Hadoop之MapReduce学习笔记(二)
主要内容:
- mapreduce编程模型再解释;
- ob提交方式:
- windows->yarn
- windows->local ;
- linux->local
- linux->yarn;
- 本地运行debug调试观察
mapreduce体系很庞大,我们需要一条合适的线,来慢慢的去理解和学习。
1、mapreduce编程模型和mapreduce模型实现程序之间的关系
1.1、mapreduce的编程模型
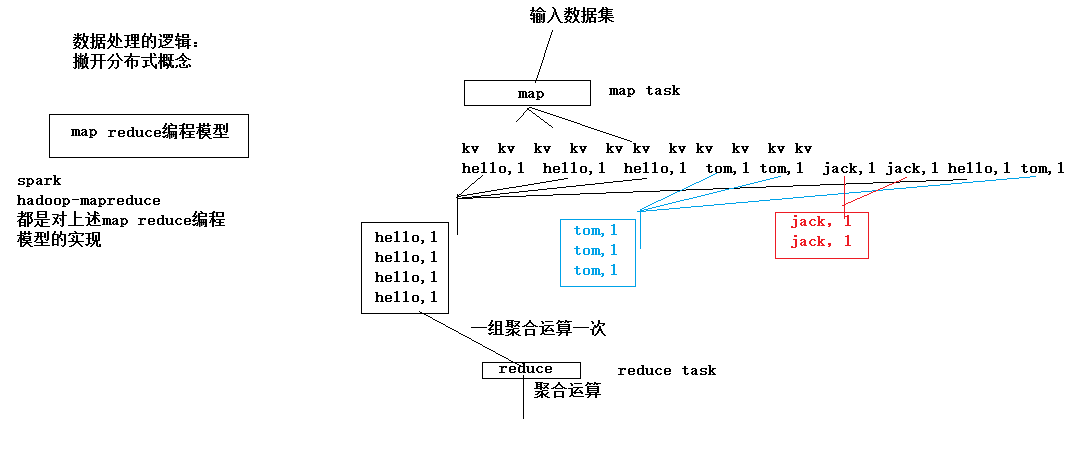
对mapreduce的总结:
如果只考虑数据处理的逻辑,撇开分布式的概念,其实mapreduce就只是一个编程模型了,而不是一个框架了。在这个编程模型里数据处理分为两个节点,一个map阶段一个reduce阶段。
map阶段要做的事情:就是吧原始的输入数据转换成大量的key-value数据,结合wordcont实例,key相同的数据会作为一组,形成若干组数据,接着就是这些组数据,一组一组的进行reduce阶段处理,每组reduce一次。
reduce阶段要做的事情:一组(key相同的数据)聚合运算一次。
一wordcount为例:数据被一行一行的读进来,按照空格进行拆分,将句子形成一个个(word,1)形式的键值对,map阶段就结束了;reduce阶段就是把单词相同的数据作为一组进行聚合,聚合逻辑就是把该组内的全部value累加在一起。
1.2、关系梳理
以上就是mapreduce的编程模型,编程模型并不能代表hadoop中的mapreduce框架,mapreduce编程模型其实就是一种典型的数据运算的逻辑模型,无论是hadoop-mapreduce运算框架也好,还是spark运算框架也好,都是具体的程序,都是对mapreduce编程模型的一种实现。而且hadoop中实现该模型时,在map阶段写了一个程序叫做map Task,在reduce 阶段写了一个程序叫做reduce Task;子spark里面,只不过时换了另外的名字,思想都一样。
以后在写mapreduce程序的时候,在写业务逻辑的时候只需要考虑编程模型就可以了,框架已经将实现上的一些东西都封装起来了,也就是说,要编写一个业务逻辑我们需要考虑的是,map将来产生什么样的key-vlue,将来相同的key就会作为一组没reduce聚合一次。
2、job提交方式
2.1、windows-to-yarn / local
local:用于本地测试,无需打包成jar也无需提交。
Configuration conf = new Configuration();
//conf.set("fs.defaultFS", "file:///"); //默认指就是这样
//conf.set("mapreduce.framework.name", "local"); //默认就是这样
若出现如下,错误,需要将hadoop配入window的环境变量中,同时将hadoop的bin目录配置到path中。

yarn:【比较繁琐】
目前为止我们需要写一个mapper实现类实现map阶段的逻辑,和写一个reduce实现类实现reduce阶段的 逻辑,和一个job提交器,提交job。
提交方式有多中,在上个笔记中,介绍了windows跨平台提交到yarn集群中,比较麻烦需要指定文件系统,需要知名job提交到哪里运行,还需要提供有权限的hdfs用户,还需要兼容跨平台。如下:
// 在代码中设置JVM系统参数,用于给job对象来获取访问HDFS的用户身份
// 或者通过eclipse图形化界面来设置 -DHADOOP_USER_NAME=root
System.setProperty("HADOOP_USER_NAME", "root") ; Configuration conf = new Configuration();
// 1、设置job运行时要访问的默认文件系统, map阶段要去读数据,reduce阶段要写数据
conf.set("fs.defaultFS", "hdfs://hdp-01:9000");
// 2、设置job提交到哪去运行:有本地模拟的方式local
conf.set("mapreduce.framework.name", "yar n");
conf.set("yarn.resourcemanager.hostname", "hdp-01");
// 3、如果要从windows系统上运行这个job提交客户端程序,则需要加这个跨平台提交的参数
conf.set("mapreduce.app-submission.cross-platform","true");
2.2、linux-to-yarn / local
若不配是上述参数直接将jar包上传到hadoop集群中的任何一台机器上,在linxu机器中运行jar包中的job提交器(自己写的jobsubmit),工具类会将jar包提交给local or(yarn,要看linux机器的配置参数是yarn还是local)无需在配置上述提到的参数,为什么呢?
Configuration conf = new Configuration();
//没有指定默认文件系统
//没有指定mapreduce-job提交到哪里运行
job.getInstance(conf)
使用hadoop jar命令而不是java -cp path1:path2... xxx.xx.xx.jobsubmiter
hadoop jar会把这台机器上的hadoop安装包中的所有jar包,以及所有配置文件都加载到本次运行java程序的classpath中。

这就是不用配置上述提到的参数,的原因,job提交工具程序中有一行代码如下,会将类路径下的配置信息全部加载进去,会将mapred-defalut.xml读入。
Configuration conf = new Configuration();
/*
* 如果要在hadoop集群的某台机器上启动这个job提交客户端的话
* conf里面就不需要指定 fs.defaultFS mapreduce.framework.name
*
* 因为在集群机器上用 hadoop jar xx.jar cn.edu360.mr.wc.JobSubmitter2 命令来启动客户端main方法时,
* hadoop jar这个命令会将所在机器上的hadoop安装目录中的jar包和配置文件加入到运行时的classpath中
*
* 那么,我们的客户端main方法中的new Configuration()语句就会加载classpath中的配置文件,自然就有了
* fs.defaultFS 和 mapreduce.framework.name 和 yarn.resourcemanager.hostname 这些参数配置
*/
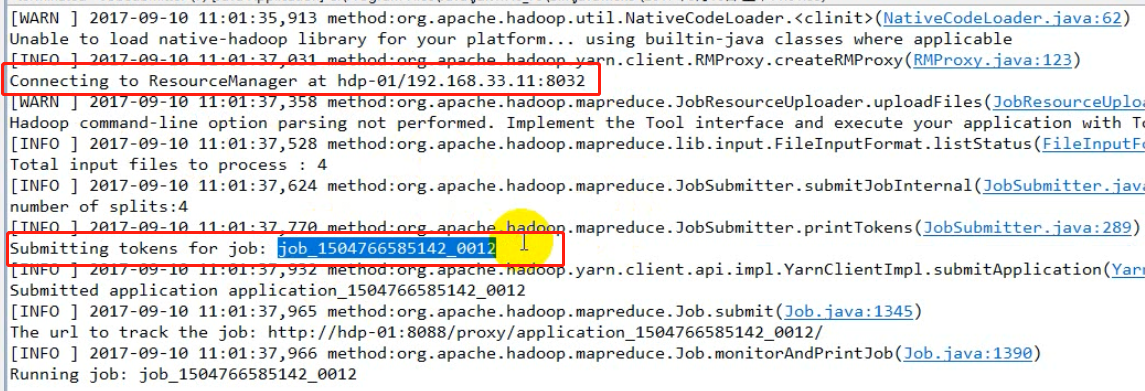
如下图,在window中提交job是,从日志信息可以看出,首先连接ResourceManager,连接成功之后ResourceManager为其指定本次的jobID。对比在linux中提交,发现linux中运行速度很快,而且没有日志显示连接ResourceManager,而且jobID也命名中有local字样,因为没有指定job提交到yarn集群,默认提交到了本地模拟器(LocalJobRunner)。因为参数mapreduce.framework.name默认locl。我们可以在代码中添加配置,无论提交到集群中的哪一台机子,都会去找yarn中的ResourceManager(配置文件中配置了地址),或者修改服务器的mapred-site.xml的参数值为yarn来覆盖jar包中mapred-default.xml中的local。
jar包中的mapred-defalut.xml中的默认值。



3、案例一
3.1、流量统计
现在有一批用户上网行为日志,需要统计日志记录中的用户上行流量和下行流量,以及流量总和;
需要统计多个value值时,可以考虑将多个value封装成一个valueBean对象,当然Bean对象需要实现hadoop的序列化接口(必须提供无参构造)
分析:Mapper<LongWritable, Text, Text, FlowBean>
Reducer<Text, FlowBean, Text, FlowBean>
1363157993044 182******61 94-**-**-**-**-18:XXXX-YYYY xxx.xxx.xxx.xx iface.qiyi.com 视频网站 15 12 1527 2106 200
3.1.1、自定义数据类型value
需要实现hadoop网络序列化接口,需要实现序列化和反序列化方法
本案例的功能:演示自定义数据类型如何实现hadoop的序列化接口
1、该类一定要保留空参构造函数
2、write方法中输出字段二进制数据的顺序 要与 readFields方法读取数据的顺序一致
/**
* hadoop系统在序列化该类的对象时要调用的方法
*/
@Override
public void write(DataOutput out) throws IOException {
} /**
* hadoop系统在反序列化该类的对象时要调用的方法
*/
@Override
public void readFields(DataInput in) throws IOException {
}
3.1.2、自定义类型Key-Comparable
mapReduce的reduce在收集key-value的时候会按照key进行排序(内部排序机制),因此提供自定义得数据类型,作为key,必须实现比较接口和序列化接口,hadoop提供了一个合二为一的接口WritableComparable extend writable,Comparable
3.2、topK统计
现有一批url访问日志,统计出访问量最高的前5个网站。
分析:当存在不止1个reduceTask的时候,每个reduceTask拿到的数据都是局部信息,统计得到的结果也都是局部结果。
方案1:只提供一个reduce Task,使用数据量很小的时候
方案2:多阶段mapreduce当数据量很大的时候,上述方法就失去了分布式的优势,此时可以提供多阶段的mapReduce任务,下一次任务利用上一次产生的数据。
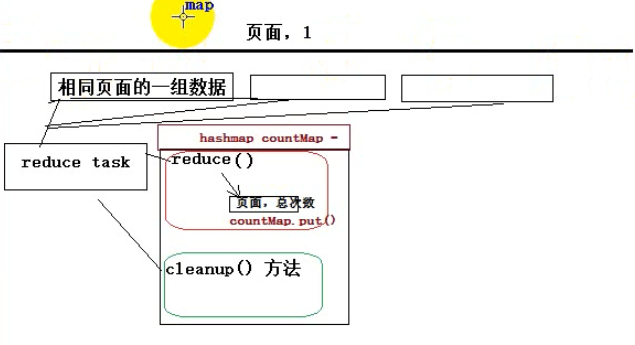
3.2.1、cleanup(Context context)
要点1:每一个reduce worker程序,会在处理完自己的所有数据后,调用一次cleanup方法
cleanup()函数的执行时机:假如该 reduceTask 接收到3组聚合数据,待3组数据的聚合工作都完成时候,会调用 一次cleanup()函数。
因此可以在cleanup()函数中进行结果排序,找出前几名。(TreeMap是有序的)
3.2.2、通过conf传参topK
要点2:如何向map和reduce传自定义参数
从JobSubmitter的main方法中,可以向map worker和reduce worker传递自定义参数(通过configuration对象来写入自定义参数);然后,我们的map方法和reduce方法中,可以通过context.getConfiguration()来取自定义参数
Configuration conf = new Configuration() //
这一句代码,会加载mr工程jar包中的hadoop依赖jar中的各默认配置文件*-default.xml
然后,会加载mr工程中自己的放置的*-site.xml
然后,还可以在代码中conf.set("参数名","参数值")
另外,mr工程打成jar包后,在hadoop集群的机器上,用hadoop jar mr.jar xx.yy.MainClass
运行时,hadoop jar命令会将这台机器上的hadoop安装目录中的所有jar包和配置文件通通加入运行时的classpath,
配置参数的优先级:
1、依赖jar中的默认配置
2、环境中的*-site.xml
3、工程中的*-site.xml
4、代码中set的参数
优先级一次增大,高优先级的参数值会覆盖低优先级的参数值
可以通过conf将参数传递到reducer中。
reducer方法有个参数Context context;context.getConfiguration()可以拿到job提交器中设置的参数。
传递方式有多多种
/**
* 通过代码设置参数
*/
conf.setInt("top.n", 3);
conf.setInt("top.n", Integer.parseInt(args[0]));
/**
* 通过属性配置文件获取参数
*/
Properties props = new Properties();
props.load(JobSubmitter.class.getClassLoader().getResourceAsStream("topn.properties"));
conf.setInt("top.n", Integer.parseInt(props.getProperty("top.n")));
通过main函数传递参数
通过.xml配置文件传参
new Configration()默认加载core-default.xml core-site.xml 不会加载jar包里的hdfs-site.xml hdfs-default.xml,mapred-site.xml
可以加载自定义的xml文件
<configuration>
<property>
<name>top.n</name>
<value>6</value>
</property>
</configuration>
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.addResource("xx-oo.xml");
System.out.println(conf.get("top.n"));
System.out.println(conf.get("mygirlfriend"));
}
3.3、全局排序
方案1:一个reduceTask,添加一个缓存和:treeMap(内存:数据量不可太大),在cleanup(Context context)处理treeMap中的数据
方案2:多阶段mapreduce,上一个mapreduce产生的结果(eg:url 总次数)作为下一侧mapreduce的输入。同时利用mapreduce对key的排序机制。二阶段只是用一个reduceTask即可,当一阶段产生的数据也更十分巨大时候,二级同样可以设置多个reduceTask,但要对聚合数据的分发机制进行控制(控制数据分发:比如:大于1000w的都发给reduceTask A, 500w-1000w的发给 B)。
需求:统计request.dat中每个页面被访问的总次数,同时,要求输出结果文件中的数据按照次数大小倒序排序
关键技术点:
mapreduce程序内置了一个排序机制:
map worker 和reduce worker ,都会对数据按照key的大小来排序
所以最终的输出结果中,一定是按照key有顺序的结果
思路:
本案例中,就可以利用这个机制来实现需求:
1、先写一个mr程序,将每个页面的访问总次数统计出来
2、再写第二个mr程序:
map阶段: 读取第一个mr产生的结果文件,将每一条数据解析成一个java对象UrlCountBean(封装着一个url和它的总次数),然后将这个对象作为key,null作为value返回
要点:这个java对象要实现WritableComparable接口,以让worker可以调用对象的compareTo方法来进行排序
reduce阶段:由于worker已经对收到的数据按照UrlCountBean的compareTo方法排了序,所以,在reduce方法中,只要将数据输出即可,最后的结果自然是按总次数大小的有序结果
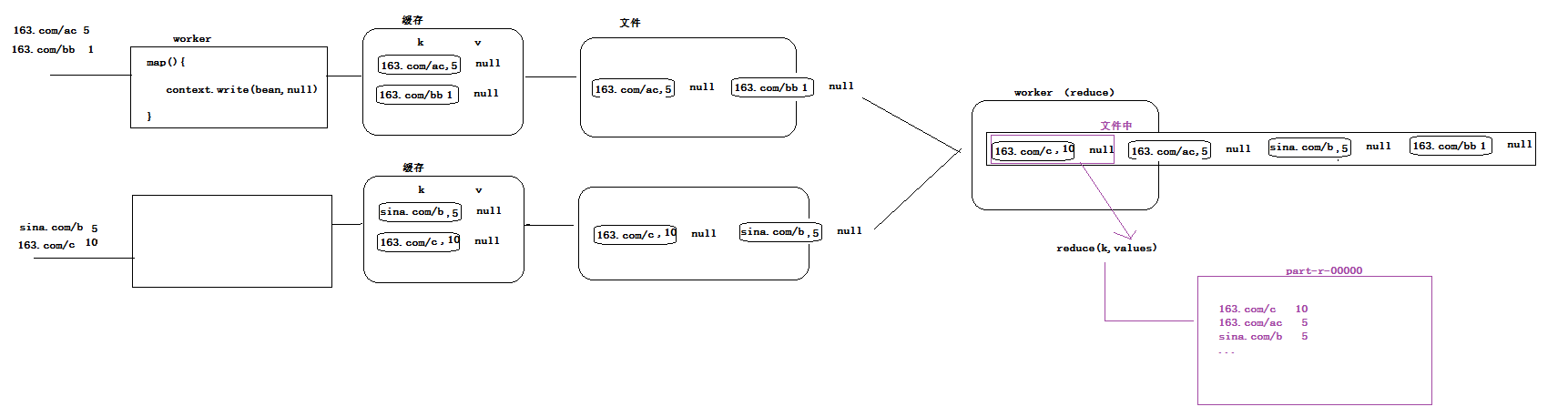
3.4、手机归属地分区
统计每一个用户的总流量信息,并且按照其归属地,将统计结果输出在不同的文件中
1、思路:
想办法让map端worker在将数据分区时,按照我们需要的按归属地划分
实现方式:自定义一个Partitioner
2、实现
先写一个自定义Paritioner
3.4.1、数据分发机制 Partitioner
决定mapTask产生的数据发给哪一个reduceTask,分发数据的动作有mapTask来完成,数据的分发逻辑有Partitioner指定。
分发数据的动作有mapTask来完成,数据的分发逻辑有Partitioner指定。
默认按照 key 的 hashcode % reduceTask个数

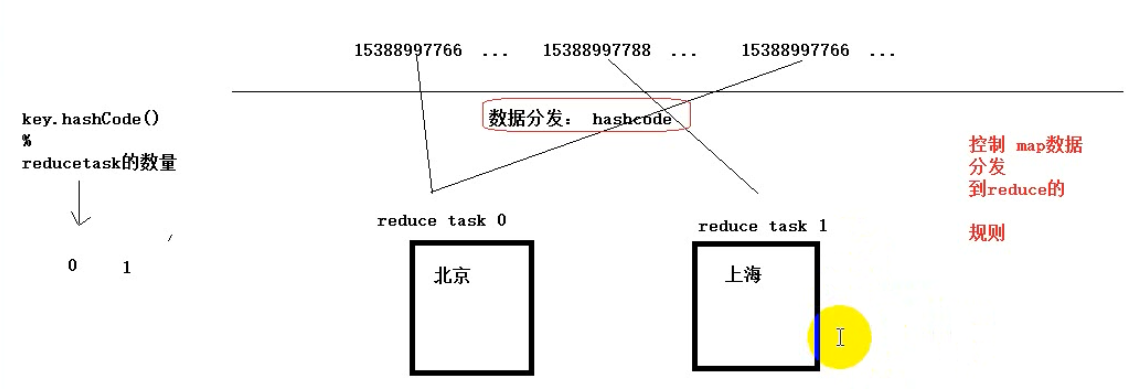
如果手机号作为key,但是要求同一个省的手机号要发给同一个reduceTask,这是就需要重新设计数据的分发机制。
一个规则在程序的世界里就是一个算法,一个算法在程序的世界里就是一段代码,一段代码在程序的世界里一定是封装在对象里的,一个对象在java的世界里一定是继承某个父类,或者是实现一个结构。
框架的灵活性就在于,我们一定可以自定义一个类来实现这个结构或者继承这个父类,提交给框架,改变原有的规则。
/**
* 本类是提供给MapTask用的
* MapTask通过这个类的getPartition方法,来计算它所产生的每一对kv数据该分发给哪一个reduce task
* @author ThinkPad
*
*/
public class ProvincePartitioner extends Partitioner<Text, FlowBean>{
static HashMap<String,Integer> codeMap = new HashMap<>();
static{ codeMap.put("135", 0);
codeMap.put("136", 1);
codeMap.put("137", 2);
codeMap.put("138", 3);
codeMap.put("139", 4); } @Override
public int getPartition(Text key, FlowBean value, int numPartitions) { Integer code = codeMap.get(key.toString().substring(0, 3));
return code==null?5:code;
} }
在job提交器中,指定数据分区逻辑
// 设置参数:maptask在做数据分区时,用哪个分区逻辑类 (如果不指定,它会用默认的HashPartitioner)
job.setPartitionerClass(ProvincePartitioner.class);
// 由于我们的ProvincePartitioner可能会产生6种分区号,所以,需要有6个reduce task来接收
job.setNumReduceTasks(6);
3.5、倒排索引
1、先写一个mr程序:统计出每个单词在每个文件中的总次数,
2、然后在写一个mr程序,读取上述结果数据:
map: 根据“-“”切,以单词做key,后面一段作为value
reduce: 拼接values里面的每一段,以单词做key,拼接结果做value,输出即可
| a.txt |
hello tom hello jim hello kitty hello rose |
hello-a.txt 4 hello-b.txt 4 hello-c.txt 4 java-c.txt 1 jerry-b.txt 1 jerry-c.txt 1 |
-> |
hello a.txt-->4 b.txt-->4 c.txt-->4 |
|
| b.txt |
hello jerry hello jim hello kitty hello jack |
-> |
java c.txt-->1 | ||
| c.txt |
hello jerry hello java hello c++ hello c++ |
jerry b.txt-->1 c.txt-->1 |
要点1:map方法中,如何获取所处理的这一行数据所在的文件名?
worker在调map方法时,会传入一个context,而context中包含了这个worker所读取的数据切片信息,而切片信息又包含这个切片所在的文件信息
那么,就可以在map中:
FileSplit split = FileSplit) context.getInputSplit(); String fileName = split.getpath().getName();
要点2:setup方法
worker在正式处理数据之前,会先调用一次setup方法,所以,常利用这个机制来做一些初始化操作;
3.5.1、数据切片
在mapTask创建之初就已经明确了要处理的切片,而且切片信息会被当作信息传递放在context(上下文,啥信息都有)中传递给map和reduce。
maptask和输入切片关系示意图:
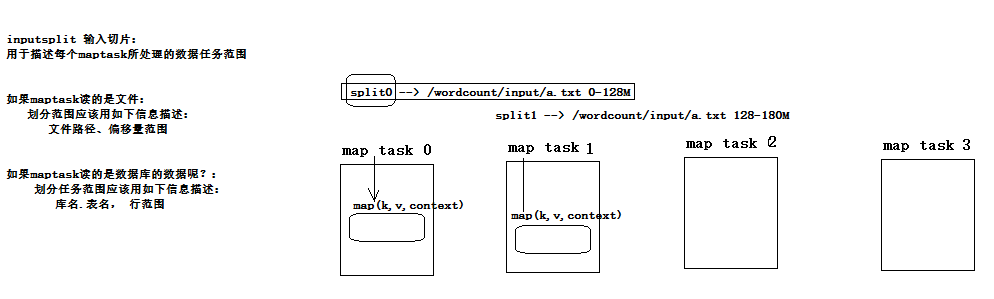
inputsplit是一个抽象类,mr框架在具体读数据的时候会调用不同的数据组件,比如文本组件,数据库组件,而不同的组件产生的数据切片split的描述信息是不同的。
// 从输入切片信息中获取当前正在处理的一行数据所属的文件
FileSplit inputSplit = (FileSplit) context.getInputSplit();
3.6、分组topn
(排序控制,分区控制,分组控制)
|
order001,u001,小米6,1999.9,2 order001,u001,雀巢咖啡,99.0,2 order001,u001,安慕希,250.0,2 order001,u001,经典红双喜,200.0,4 order001,u001,防水电脑包,400.0,2 order002,u002,小米手环,199.0,3 order002,u002,榴莲,15.0,10 order002,u002,苹果,4.5,20 order002,u002,肥皂,10.0,40 |
需要求出每一个订单中成交金额最大的三笔
本质:求分组TOPN
思路1:
map阶段:order作为key,orderBean作为value
// 从这里交给maptask的kv对象,会被maptask序列化后存储,所以不用担心覆盖的问题
context.write(k, orderBean);
reduce阶段:
收集同一个key(orderID为key)的所有orderBean(实现接口WritableComparable<>),将其放入集合中,对集合进行排序,输出前n个。
public class OrderBean implements WritableComparable<OrderBean> {
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.orderId);
out.writeUTF(this.userId);
out.writeUTF(this.pdtName);
out.writeFloat(this.price);
out.writeInt(this.number);
}
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.userId = in.readUTF();
this.pdtName = in.readUTF();
this.price = in.readFloat();
this.number = in.readInt();
this.amountFee = this.price * this.number;
}
// 比较规则:先比总金额,如果相同,再比商品名称
@Override
public int compareTo(OrderBean o) {
return Float.compare(o.getAmountFee(), this.getAmountFee())==0?this.pdtName.compareTo(o.getPdtName()):Float.compare(o.getAmountFee(), this.getAmountFee());
}
}
map中context.write(objectkey, objectvalue),,可以将objectkey提到成员变量的位置,每次在context.wirte之前,重新是指新的值,然后输出。context.wirte这里底层会将对象序列化并追加到临时的文件中去,而不会像在hashMap中反复add同一个不同修改值的对象。
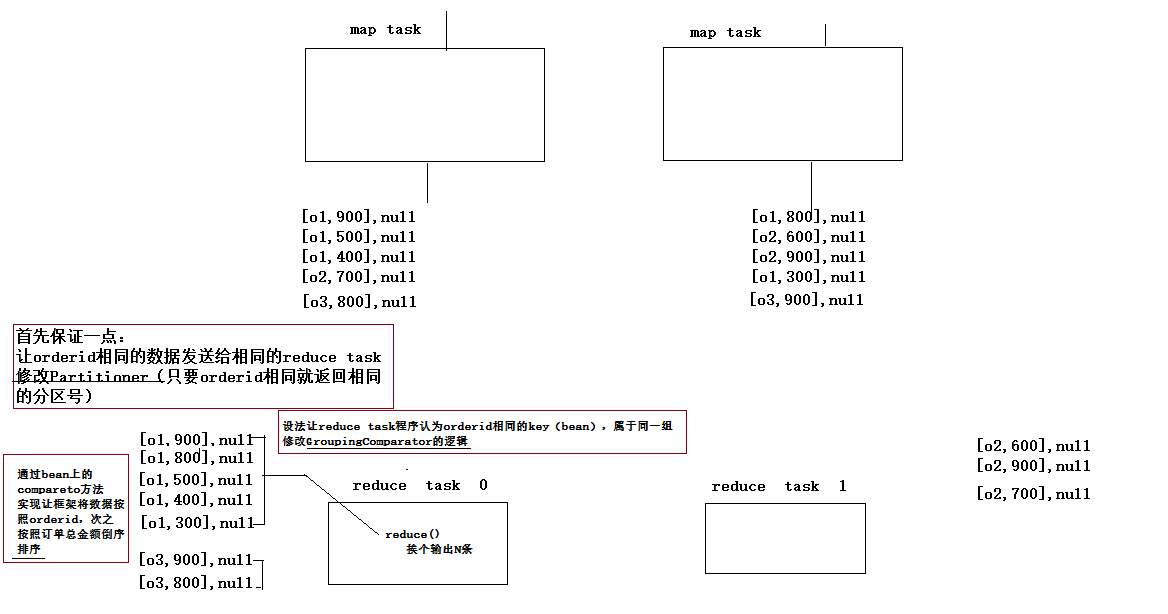
mr框架是一定会执行,分区,排序,分组的,因此没有必要在思路1的reduce中排序,可以考虑利用框架的排序功能,如下
思路2:(见GroupingComparator)
实现思路:
map: 读取数据切分字段,封装数据到一个bean中作为key传输,key要按照成交金额比大小
reduce:利用自定义GroupingComparator将数据按订单id进行分组,然后在reduce方法中输出每组数据的前N条即可
3.6.1、序列化
public static class OrderTopnMapper extends Mapper<LongWritable, Text, Text, OrderBean>{
OrderBean orderBean = new OrderBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, OrderBean>.Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
orderBean.set(fields[0], fields[1], fields[2], Float.parseFloat(fields[3]), Integer.parseInt(fields[4]));
k.set(fields[0]);
// 从这里交给maptask的kv对象,会被maptask序列化后存储,所以不用担心覆盖的问题
context.write(k, orderBean);
}
}
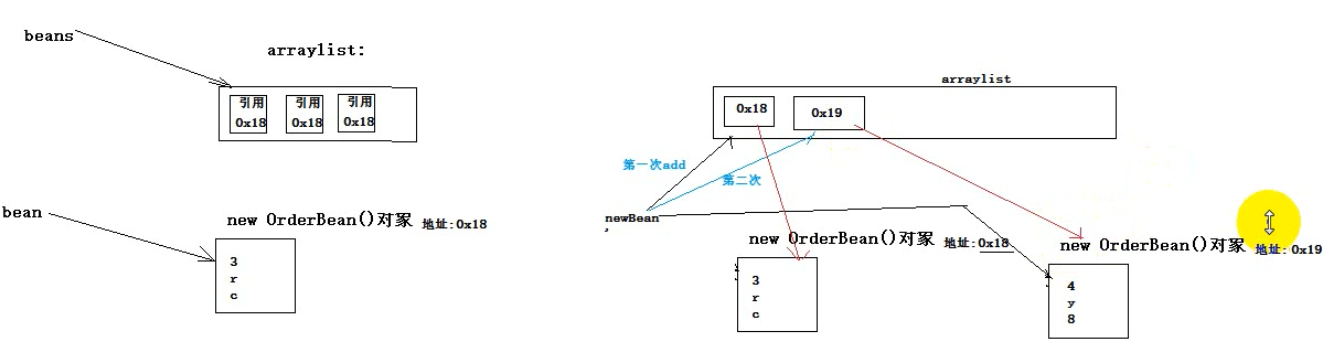
// reduce task提供的values迭代器,每次迭代返回给我们的都是同一个对象,只是set了不同的值
for (OrderBean orderBean : values) { // 构造一个新的对象,来存储本次迭代出来的值
OrderBean newBean = new OrderBean();
newBean.set(orderBean.getOrderId(), orderBean.getUserId(), orderBean.getPdtName(), orderBean.getPrice(), orderBean.getNumber()); beanList.add(newBean);
}
如下:hashmap中会保留三个一样的引用
public static void main(String[] args) throws FileNotFoundException, IOException {
ArrayList<OrderBean> beans = new ArrayList<>();
OrderBean bean = new OrderBean();
bean.set("1", "u", "a", 1.0f, 2);
bean.set("2", "t", "b", 2.0f, 3);
bean.set("3", "r", "c", 2.0f, 3);
System.out.println(beans);
}
3.6.2、GroupingComparator-如何控制分组
在数据按照特定的分发规则发给reduceTask之前,数据会传递给mr框架,框架对收到的数据按照key自带的排序规则进行排序,接下来将数据发给对应的reduceTask,对数据统一组的数据进行一次聚合,这里就涉及一个分组机制GroupingComparator(内部有一个compare(obj1,obj2)方法),因为reduceTask需要知道哪些数据是同一组。
还以分组topn为例
mapreduce机制总结 数据分发Partitioner、key值排序Comparable、GroupingComparator
GroupingComparator应用示例--求分组topn
1、reduce中values迭代器,没迭代一次,key的值也会跟新一次
2、reduce会把mapTask传递过来的数据保存到硬盘文件中(数据量很大的时候内存中是放不下的),既然放在文件中,就会涉及序列化和反序列化。
3、GroupingComparator中必须要需要明确反序列化的类型
分组topn
orderBean
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable; import org.apache.hadoop.io.WritableComparable; public class OrderBean implements WritableComparable<OrderBean>{ private String orderId;
private String userId;
private String pdtName;
private float price;
private int number;
private float amountFee; public void set(String orderId, String userId, String pdtName, float price, int number) {
this.orderId = orderId;
this.userId = userId;
this.pdtName = pdtName;
this.price = price;
this.number = number;
this.amountFee = price * number;
} public String getOrderId() {
return orderId;
} public void setOrderId(String orderId) {
this.orderId = orderId;
} public String getUserId() {
return userId;
} public void setUserId(String userId) {
this.userId = userId;
} public String getPdtName() {
return pdtName;
} public void setPdtName(String pdtName) {
this.pdtName = pdtName;
} public float getPrice() {
return price;
} public void setPrice(float price) {
this.price = price;
} public int getNumber() {
return number;
} public void setNumber(int number) {
this.number = number;
} public float getAmountFee() {
return amountFee;
} public void setAmountFee(float amountFee) {
this.amountFee = amountFee;
} @Override
public String toString() { return this.orderId + "," + this.userId + "," + this.pdtName + "," + this.price + "," + this.number + ","
+ this.amountFee;
} @Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.orderId);
out.writeUTF(this.userId);
out.writeUTF(this.pdtName);
out.writeFloat(this.price);
out.writeInt(this.number); } @Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.userId = in.readUTF();
this.pdtName = in.readUTF();
this.price = in.readFloat();
this.number = in.readInt();
this.amountFee = this.price * this.number;
} // 比较规则:先比总金额,如果相同,再比商品名称
@Override
public int compareTo(OrderBean o) { return this.orderId.compareTo(o.getOrderId())==0?Float.compare(o.getAmountFee(), this.getAmountFee()):this.orderId.compareTo(o.getOrderId()); } }
partitioner
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner; public class OrderIdPartitioner extends Partitioner<OrderBean, NullWritable>{ @Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
// 按照订单中的orderid来分发数据
return (key.getOrderId().hashCode() & Integer.MAX_VALUE) % numPartitions;
} }
groupcomparator
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; public class OrderIdGroupingComparator extends WritableComparator{ public OrderIdGroupingComparator() {
super(OrderBean.class,true);
} @Override
public int compare(WritableComparable a, WritableComparable b) { OrderBean o1 = (OrderBean) a;
OrderBean o2 = (OrderBean) b; return o1.getOrderId().compareTo(o2.getOrderId());
} }
mr、job
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class OrderTopn { public static class OrderTopnMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
OrderBean orderBean = new OrderBean();
NullWritable v = NullWritable.get();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException { String[] fields = value.toString().split(","); orderBean.set(fields[0], fields[1], fields[2], Float.parseFloat(fields[3]), Integer.parseInt(fields[4])); context.write(orderBean,v);
} } public static class OrderTopnReducer extends Reducer< OrderBean, NullWritable, OrderBean, NullWritable>{ /**
* 虽然reduce方法中的参数key只有一个,但是只要迭代器迭代一次,key中的值就会变
*/
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values,
Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
int i=0;
for (NullWritable v : values) {
context.write(key, v);
if(++i==3) return;
} } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // 默认只加载core-default.xml core-site.xml
conf.setInt("order.top.n", 2); Job job = Job.getInstance(conf); job.setJarByClass(OrderTopn.class); job.setMapperClass(OrderTopnMapper.class);
job.setReducerClass(OrderTopnReducer.class); job.setPartitionerClass(OrderIdPartitioner.class);//控制分区
job.setGroupingComparatorClass(OrderIdGroupingComparator.class);//控制分组 job.setNumReduceTasks(2); job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("F:\\mrdata\\order\\input"));
FileOutputFormat.setOutputPath(job, new Path("F:\\mrdata\\order\\out-3")); job.waitForCompletion(true);
} }
3.7、共同好友
|
A:B,C,D,F,E,O |
-> |
one map: B是A的好友 B是E的好友 B是J的好友 reduce: (B:A E J) A-E:B A-J:B E-j:B |
-> |
two map: wirte(A-E,B) recude: A-E:B,?,? |
3.8、控制输入,输出
不仅仅局限于读取hdfs文件,可以替换数据输入组件和数据输出组件,对象可以是数据库等。
FileInputFormat
|--TextInputFormat
|--SequenceFileInputFormat
|--DBInputFormat
FileOutputFormat
|--TextOutputFormat
|--SequenceFileOutputFormat
SequenceFile文件是hadoop定义的一种文件,里面存放的是大量key-value的对象序列化字节(文件头部还存放了key和value所属的类型名);

3.9、 数据倾斜
将key特别多的那组数据分散个不同的reduce。这样一来recude聚合的数据就会是局部的,有可能需要在做一步mapreduce,得到全局的结果。
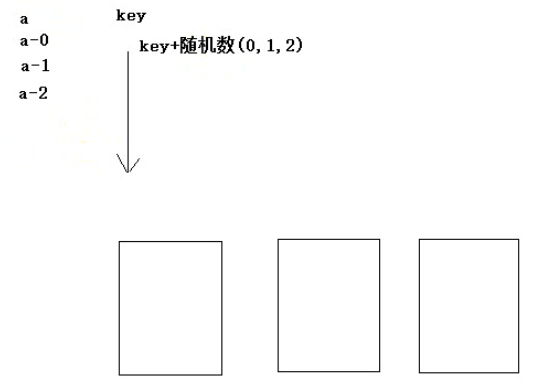
通用解决方案:将相同的key打散
具体做法:任何一个key都追加一个随机字符串/数字
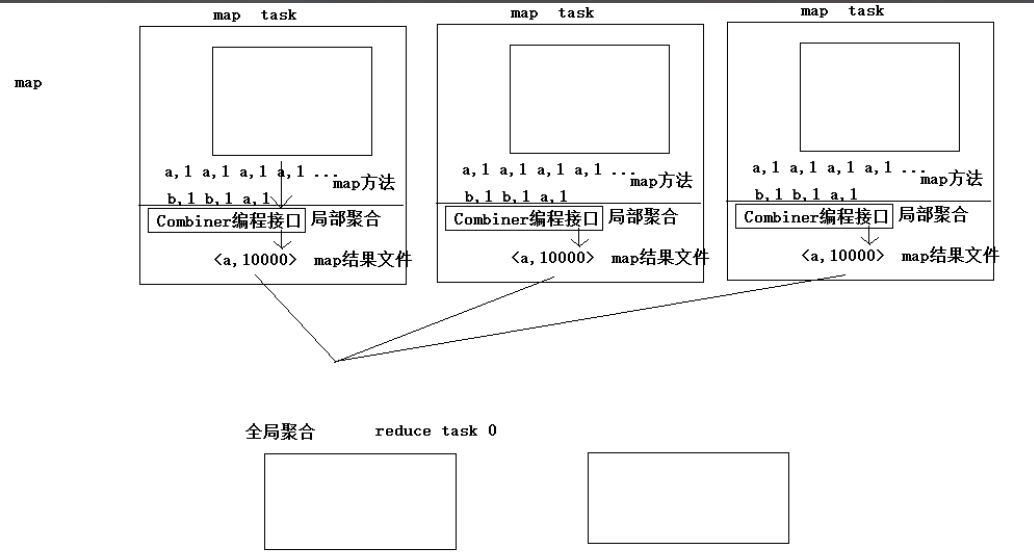
3.10、combiner
mapTask段可以利用combiner(直接使用reduce接口)进行局部聚合,reduceTask做的是全局聚合;
combiner主要用来避免mapTask产生大量数据,占用网络带宽,形成性能瓶颈;
当然也可以用来解决数据倾斜
// 设置maptask端的局部聚合逻辑类
job.setCombinerClass(WordcountReducer.class);
3.11、join场景
订单信息在一张表,用户信息在一张表;现要将用户信息追加到点单表中。
4、mapreduce内部核心机制原理
mr框架如何控制分区
mr框架如何控制排序
mr框架如何扣控制分组
mr框架如何输入输出组件
map逻辑
reduce逻辑
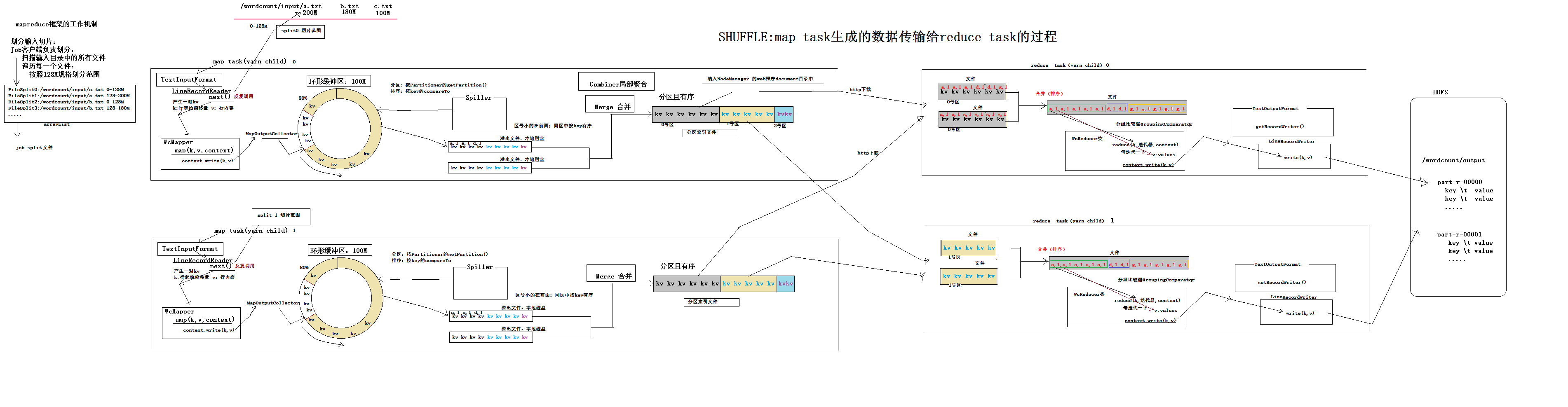
4.1、mapreduce框架内部核心工作机制详解
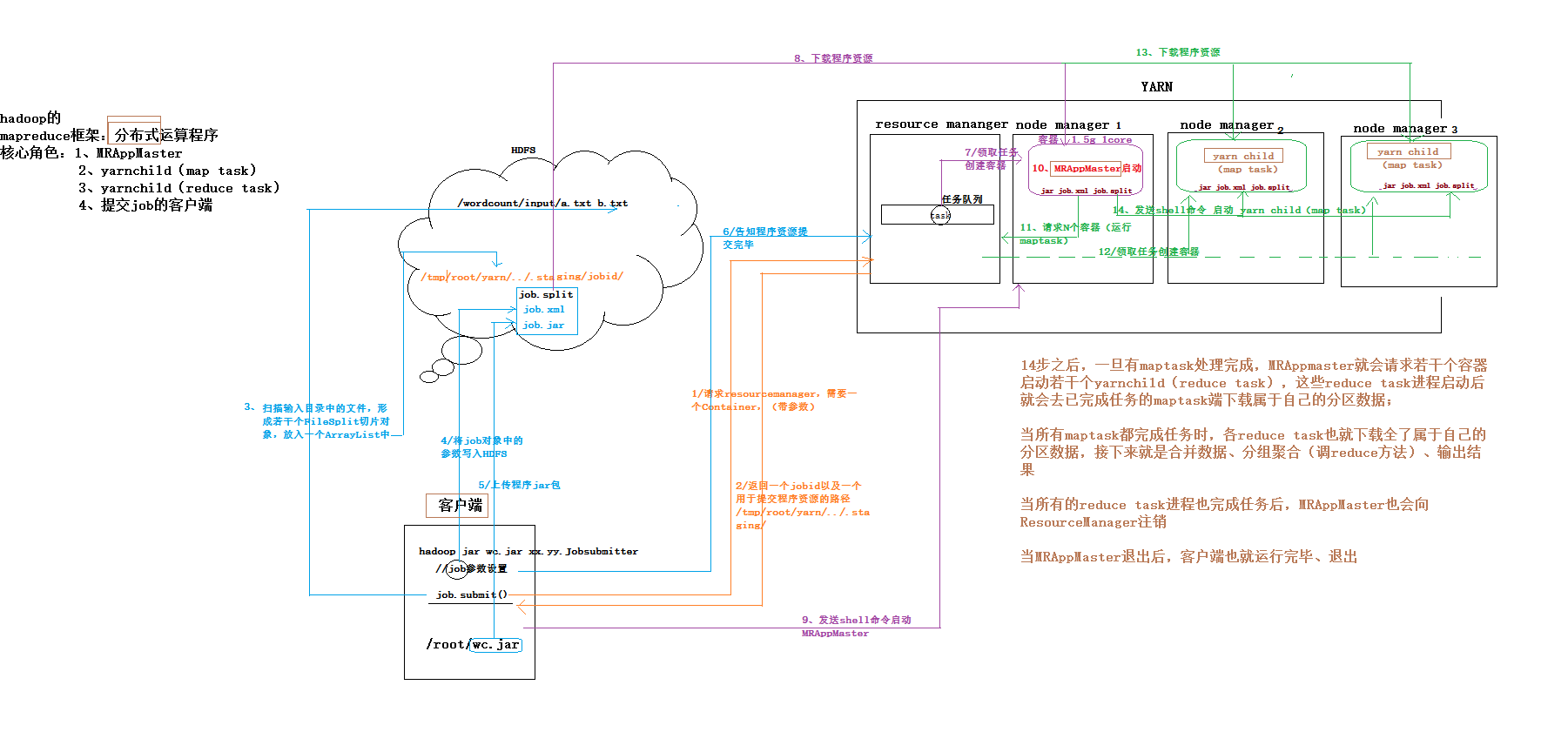
4.2、mapreduce程序在YARN上启动-运行-注销的全流程
mrappmaster
4.2.1、yarn的资源参数配置
yarn.scheduler.minimum-allocation-mb 默认值: // yarn分配一个容器时最低内存 yarn.scheduler.maximum-allocation-mb 默认值: // yarn分配一个容器时最大内存 yarn.scheduler.minimum-allocation-vcores 默认值: // yarn分配一个容器时最少cpu核数 yarn.scheduler.maximum-allocation-vcores 默认值: // yarn分配一个容器时最多cpu核数 // 1个nodemanager拥有的总内存资源 yarn.nodemanager.resource.memory-mb 默认值: // 1个nodemanager拥有的总cpu资源(逻辑的,表示比例而已) yarn.nodemanager.resource.cpu-vcores 默认值:
4.3、Hadoop-HA机制整体解析
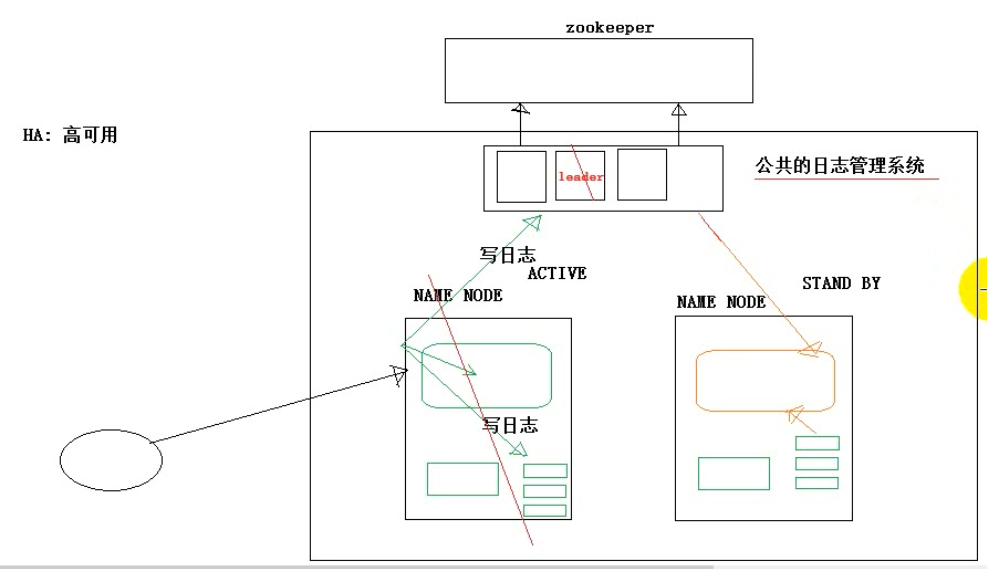
mapreduce要点复习

Hadoop之MapReduce学习笔记(二)的更多相关文章
- Hadoop权威指南学习笔记二
MapReduce简单介绍 声明:本文是本人基于Hadoop权威指南学习的一些个人理解和笔记,仅供学习參考,有什么不到之处还望指出,一起学习一起进步. 转载请注明:http://blog.csdn.n ...
- Hadoop之MapReduce学习笔记(一)
主要内容:mapreduce整体工作机制介绍:wordcont的编写(map逻辑 和 reduce逻辑)与提交集群运行:调度平台yarn的快速理解以及yarn集群的安装与启动. 1.mapreduce ...
- Hadoop源码学习笔记(1) ——第二季开始——找到Main函数及读一读Configure类
Hadoop源码学习笔记(1) ——找到Main函数及读一读Configure类 前面在第一季中,我们简单地研究了下Hadoop是什么,怎么用.在这开源的大牛作品的诱惑下,接下来我们要研究一下它是如何 ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
随机推荐
- 两个Fragment之间传递数据
1.第一个Fragment BlankFragment blankFragment = new BlankFragment();Bundle bundle = new Bundle();bundle. ...
- web——自己实现一个淘宝购物车页面
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...
- c++下为使用pimpl方法的类编写高效的swap函数
swap函数是c++中一个常用的函数,用于交换两对象的值,此外还用于在重载赋值运算符中处理自赋值情况和进行异常安全性编程(见下篇),标准模板库中swap的典型实现如下: namespace stl { ...
- CUDA Samples: matrix multiplication(C = A * B)
以下CUDA sample是分别用C++和CUDA实现的两矩阵相乘运算code即C= A*B,CUDA中包含了两种核函数的实现方法,第一种方法来自于CUDA Samples\v8.0\0_Simple ...
- BZOJ2938: [Poi2000]病毒(AC自动机)
2938: [Poi2000]病毒 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 1678 Solved: 849[Submit][Status][D ...
- bzoj 4570: [Scoi2016]妖怪 凸包
题目大意: http://www.lydsy.com/JudgeOnline/problem.php?id=4570 题解 我们知道如果一个怪物要取到攻击力的最大值,那么一定是把防御力都转化了 所以我 ...
- PAT 1016 部分A+B C语言
1016. 部分A+B (15) 正整数A的“DA(为1位整数)部分”定义为由A中所有DA组成的新整数PA.例如:给定A = 3862767,DA = 6,则A的“6部分”PA是66,因为A中有2个6 ...
- Linux下sniffer实现(转)
转发网址:https://blog.csdn.net/eqiang8271/article/details/8489769 //Example 1. #include <stdio.h> ...
- 基于http协议的加密传输方案
最近公司需要通过公网与其它平台完成接口对接,但是基于开发时间和其它因素的考虑,本次对接无法采用https协议实现.既然不能用https协议,那就退而求其次采用http协议吧! 那么问题来了!在对接的过 ...
- pthread访问调用信号线程的掩码(pthread_sigmask )
掩码: 信号掩码 在POSIX下,每个进程有一个信号掩码(signal mask).简单地说,信号掩码是一个"位图",其中每一位都对应着一种信号.如果位图中的某一位为1,就表示在执 ...