Oozie_03运行官方案例【20161116】
3.1官方的案例
(1)Oozie根目录下找到 oozie-examples.tar.gz
(2)解压tar -zxvf oozie-examples.tar.gz 生成example文件夹
[hadoop@hadoop01 oozie-4.0.0-cdh5.3.6]$ tar -zxvf oozie-examples.tar.gz
(3)拷贝(2)新生成的examples到HDFS的用户家目录下
[hadoop@hadoop01 hadoop-2.5.0-cdh5.3.6]$
bin/hdfs dfs -put /opt/cdh-5.3.6/oozie-4.0.0-cdh5.3.6/examples examples

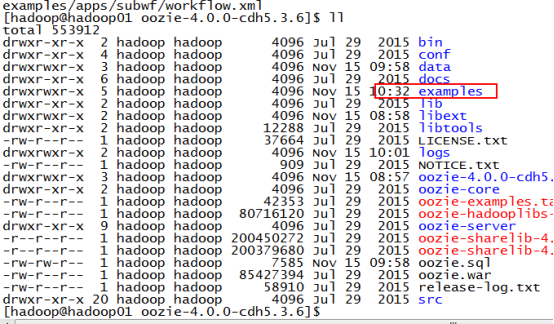
(4)查看examples里面内容
三个目录apps input-data src,三个目录主要功能及截图如下

apps:官方自带的workflow的案例,有hive mapreduce.....

input-data:输入的数据
src:源码包

(5)配置案例自带的mapreduce程序
查看其中一个mao-reduce案例,里面有五个文件:
job.properties:两个作用:指定workflow的地址 声明相关变量
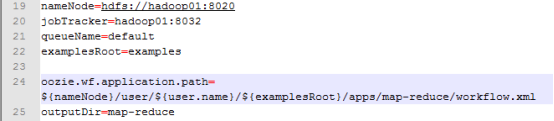
nameNode=主机名
jobTracker 端口为8032(就是resourcemanger地址)
queueName队列名称不改
examplesRoot
ooize.wf.application.path=主机名/用户名/.. 指定了workflow的地址
原有内容

修改下面内容 修改了nameNode和jobTracker两处
lib 存放jar包 【不用修改】
workflow.xml :实际运行的workflow【运行该案例这个配置不用修改】
prepare标志作用对提前删除输出目录
.输出目录同输入目录同建立在/user/hadoop/examples下面(如下图)
configuration标志对

job-with-config-class.properties 【不修改】
workflow-with-config-class.xml 【不修改】
(6)修改oozie-site.xml
修改前内容
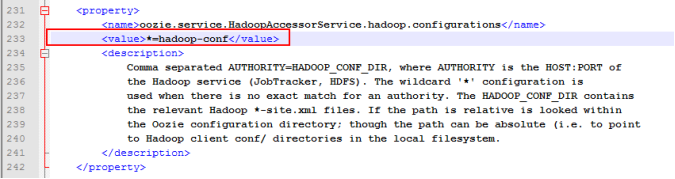
该属性修改为hadoop的配置文件
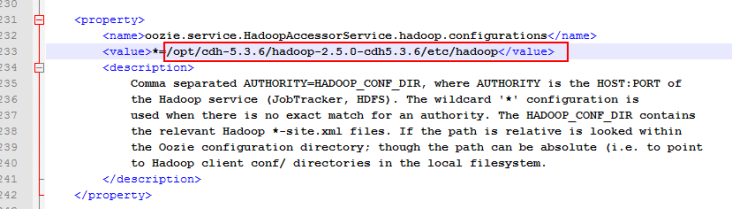
注意: *=不能删除
(7)重启oozie
[hadoop@hadoop01 oozie-4.0.0-cdh5.3.6]$ bin/oozied.sh stop
[hadoop@hadoop01 oozie-4.0.0-cdh5.3.6]$ bin/oozied.sh start
(8)再次提交
[hadoop@hadoop01 oozie-4.0.0-cdh5.3.6]$ bin/oozie job -oozie http://hadoop01:11000/oozie -config examples/apps/map-reduce/job.properties -run
命令行界面
Oozie图形界面
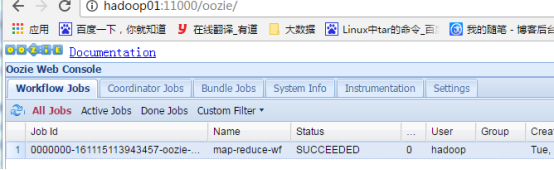
(9)总结
第一点:运行时指定的job.properties文件是本地的,不是hdfs上面的,不过建议修改完该properties文件最好重新上次,把整个包重新上传
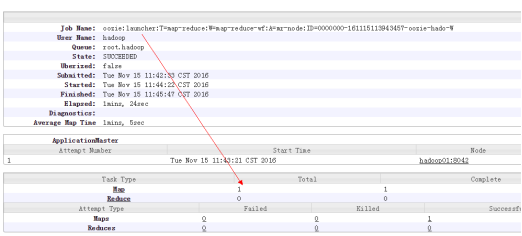
第二点:运行一个workflow 启动了两个mapreduce
一个是oozie:launcher 用于对workflow进行封装(封装程序只有map任务)
一个是oozie:action 执行的mapreduce
利用8088端口查看
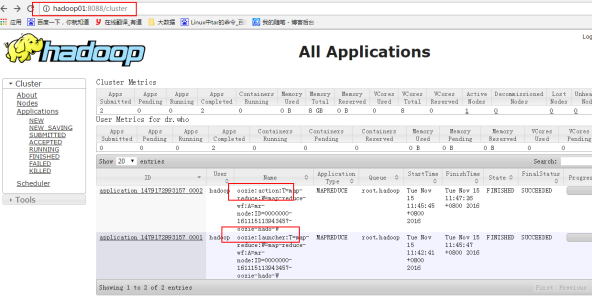
action:launcher只有map任务
Oozie_03运行官方案例【20161116】的更多相关文章
- caffe︱cifar-10数据集quick模型的官方案例
准备拿几个caffe官方案例用来练习,就看到了caffe中的官方案例有cifar-10数据集.于是练习了一下,在CPU情况下构建quick模型.主要参考博客:liumaolincycle的博客 配置: ...
- UE4的AI学习(2)——官方案例实例分析
官方给出的AI实例是实现一个跟随着玩家跑的AI,当玩家没有在AI视野里时,它会继续跑到最后看到玩家的地点,等待几秒后如果仍然看不到玩家,则跑回初始地点.官方的案例已经讲得比较详细,对于一些具体的函数调 ...
- Spring-boot官方案例分析之log4j
Spring-boot官方案例分析之log4j 运行单元测试分析: @RunWith(SpringJUnit4ClassRunner.class) @SpringApplicationConfigur ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- 通过angularJS官方案例快速入门
官方案例-angular-phonecat angularJS官方提供了一个官方案例给大家进行循序渐进的学习,但是如果之前没有接触过node.js以及git的同学这个案例拿着也无从下手-这里就介绍一下 ...
- 老李推荐:第5章1节《MonkeyRunner源码剖析》Monkey原理分析-启动运行: 官方简介
老李推荐:第5章1节<MonkeyRunner源码剖析>Monkey原理分析-启动运行: 官方简介 在MonkeyRunner的框架中,Monkey是作为一个服务来接受来自Monkey ...
- hadoop一代集群运行代码案例
hadoop一代集群运行代码案例 集群 一个 master,两个slave,IP分别是192.168.1.2.192.168.1.3.192.168.1.4 hadoop版 ...
- Spring-boot官方案例分析之data-jpa
Spring-boot官方案例分析之data-jpa package sample.data.jpa; import org.junit.Before; import org.junit.Test; ...
随机推荐
- Django 模型(数据库)
Django 模型(数据库) ) email = models.EmailField() memo = models.TextField() def __unico ...
- poj1177 Picture 矩形周长并
地址:http://poj.org/problem?id=1177 题目: Picture Time Limit: 2000MS Memory Limit: 10000K Total Submis ...
- SQL 根据条件取不同列中的值来排序
1 有时候排序比较复杂,比如:领导对工资在1000到2000元之间的员工更感兴趣,于是要求工资在这个范围内的员工排在前面,以便优先查看 对于这种要求我们可以在查询中新生成一列,用多列排序的方法处理代 ...
- 20145204 《Java程序设计》第7周学习总结
20145204 <Java程序设计>第7周学习总结 教材学习内容总结 时间 GMT.UT.TAI 格林威治标准时间(GMT)的正午是太阳抵达天空最高点之时,因为地球公转轨道为椭圆且速度不 ...
- 20145221 《Java程序设计》实验报告三:敏捷开发与XP实践
20145221 <Java程序设计>实验报告三:敏捷开发与XP实践 实验要求 以结对编程的方式编写一个软件,Blog中要给出结对同学的Blog网址 记录TDD和重构的过程,测试代码不要少 ...
- Xcode7.2与iOS9之坑 (持续更新)
GitHub地址 前几天升级OS X EI Capitan 10.11.1, 以及Xcode7.1,正好赶上公司新产品上线,要做iOS9的适配,遇到各种坑,各种查资料,随之记录总结一下遇到的坑. 先说 ...
- 彻底搞懂JavaScript中的继承
你应该知道,JavaScript是一门基于原型链的语言,而我们今天的主题 -- "继承"就和"原型链"这一概念息息相关.甚至可以说,所谓的"原型链&q ...
- windows下通过ping和tracert工具来测试网站访问速度
一.环境 OS: windows 二.步骤 2.1.ping mirrors.163.com Pinging mirrors.163.com [23.111.1.151] with 32 bytes ...
- Gym - 100283F Bakkar In The Army(二分)
https://vjudge.net/problem/Gym-100283F 题意: 1 1 2 1 1 2 3 2 1 1 2 3 4 3 2 1 .... 给出这样的序列,然后给出一个n,计算从1 ...
- BZOJ 2342: 【SHOI2011】 双倍回文
题目链接:双倍回文 回文自动机第二题.构出回文自动机,那么一个回文串是一个“双倍回文”,当且仅当代表这个串的节点\(u\)顺着\(fail\)指针往上跳,可以找到一个节点\(x\)满足\(2len_x ...