MapReduce详解和WordCount模拟
最早接触大数据,常萦绕耳边的一个词「MapReduce」。它到底是什么,能做什么,原理又是什么?且听下文讲解。
是什么
MapReduce 即是一个编程模型,又是一个计算框架,它充分采用了分治的思想,将数据处理过程拆分成两步:Map 和 Reduce。用户只需要编写 map() 和 reduce() 函数,就能使问题的计算实现分布式,并在Hadoop上执行。
数据处理
MapReduce 操作数据的最小单位是一个键值对。map 端的主要输入是一对<key,value>值,经过 map 计算后输出一对<key,value>,然后将相同的 key 合并,形成<key,value 集合>,再将这个<key,value 集合>输入 reduce ,经过计算输出零个或多个<key,value>对。
两个重要的进程
JobTracker
JobTracker 在集群中负责任务调度和集群资源监控这两个功能。TaskTracker 通过周期性的心跳向 JobTracker 汇报当前的健康状况和状态,心跳中包括自身计算资源的信息、被占用的计算资源的信息和正在运行中的任务的状态信息。JobTracker 会根据各个 TaskTracker 周期性发送过来的心跳信息综合考虑TaskTracker 的资源余量、作业优先级、作业提交时间等因素,为 TaskTracker 分配合适的任务。
JobTracker 提供了一个基于 web 的管理界面,可以通过 JobTracker:50030 端口访问。
TaskTracker
TaskTracker 主要负责汇报心跳和执行 JobTracker 命令这两个功能。命令主要包括5种:启动命令、提交命令、杀死任务、杀死作业和重新初始化。
几个概念
作业(Job) 和 任务(Task)
MapReduce 作业是用户提交的最小单位,任务是 MapReduce 计算的最小单位。 简单讲,用户提交的是一个MapReduce作业,一个 MapReduce 作业可以被拆分成两种——Map 任务和 Reduce 任务。
槽(slot)
槽是Hadoop计算资源的表示模型,Hadoop 将各个节点上的多维度资源(CPU、内存等)抽象成一维度的槽。一个TaskTracker 能够启动的任务数量是由 TaskTracker 配置的任务槽决定的。
MapReduce 过程
一个MapReduce作业通常经过 input、map、combine、reduce、output 五个阶段。combine 阶段不一定发生,map输出的中间结果分发到 reduce 的过程被称为 shuffle。shuffle 阶段还会发生 copy 和 sort。

两幅重要的流程图
- map任务流程图
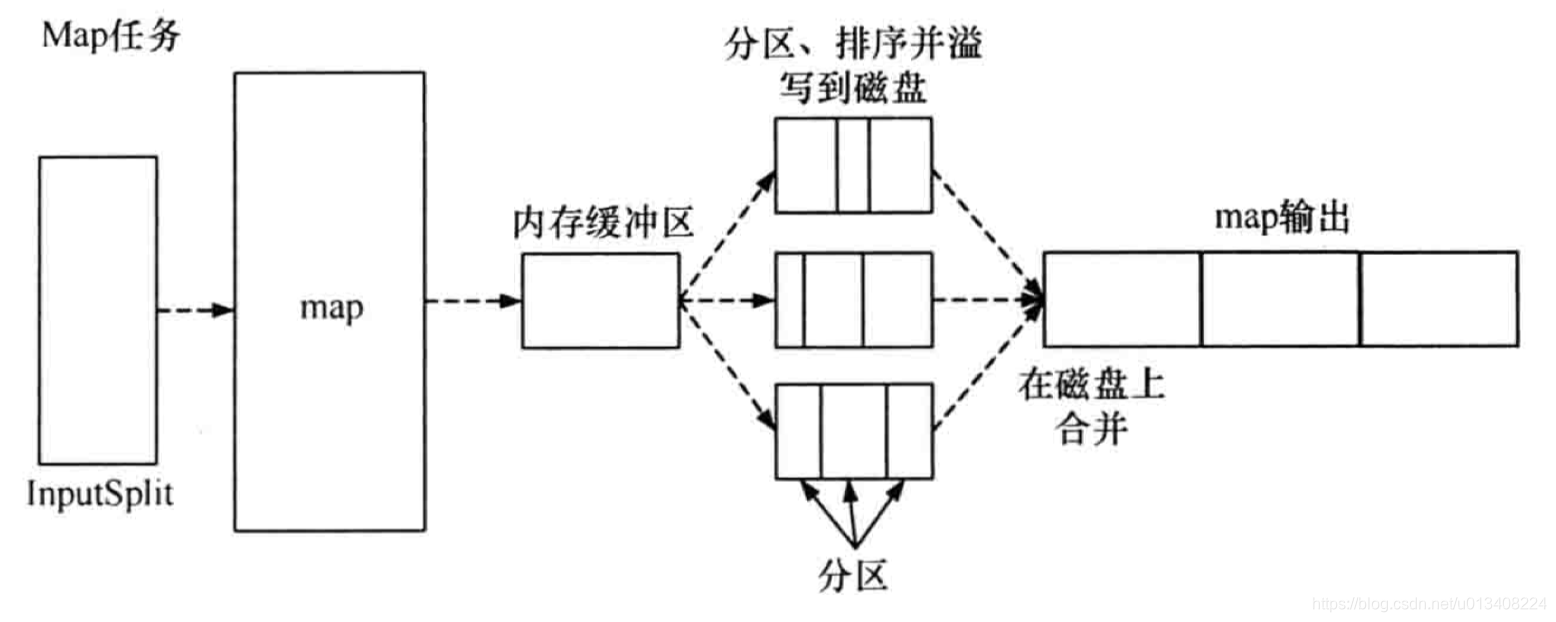
- reduce 任务流程图
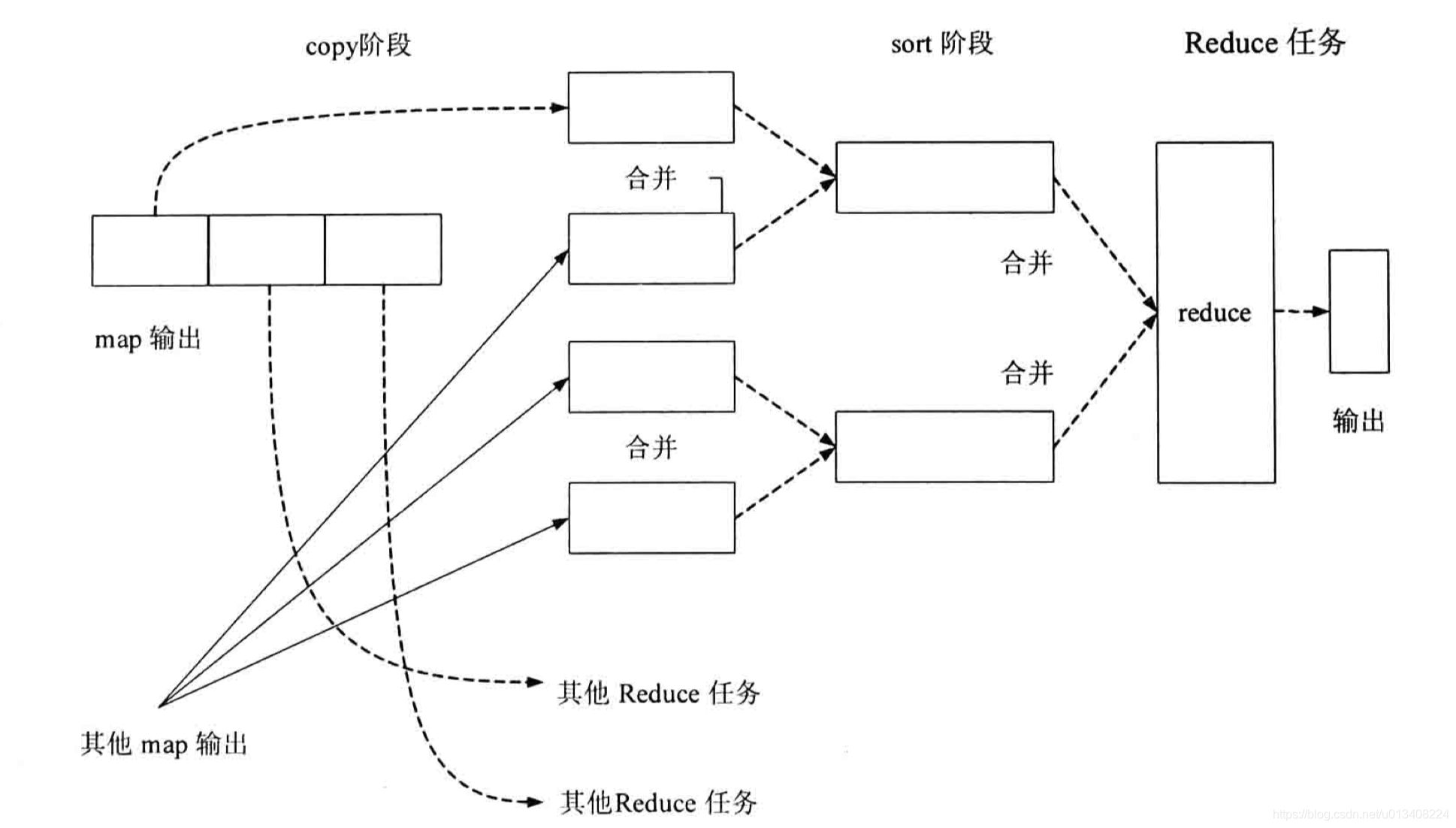
几个重要的阶段说明
map 函数处理后的中间结果会写到本地磁盘上,在刷写磁盘的过程中,还做了 partition 和 sort 操作。
map 函数输出时,并不是简单地刷写磁盘,为了保证 I/O 效率,采取了先写到内存的环形缓冲区,并做一次预排序。请结合map任务流程图理解。
partition
在分区阶段,通过对 key 取模,生成<partition,key,value>三元组,分区阶段进行了一次内排序。
MemoryBuffer
内存缓冲区,保存 map 的结果和 partition 处理后的结果,默认大小为100M,溢写阈值为80M。
spill(溢写)
内存缓冲区达到阈值时,溢写线程锁住这80M的缓冲区,开始将数据写到本地磁盘中,然后释放内存。
每次溢写都会生成一个数据文件,溢出的数据写到磁盘前会对数据进行 sort 以及合并(combine)。
combine
combine 对map 函数的输出结果进行早期聚合以减少传输的数据量,其作用其实和reduce 函数一样。combine 的过程发生在 spill(溢写) 阶段。
combine 能够提升程序性能,但并不是所有常见都适合使用 combine ,例如:求中值。
sort
MapReduce 计算框架主要用到了两种排序:快速排序和归并排序。在 Map 任务和 Reduce 任务的过程中,一共发生了三次排序操作:
- partition 过程中按照键值进行的内排序。
- map 任务完成之前,合并溢写文件产生输出文件时进行的一次 sort 操作。
- shuffle 过程的 sort 操作。
wordcount 实验模拟
map 端编程代码(map_a.py):
import sys
import re
p =re.compile(r'\w+')
for line in sys.stdin:
world_list =line.strip().split()
for word in world_list:
if len(word)<2:
continue
w_list =p.findall(word)
if len(w_list)>0:
w =w_list[0].lower()
print "%s\t%d"%(w,1)
reduce 端编程代码(red_b.py)
import sys
wt =0
cur_word =None
for line in sys.stdin:
word,cnt =line.strip().split('\t')
if cur_word ==None:
cur_word =word
if cur_word !=word:
print "%s\t%d"%(cur_word,wt)
wt =0
cur_word =word
wt =wt+int(cnt)
print "%s\t%d"%(cur_word,wt)
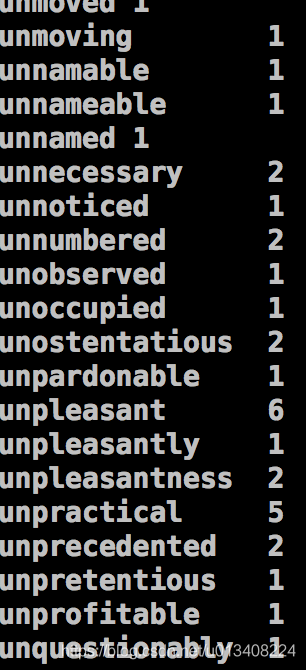
模拟命令
cat The_man_of_property.txt |python ./project/map_a.py | sort -k 1 |python ./project/red_b.py
输出显示
MapReduce详解和WordCount模拟的更多相关文章
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
- 【大数据】Linux下安装Hadoop(2.7.1)详解及WordCount运行
一.引言 在完成了Storm的环境配置之后,想着鼓捣一下Hadoop的安装,网上面的教程好多,但是没有一个特别切合的,所以在安装的过程中还是遇到了很多的麻烦,并且最后不断的查阅资料,终于解决了问题,感 ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- 大数据入门第七天——MapReduce详解(一)入门与简单示例
一.概述 1.map-reduce是什么 Hadoop MapReduce is a software framework for easily writing applications which ...
- hadoop之mapreduce详解(基础篇)
本篇文章主要从mapreduce运行作业的过程,shuffle,以及mapreduce作业失败的容错几个方面进行详解. 一.mapreduce作业运行过程 1.1.mapreduce介绍 MapRed ...
- MapReduce 过程详解 (用WordCount作为例子)
本文转自 http://www.cnblogs.com/npumenglei/ .... 先创建两个文本文件, 作为我们例子的输入: File 1 内容: My name is Tony My com ...
- 大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一.mapTask并行度的决定机制 1.概述 一个job的map阶段并行度由客户端在提交job时决定 而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小, ...
- MapReduce:详解Shuffle过程(转)
/** * author : 冶秀刚 * mail : dennyy99@gmail.com */ Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapRedu ...
- MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
随机推荐
- H-a
1.habit 习惯:毒瘾 in the habit of 有....习惯 派生:habitual a.通常的,习惯的:已养成习惯的: 2.hacker 黑客 3.hail n. 雹 vi.下雹 vt ...
- L03-Linux RHEL6.5系统中配置本地yum源
1.将iso镜像文件上传到linux系统.注意要将文件放在合适的目录下,因为后面机器重启时还要自动挂载,所以此次挂载成功之后该文件也不要删除. 2.将iso光盘挂载到/mnt/iso目录下. (1)先 ...
- 函数直接写在html页面的<script>里可以调用,但是单独放在js文件里不能调用
1.函数直接写在页面相当于是你本页调用,所以理所应当可以调用 2.js单独文件不能调用是因为你没有引用js文件,如果引用了的话,也是可以调用的. 引用方式,你可以直接拖拽(我一般都是拖拽,因为路径准确 ...
- NOIWC 2019 冬眠记【游记】
在我的blog查看:https://www.wjyyy.top/wc2019 Day -1 上火车了,but手机没电了. Day 0 中午1点左右到了广州东站.接站只有南站和机场有,于是坐了一个多小时 ...
- C#静态和实例
静态 实例 关键字static修饰类或方法 不能使用static修饰类或方法 修饰后类直接调用 需要先实例化对象,用对象调用 静态只会执行调用一次,并且在程序退出之前会一直保持状态,占领内存 实例化一 ...
- Flutter视图基础简介--Widget、Element、RenderObject
前言:Flutter官方文档里的一句话:you build your UI out of widgets(使用Flutter开发UI界面时,都是使用Widget),然而,Widget并不是我们真正看到 ...
- 关闭MAC特效
Launchpad首先打开"终端"(Finder->应用程序->实用工具->终端),并且输入以下命令:defaults write com.apple.dock ...
- 16个最佳响应式HTML5框架分享
HTML5框架可以快速构建响应式网站,它们帮助程序员减少编码工作,减少冗余的代码.如今有很多免费的HTML5框架可供使用,由于它们有着响应式设计.跨浏览器兼容.相对轻量级等特点,这些框架在开发中都十分 ...
- 【Maven学习】maven-assembly-plugin的使用
转自http://liugang594.iteye.com/blog/2093607 maven-assembly-plugin使用描述(拷自 maven-assembly-plugin 主页) Th ...
- java.util.Collections.synchronizedSet()方法的使用
下面的例子显示java.util.Collections.synchronizedSet()方法的使用 package com.; import java.util.*; public class C ...