【hive】count() count(if) count(distinct if) sum(if)的区别
表名: user_active_day (用户日活表)
表内容:
user_id(用户id) user_is_new(是否新用户 1:新增用户 0:老用户) location_city(用户所在地区) partition_date(日期分区)
需求:
找出20180901至今的xxx地区的用户日活量以及新增用户量
思路:
筛选日期分区和地区,统计user_id的数量为用户日活量,统计user_is_new = 1的数量为新增用户量.
最开始写的hql语句
select partition_date,count(user_id),
count(if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
我们使用count(if())来进行筛选统计,但是效果并没有达到,出现的结果如下
20180901 16737 16737
根本就没有达到筛选的目的,为什么?
这就要从count的机制说起
首先count()是对数据进行计数,说白了就是你来一条数据我计数一条,我不关心你怎么分类,我只对数据计数
每条数据从if()函数出来,还是一条数据,所以count+1
所以count(user_id)跟count(if(user_id))没有任何的区别.
我们稍做修改
select partition_date,count(user_id),
count(distinct if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计,加了distinct去重
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 261
这次看着就像是对了吧,我们加了distinct进行去重
每次来一条数据先过if()然后再进行去重最后统计.但是实际上结果依旧是错误的.
我们来模拟一下筛选统计的过程
我们有这样四条数据
user_id user_is_new
1 1
2 0
3 1
4 0
表中的数据是一条一条遍历的,
(1)当user_id = 1的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 1),
然后我们把user_id = 1进行重复判断,我们用一个模拟容器来模拟去重,
从容器里找user_id = 1的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 1的数据放入,用于下条去重
(2)当user_id = 2的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现没有,不重复,所以通过我们把count+1,然后把0的数据放入,用于下条去重
(3)当user_id = 3的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 3),
然后我们把user_id = 3进行重复判断,
从容器里找user_id = 3的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 3的数据放入,用于下条去重
(4)当user_id = 4的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现重复,是之前user_id = 2的时候过if()转化成0的那条数据,所以count不执行
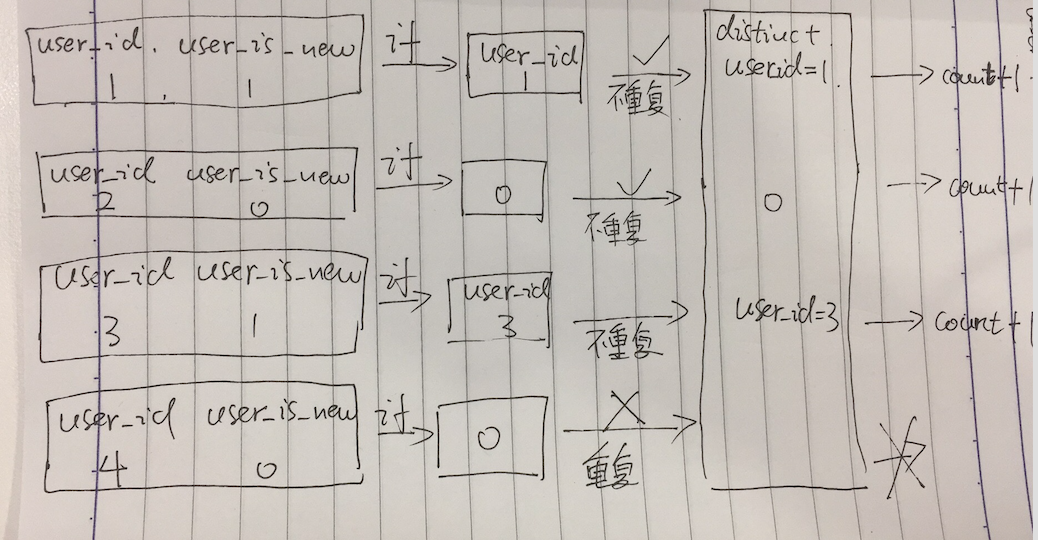
我们通过模拟count(distinct if)过程发现,在count的时候我们把不符合条件的最开始的那条语句也count进去了一次
导致最终结果比正确结果多了1.
我们在原基础语句上再减去1就是正确的hql语句
其实在日常中我们做分类筛选统计的时候一般是用sum来完成的,符合条件sum+1,不符合条件sum+0
select partition_date,count(user_id),
sum(if(user_is_new = 1, 1, 0)) --用sum进行筛选统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 260
sum(if)只试用于单个条件判断,如果筛选条件很多,我们可以用sum(case when then else end)来进行多条件筛选
注意,hive中并没有sum(distinct col1)这种使用方式,我们可以使用sum(col) group by col来达到相同效果.
【hive】count() count(if) count(distinct if) sum(if)的区别的更多相关文章
- 【MySQL】汇总数据 - avg()、count()、max()、min()、sum()函数的使用
第12章 汇总数据 文章目录 第12章 汇总数据 1.聚集函数 1.1.AVG()函数 avg() 1.2.COUNT()函数 count() 1.3. MAX()函数 max() 1.4.MIN() ...
- [MongoDB]count,gourp,distinct
摘要 上篇文章介绍了CRUD的操作,会了这些,基本上可以完成很多工作了.但如果遇到统计类的操作,那么就需要学习下本篇的内容了. 相关文章 [MongoDB]入门操作 [MongoDB]增删改查 cou ...
- 【优化】COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)、COUNT(允许为空列)、COUNT(DISTINCT 列名)
[优化]COUNT(1).COUNT(*).COUNT(常量).COUNT(主键).COUNT(ROWID).COUNT(非空列).COUNT(允许为空列).COUNT(DISTINCT 列名) 1. ...
- Django学习路17_聚合函数(Avg平均值,Count数量,Max最大,Min最小,Sum求和)基本使用
使用方法: 类名.objects.aggregate(聚合函数名('表的列名')) 聚合函数名: Avg 平均值 Count数量 Max 最大 Min 最小 Sum 求和 示例: Student.ob ...
- Oracle 中count(1) 和count(*) 的区别
count()与count(*)比较: 如果你的数据表没有主键,那么count()比count(*)快 如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快 如果你的表只有一 ...
- 【MySQL】技巧 之 count(*)、count(1)、count(col)
只看结果的话,Select Count(*) 和 Select Count(1) 两着返回结果是一样的. 假如表沒有主键(Primary key), 那么count(1)比count(*)快,如果有主 ...
- 关于count(1) 和 count(*)
Q:What is the difference between count(1) and count(*) in a sql queryeg.select count(1) from emp; an ...
- select count(*)和select count(1)的区别 (转)
A 一般情况下,Select Count (*)和Select Count(1)两着返回结果是一样的 假如表沒有主键(Primary key), 那么count(1)比count(*)快, 如果有主键 ...
- 【转载】Oracle 中count(1) 、count(*) 和count(列名) 函数的区别
1)count(1)与count(*)比较: 1.如果你的数据表没有主键,那么count(1)比count(*)快2.如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快3. ...
随机推荐
- Tfs 2015 代理池配置笔记
Tfs的构建代理池其实是在代理服务器上开启一个TFSBuild的代理服务,配好相关的Tfs地址后,就能在Tfs管理界面看到了. 如果是Tfs服务和发布代理是同一台服务器,具体操作详见: 安装TFS20 ...
- HTTPS握手
作用 内容加密 建立一个信息安全通道,来保证数据传输的安全: 身份认证 确认网站的真实性 数据完整性 防止内容被第三方冒充或者篡改 https的采用了对称加密和非对称加密.握手过程中采用非对称加密,得 ...
- UChome Feed 机制
Feed,本意是“饲料.饲养.(新闻的)广播等”. 我们就拿用户发表日志这个动作来简单看看Uchome的feed机制. 用户发布日志所使用的函数是 source/function_blog.php文件 ...
- python装饰器的应用案例
目录 一.过程编程 二.面向装饰器和函数的编程 三.二的加强版 一.过程编程 (一)需求:打印菱形 1.空格.*号组成的菱形 2.输入菱形上半部分的行数即可打印 3.支持循环输入 (二)代码 from ...
- java反射机制与动态代理
在学习HadoopRPC时.用到了函数调用.函数调用都是採用的java的反射机制和动态代理来实现的,所以如今回想下java的反射和动态代理的相关知识. 一.反射 JAVA反射机制定义: JAVA反射机 ...
- Redux 入门教程
Redux 入门教程(三):React-Redux 的用法(53@2016.09.21) Redux 入门教程(二):中间件与异步操作(32@2016.09.20) Redux 入门教程(一):基本用 ...
- java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
用Maven创建了一个spark sql项目,在引入spark sql jar包时引入的是: <dependency> <groupId>org.apache.spark< ...
- WebDriver API 实例详解(三)
二十一.模拟鼠标右键事件 被测试网页的网址: http://www.sogou.com Java语言版本的API实例代码: package test; import org.testng.annota ...
- PAT 1142 Maximal Clique[难]
1142 Maximal Clique (25 分) A clique is a subset of vertices of an undirected graph such that every t ...
- MySQL基础语句【学习笔记】
放在这里,以备后查. 1. 数据库, 数据库服务器, 数据库语言 数据库,是持久性数据的集合,供给定企业的应用程序系统使用,并且由一个数据库管理系统来管理: 数据库服务器,又称数据库管理系统,用来管理 ...