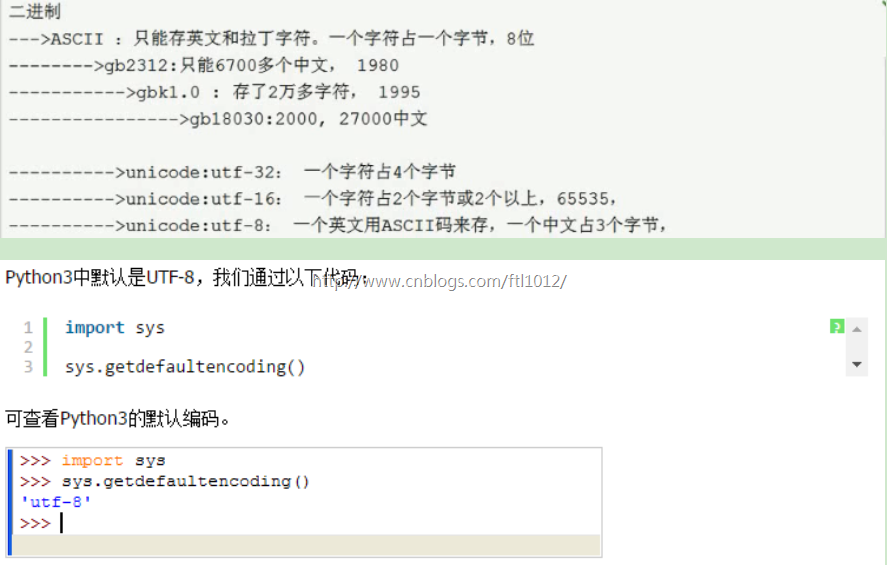
Python3中默认是utf-8,中文占用3个字节 【GBK中文占用2个字节】
Python 3最重要的新特性大概要算是对文本[unicode]和二进制数据[bytes]作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。
Python 3 中对 Unicode 支持的最大变化就是将会没有对 byte 字节串的自动解码。如果你想要用一个 byte 字节串和一个 unicode 相链接的话,你将会得到一个错误,不管你包含的内容是什么。
所有这些在 Python 2 中都将会有隐式的处理,而在 Python 3 中你将会得到一个错误。
Python3中大量的使用了迭代器,避免了数据一次性全部加载到内存中。
s = '中国' # s里面存的Unicode
b1 = s.encode('utf-8')
print(b1, type(b1)) # b'\xe4\xb8\xad\xe5\x9b\xbd' <class 'bytes'>
print(b1.decode('utf-8')) # 中国 decode的是Unicode,但是print显示的是明文,中间系统转换了结果
# print(b1.decode('gbk')) # UnicodeDecodeError: 'gbk' codec can't decode byte 0xad
# 打印的时候因为个数对应不上,所以报错了
查看中文字符的Unicode编码:
import json
s = '中国'
print(repr(s)) # Py2: repr可以直接查看
print(json.dumps(s)) # Py3: \u4e2d\u56fd
1.3. 其他
问:Py2中为什么要添加conding:utf-8才可以打印汉字?utf-8是谁看呢?
答:给Python2的解释器看,因为Py2的默认编码是ASCII,不能识别中文,所以需要声明编码方式
问:Py2中文件在磁盘中的编码是什么?
IDEA有自己的保存格式,所以根IDEA有关,解释器解释的时候是根据我们保存的文件格式去解释的,保存的和解释的要一致了才能执行解释。
问:Py2在执行的时候的内容跟磁盘的内容是否一样呢?
答: 转换编码后是一致的,磁盘保存的为计算机识别的二进制文件
问:Python文件编码的时候是utf-8为什么刚才我们又说字符串在内存中是Unicode编码呢?
答:Unicode是万国码,不同的系统编码不同,所以Python解释器帮我们解释为Unicode后加入内存,这个时候就不用担心系统解释器解释不了【Py2和Py3一样】
问:Py2和Py3中print的区别?
答:在Python 2中,print是一个语句(statement);而在Python 3中变成了函数(function)。
问:大概的流程是什么?
答:操作系统基于UTF_8保存的文本 --> 读取进入内存中[UTF-8] --> 解释器转换我们保存的数据为Unicode编码[我们保存的数据到此都是Unicode] --> 交给CPU去执行[此时CPU将我们要打印的内容进行了转换
ASCII: 将二进制翻译成我们能看懂的字符,共计255个符号,所有字符占用8个比特1个字节
支持中文的第一张表就叫 GB2312
unicode 万国码 支持所有国家和地区的编码且向下兼容gb2312 , gbk
2**16 = 65535 = 存一个字符 统一占用2个字节
UTF-8 = unicode 的扩展集,可变长的字符编码集
Assic -->Gb2312 ->gbk1.0-->gb18030
Assic -->unicode -->utf-8(支持所有国家语言,支持中文) /utf-16

Py3中只有2种数据类型:str[unicode编码] bytes[十六进制编码], 2者可以相互转换,其他的转换需要中间转
|
1
|
bytes-->int: int(str(bytes('123', 'utf-8'),'utf-8')) # 编码 |
Py3中合并Py2中的int和long int类型为int类型
Python学习---深入编码学习1225的更多相关文章
- python之03编码学习
编码介绍 ASCII :只能存英文和拉丁字符,一个字符占一个字节,8位 在中国的发展: gb2312:存6700多个中文 1980年 gbk1.0 :存2万多字符 1 ...
- python --- 字符编码学习小结
上半年的KPI,是用python做一个测试桩系统,现在系统框架基本也差不多定下来了.里面有用到新学的工厂设计模式以及以及常用的大牛写框架的业务逻辑和python小技巧.发现之前自己写的代码还是面向过程 ...
- 学习笔记之Python最简编码规范
Python最简编码规范 - 机器学习算法与Python学习 https://mp.weixin.qq.com/s/i6MwvC4jYTE6D1KHFgBeoQ https://www.cnblogs ...
- python --- 字符编码学习小结(二)
距离上一篇的python --- 字符编码学习小结(一)已经过去2年了,2年的时间里,确实也遇到了各种各样的字符编码问题,也能解决,但是每次都是把所有的方法都试一遍,然后终于正常.这种方法显然是不科学 ...
- python全栈开发学习_内容目录及链接
python全栈开发学习_day1_计算机五大组成部分及操作系统 python全栈开发学习_day2_语言种类及变量 python全栈开发_day3_数据类型,输入输出及运算符 python全栈开发_ ...
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
- 孤荷凌寒自学python第六十二天学习mongoDB的基本操作并进行简单封装1
孤荷凌寒自学python第六十二天学习mongoDB的基本操作并进行简单封装1 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第八天. 今天开始学习mongoDB的简单操作, ...
- 大牛整理最全Python零基础入门学习资料
大牛整理最全Python零基础入门学习资料 发布时间:『 2017-11-12 11:56 』 帖子类别:『人工智能』 阅读次数:3504 (本文『大牛整理最全Python零基础入门学习资料 ...
- Python框架之Django学习
当前标签: Django Python框架之Django学习笔记(十四) 尛鱼 2014-10-12 13:55 阅读:173 评论:0 Python框架之Django学习笔记(十三) 尛 ...
随机推荐
- TortoiseGit学习系列之Windows上本地代码如何通过TortoiserGit提交到GitHub详解(图文)
不多说,直接上干货! 前面博客 TortoiseGit学习系列之Windows上TortoiseGit的安装详解(图文) 上面博文给大家讲解了一下如何本地安装TortoiseGit. 这篇为大家讲一下 ...
- python-五个面试题
问题一:以下的代码的输出将是什么? 说出你的答案并解释. class Parent(object): x = 1 class Child1(Parent): pass class Child2(Par ...
- ZOJ 2971 Give Me the Number
Give Me the Number Numbers in English are written down in the following way (only numbers less than ...
- 如何去组织你的CSS代码
1.Object Oriented CSS (OOCSS) 面向对象的 CSS.OOCSS 的想法首先要明白 CSS 的 “Object” 是个毛线玩意. CSS的样式是需要应用到页面的结构上的.通俗 ...
- Vue组件库
滴滴cube-ui https://didi.github.io/cube-ui/#/zh-CN/docs/quick-start 有赞开源Vant(适合做商城) https://tech.youza ...
- Mac上微信小程序官方开发工具卡死的问题
Mac上微信小程序官方开发工具打开后卡死,无法操作,也关不掉,解决方案: 三步: 1.在应用中删除“微信web开发者工具” 2.删除一下几个配置和缓存文件: 1.-/Library/Applicati ...
- Linux 服务器 MySql的安装和网站的发布
Linux安装MySql,并配置能通过自己的电脑连接服务器的数据库 昨天安装的MySql,今天上午配置MySql能使用本机连接服务器数据库,服务器时DigitalOcean的,提供了很全面很专业的文档 ...
- jQuery基础---动画效果
内容摘要: 1.显示.隐藏 2.滑动.卷动 3.淡入.淡出 4.自定义动画 5.列队动画方法 6.动画相关方法 7.动画全局属性 发文不易,转载请注明出处~ 一.显示.隐藏 jQuery 中显示方法 ...
- 基于标注的AOP面向切面编程
1.什么是AOP Aspect Orientied Programming的简称,即 面向(方面)切面编程 ,不改变一个组件源代码的情况下 可以对组件功能进行增强. 例如:servlet中的过滤 ...
- Eclipse 反编译之 JadClipse
一:下载对应的 net.sf.jadclipse_x.x.x.jar ,把该jar包放入到Eclipse中的 plugins 目录下,下载地址:https://sourceforge.net/proj ...