Python学习---深入编码学习1225
1.1. Python2
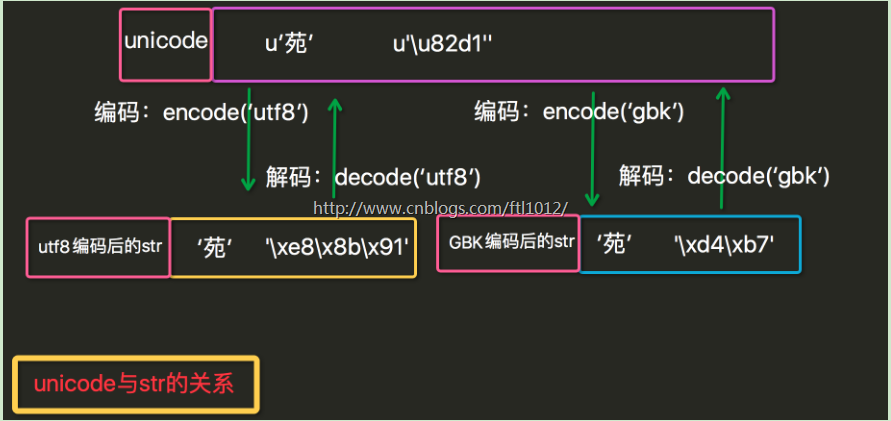
Py2中只有2中数据类型,Str和Unicode,而且str中保存的是bytes,Unicode中保存的是unicode
一切我们能看到的明文都是unicode数据类型, bytes是计算机识别 的内容
Py2特点:
Py2是ASCII编码,只能将ASCII里面的字符做转换,其他的会报错
严格意义上说,str其实是字节串, unicode是一个字符串,str是unicode这个字符串经过编码(utf8,gbk等)后的字节组成的序列。
unicode才是真正意义上的字符串
py2编码的最大特点是Python 2 将会自动的将bytes数据解码成 unicode 字符串,不区分str和unicode
所以在2里我们可以将字节与字符串拼接, 对字节串str使用正确的字符编码进行解码后获得,并且len(u'苑') == 1
# coding:utf-8 # Py2不添加直接报错
print '我是谁' # 一切我们能看到的明文都是unicode数据类型[utf-8 ->Unicode -> Unicode]
# bytes = str
print '我是Jackie' # str 类型内存中是bytes
print repr('我是Jackie') #'\xe6\x88\x91\xe6\x98\xafJackie' 一个汉字等于3个字节
print type('我是Jackie') # <type 'str'> print u'我是Jackie' # 我是Jackie
print type(u'我是Jackie') # <type 'unicode'> print 'hello' + u'world' # world是Unicode编码,但打印成功,因为print里面做了处理,将‘hello'的byte类型转换为了unicode
# print (u'我是'+'谁') # 因为中文的unicode无法做ASCII转换,所以报错,需要手动解码 # UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6
# in position 0: ordinal not in range(128)
1.2. Python3
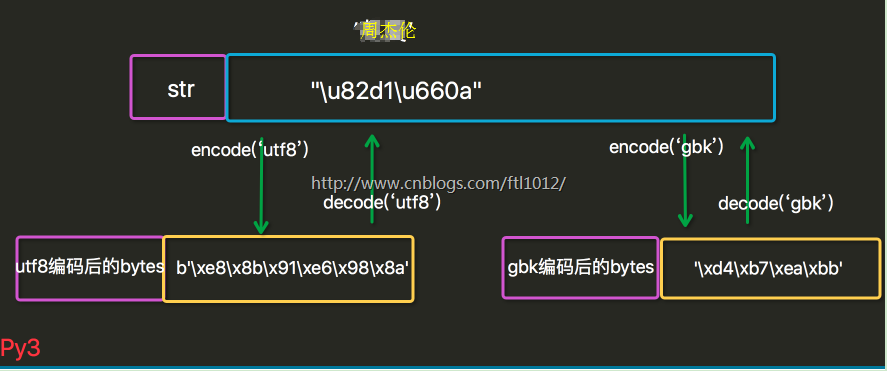
Py3中只有2中数据类型,Bytes和Unicode, 而且str中保存的是unicode,Bytes中保存的是bytes
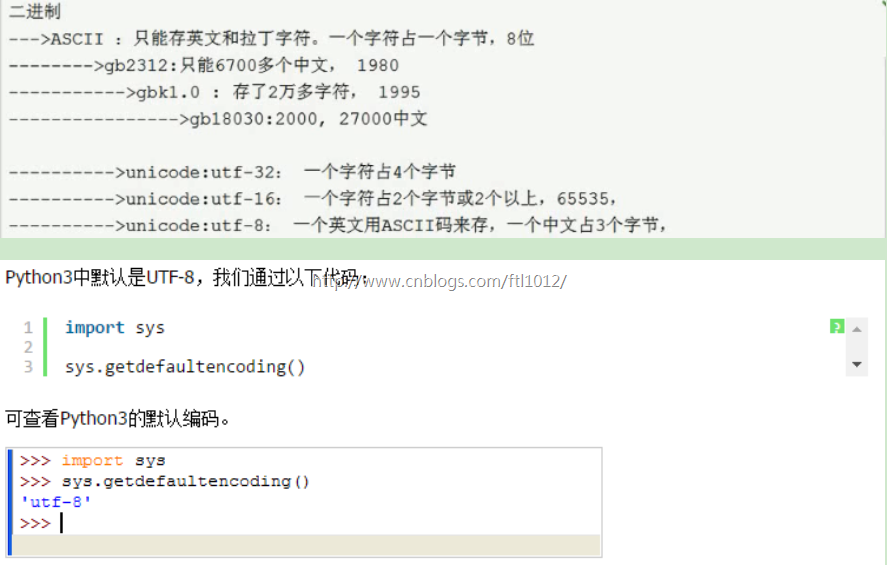
Python3中默认是utf-8,中文占用3个字节 【GBK中文占用2个字节】
Python 3最重要的新特性大概要算是对文本[unicode]和二进制数据[bytes]作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。
Python 3 中对 Unicode 支持的最大变化就是将会没有对 byte 字节串的自动解码。如果你想要用一个 byte 字节串和一个 unicode 相链接的话,你将会得到一个错误,不管你包含的内容是什么。
所有这些在 Python 2 中都将会有隐式的处理,而在 Python 3 中你将会得到一个错误。
Python3中大量的使用了迭代器,避免了数据一次性全部加载到内存中。
s = '中国' # s里面存的Unicode
b1 = s.encode('utf-8')
print(b1, type(b1)) # b'\xe4\xb8\xad\xe5\x9b\xbd' <class 'bytes'>
print(b1.decode('utf-8')) # 中国 decode的是Unicode,但是print显示的是明文,中间系统转换了结果
# print(b1.decode('gbk')) # UnicodeDecodeError: 'gbk' codec can't decode byte 0xad
# 打印的时候因为个数对应不上,所以报错了
查看中文字符的Unicode编码:
import json
s = '中国'
print(repr(s)) # Py2: repr可以直接查看
print(json.dumps(s)) # Py3: \u4e2d\u56fd
1.3. 其他
问:Py2中为什么要添加conding:utf-8才可以打印汉字?utf-8是谁看呢?
答:给Python2的解释器看,因为Py2的默认编码是ASCII,不能识别中文,所以需要声明编码方式
问:Py2中文件在磁盘中的编码是什么?
IDEA有自己的保存格式,所以根IDEA有关,解释器解释的时候是根据我们保存的文件格式去解释的,保存的和解释的要一致了才能执行解释。
问:Py2在执行的时候的内容跟磁盘的内容是否一样呢?
答: 转换编码后是一致的,磁盘保存的为计算机识别的二进制文件
问:Python文件编码的时候是utf-8为什么刚才我们又说字符串在内存中是Unicode编码呢?
答:Unicode是万国码,不同的系统编码不同,所以Python解释器帮我们解释为Unicode后加入内存,这个时候就不用担心系统解释器解释不了【Py2和Py3一样】
问:Py2和Py3中print的区别?
答:在Python 2中,print是一个语句(statement);而在Python 3中变成了函数(function)。
问:大概的流程是什么?
答:操作系统基于UTF_8保存的文本 --> 读取进入内存中[UTF-8] --> 解释器转换我们保存的数据为Unicode编码[我们保存的数据到此都是Unicode] --> 交给CPU去执行[此时CPU将我们要打印的内容进行了转换
ASCII: 将二进制翻译成我们能看懂的字符,共计255个符号,所有字符占用8个比特1个字节
支持中文的第一张表就叫 GB2312
unicode 万国码 支持所有国家和地区的编码且向下兼容gb2312 , gbk
2**16 = 65535 = 存一个字符 统一占用2个字节
UTF-8 = unicode 的扩展集,可变长的字符编码集
Assic -->Gb2312 ->gbk1.0-->gb18030
Assic -->unicode -->utf-8(支持所有国家语言,支持中文) /utf-16

Py3中只有2种数据类型:str[unicode编码] bytes[十六进制编码], 2者可以相互转换,其他的转换需要中间转
|
1
|
bytes-->int: int(str(bytes('123', 'utf-8'),'utf-8')) # 编码 |
Py3中合并Py2中的int和long int类型为int类型
Python学习---深入编码学习1225的更多相关文章
- python之03编码学习
编码介绍 ASCII :只能存英文和拉丁字符,一个字符占一个字节,8位 在中国的发展: gb2312:存6700多个中文 1980年 gbk1.0 :存2万多字符 1 ...
- python --- 字符编码学习小结
上半年的KPI,是用python做一个测试桩系统,现在系统框架基本也差不多定下来了.里面有用到新学的工厂设计模式以及以及常用的大牛写框架的业务逻辑和python小技巧.发现之前自己写的代码还是面向过程 ...
- 学习笔记之Python最简编码规范
Python最简编码规范 - 机器学习算法与Python学习 https://mp.weixin.qq.com/s/i6MwvC4jYTE6D1KHFgBeoQ https://www.cnblogs ...
- python --- 字符编码学习小结(二)
距离上一篇的python --- 字符编码学习小结(一)已经过去2年了,2年的时间里,确实也遇到了各种各样的字符编码问题,也能解决,但是每次都是把所有的方法都试一遍,然后终于正常.这种方法显然是不科学 ...
- python全栈开发学习_内容目录及链接
python全栈开发学习_day1_计算机五大组成部分及操作系统 python全栈开发学习_day2_语言种类及变量 python全栈开发_day3_数据类型,输入输出及运算符 python全栈开发_ ...
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
- 孤荷凌寒自学python第六十二天学习mongoDB的基本操作并进行简单封装1
孤荷凌寒自学python第六十二天学习mongoDB的基本操作并进行简单封装1 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第八天. 今天开始学习mongoDB的简单操作, ...
- 大牛整理最全Python零基础入门学习资料
大牛整理最全Python零基础入门学习资料 发布时间:『 2017-11-12 11:56 』 帖子类别:『人工智能』 阅读次数:3504 (本文『大牛整理最全Python零基础入门学习资料 ...
- Python框架之Django学习
当前标签: Django Python框架之Django学习笔记(十四) 尛鱼 2014-10-12 13:55 阅读:173 评论:0 Python框架之Django学习笔记(十三) 尛 ...
随机推荐
- ECharts概念学习系列之ECharts的下载和安装(图文详解)
不多说,直接上干货! http://echarts.baidu.com/download.html 前言 如果你想要用较少的代码实现比较酷炫的数据统计表,echarts是值得你考虑的一种实现方式.官网 ...
- WPF 自定义NotifyPropertyChanged
该工具类实现INotifyPropertyChanged接口 /// <summary> /// 实现了属性更改通知的基类 /// </summary> public clas ...
- Ubuntu系统Apache Maven安装
操作系统:Linux x64 / Ubuntu 14.04 Apache Maven版本:3.3.9 建议预先搭建Java开发环境:详见上一篇<Linux Ubuntu系统下Java开发环境搭建 ...
- digestmd5.c:4037:15: error: #elif with no expression
执行如下:sed -i.bak 's/#elif WITH_DES/#elif defined(WITH_DES)/' \ plugins/digestmd5.c
- Lucio: We avoided Mourinho after every loss
Former Inter defender Lucio has revealed how players had to avoid former Nerazzurri coach Mourinho e ...
- Bootboxjs快速制作Bootstrap的弹出框效果
Bootboxjs是一个简单的js库,简单快捷帮你制作一个Bootstrap的弹出框效果. 一.简介 bootbox.js是一个小的JavaScript库,它帮助您在使用bootstrap框架的时候快 ...
- 实现MySQL数据库的实时备份
实现MySQL数据库的实时备份 使用MySQL Replication 吴剑 2018-08-03 原创文章,转载必需注明出处:http://www.cnblogs.com/wu-jian 吴剑 ht ...
- Uboot流程分析
1. uboot的配置分析 1).配置入口分析 首先分析配置: 从make mx6dl_sabresd_android_config可知配置项,搜索Makefile: mx6solo_sabresd_ ...
- i.mx6 Android5.1.1 Zygote
0. 总结: 0.1 相关源码目录: framework/base/cmds/app_process/app_main.cppframeworks/base/core/jni/AndroidRunti ...
- 控件--spinner(列表选项框)
1. 关键点 1). Spinner的菜单显示方式 它有两种显示形式,一种是下拉菜单,一种是弹出框,菜单显示形式是spinnerMode属性决定的: android:spinnerMode=" ...