K-Means算法的收敛性和如何快速收敛超大的KMeans?
不多说,直接上干货!
面试很容易被问的:K-Means算法的收敛性。
在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Means与EM算法的关系,以及EM算法本身的收敛性证明中找到蛛丝马迹,下次不要再掉坑啊。
EM算法的收敛性
1.通过极大似然估计建立目标函数:

通过EM算法来找到似然函数的极大值,思路如下:
希望找到最好的参数θ,能够使最大似然目标函数取最大值。但是直接计算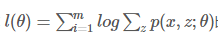 比较困难,所以我们希望能够找到一个不带隐变量z的函数
比较困难,所以我们希望能够找到一个不带隐变量z的函数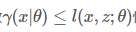 恒成立,并用
恒成立,并用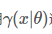
逼近目标函数。
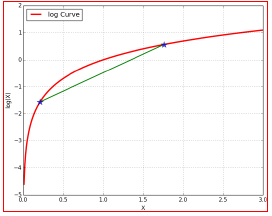
如下图所示: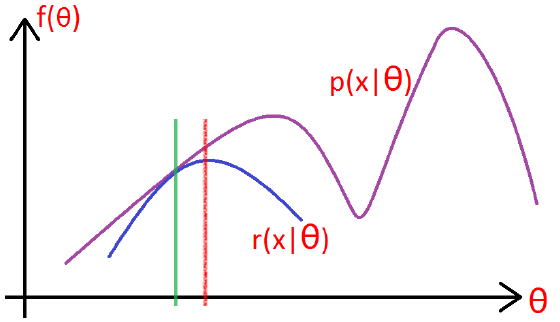
- 在绿色线位置,找到一个γγ函数,能够使得该函数最接近目标函数
- 固定γγ函数,找到最大值,然后更新θθ,得到红线;
- 对于红线位置的参数θ:
- 固定θθ,找到一个最好的函数γγ,使得该函数更接近目标函数。
重复该过程,直到收敛到局部最大值。
- 固定θθ,找到一个最好的函数γγ,使得该函数更接近目标函数。
2. 从Jensen不等式的角度来推导
令 是zz的一个分布,
是zz的一个分布,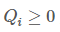 ,则:
,则:
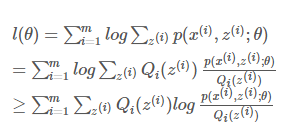
(对于log函数的Jensen不等式)
3.使等号成立的Q
尽量使≥≥取等号,相当于找到一个最逼近的下界:也就是Jensen不等式中,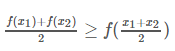 ,当且仅当x1=x2x1=x2时等号成立(很关键)。
,当且仅当x1=x2x1=x2时等号成立(很关键)。
对于EM的目标来说:应该使得loglog函数的自变量恒为常数,即: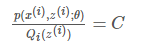
也就是分子的联合概率与分母的z的分布应该成正比,而由于Q是z的一个分布,所以应该保证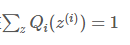

4.EM算法的框架
由上面的推导,可以得出EM的框架: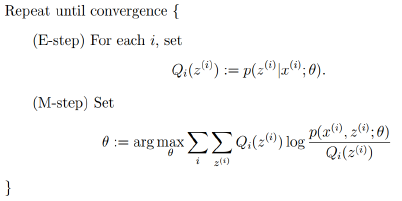
回到最初的思路,寻找一个最好的γγ函数来逼近目标函数,然后找γγ函数的最大值来更新参数θθ:
- E-step: 根据当前的参数θθ找到一个最优的函数γγ能够在当前位置最好的逼近目标函数;
- M-step: 对于当前找到的γγ函数,求函数取最大值时的参数θθ的值。
K-Means的收敛性
通过上面的分析,我们可以知道,在EM框架下,求得的参数θθ一定是收敛的,能够找到似然函数的最大值。那么K-Means是如何来保证收敛的呢?
目标函数
假设使用平方误差作为目标函数: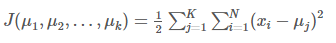
E-Step
固定参数μkμk, 将每个数据点分配到距离它本身最近的一个簇类中:
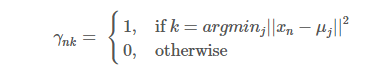
M-Step
固定数据点的分配,更新参数(中心点)μkμk:
所以,答案有了吧。为啥K-means会收敛呢?目标是使损失函数最小,在E-step时,找到一个最逼近目标的函数γγ;在M-step时,固定函数γγ,更新均值μμ(找到当前函数下的最好的值)。所以一定会收敛了.
如何快速收敛超大的KMeans?
最近,被一个牛人问道了这个问题:超亿个节点,进行KMeans的聚类,每次迭代都要进行K×亿的运算,如何能让这个迭代快速的收敛?
当场晕倒,从来没有考虑过这些问题,基础的数据挖据算法不考虑超大级别的运算问题。
回来想了想,再看看Mahout的KMeans的实现方法,觉得可以这么解决.
1. 第一次迭代的时候,正常进行,选取K个初始点,然后计算所有节点到这些K的距离,再分到不同的组,计算新的质心;
2. 后续迭代的时候,在第m次开始,每次不再计算每个点到所有K个质心的距离,仅仅计算上一次迭代中离这个节点最近的某几个(2到3)个质心的距离,决定分组的归属。对于其他的质心,因为距离实在太远,所以归属到那些组的可能性会非常非常小,所以不用再重复计算距离了。
3. 最后,还是用正常的迭代终止方法,结束迭代。
这个方法中,有几个地方需要仔细定义的。
第一,如何选择m次? 过早的话,后面的那个归属到远距离组的可能性会增加;过晚,则收敛的速度不够。
第二,如何选择最后要比较的那几个质心点数?数量过多则收敛的速度提高不明显,过少则还是有可能出现分组错误。
这两个问题应该都没有标准答案,就如同K值的选取。我自己思考的基本思路可以是:
1. 从第三次开始就开始比较每次每个质心的偏移量,亦即对于收敛的结束的标准可以划分两个阈值,接近优化的阈值(比如偏移范围在20%)和结束收敛的阈值(比如偏移范围在10%以内)。m次的选择可以从达到接近优化的阈值开始。
2. 选择比较的质心点数可以设定一个阈值,比较一个点到K个质心的距离,排序这些距离,或者固定选取一个数值,比如3个最近的点,或者按最近的20%那些质心点。
这些就是基本的思路。欢迎大家讨论。
K-Means算法的收敛性和如何快速收敛超大的KMeans?的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 再论EM算法的收敛性和K-Means的收敛性
标签(空格分隔): 机器学习 (最近被一波波的笔试+面试淹没了,但是在有两次面试时被问到了同一个问题:K-Means算法的收敛性.在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Mea ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- [ML从入门到入门] 支持向量机:从SVM的推导过程到SMO的收敛性讨论
前言 支持向量机(Support Vector Machine,SVM)在70年代由苏联人 Vladimir Vapnik 提出,主要用于处理二分类问题,也就是研究如何区分两类事物. 本文主要介绍支持 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- K中心点算法之PAM
一.PAM聚类算法: 选用簇中位置最中心的对象,试图对n个对象给出k个划分:代表对象也被称为是中心点,其他对象则被称为非代表对象:最初随机选择k个对象作为中心点,该算法反复地用非代表对 ...
随机推荐
- 3.html+.ashx(删除学生信息)
C03ListStu.ashx 0:false(删除);1:true(正常). (数据库里定义个BOOL型,TRUE表示正常FALSE表示删除) <html> <head> & ...
- MVC之Filter
过滤器的理解 Filter就是过滤器,在WebForm中,各种管道事件就是相当于过滤器,在MVC中,过滤器是单独的一种机制,分为方法过滤器和异常处理过滤器,方法过滤器实现的功能是在执行某一个请求得方法 ...
- poj3630 Phone List【Trie树】
Phone List Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 34805 Accepted: 9980 Descr ...
- FW:stash install
先下载破解安装包.http://pan.baidu.com/s/1mgumBbE 我的安装环境. 说明下,经过我的测试. 如果系统内存低于 512M, 就不要折腾了,非常卡. 推荐 2048M 内存. ...
- linux中gdb的可视化调试
今天get到一个在linux下gdb调试程序的技巧和大家分享一下!平时我们利用gcc进行编程,进行程序调试时,观察程序的跳转等不是这么直观.都是入下的界面! 但是如果我们在编译连接时上加了-g命令生成 ...
- Flask简介之简单应用
Flask 0.Flask简介 Flask是一个基于Python开发并且依赖jinja2模板和Werkzeug WSGI服务的一个微型框架,对于Werkzeug本质是Socket服务端,其用于接收ht ...
- 204-React DOM 元素
一.概述 为了提高性能和跨浏览器兼容性,React实现了一个独立于浏览器的DOM系统. 在React中,所有DOM属性和属性(包括事件处理程序)都应该是camelCased的.例如,HTML属性tab ...
- (转)《SSO CAS单点系列》之 实现一个SSO认证服务器是这样的!
上篇我们引入了SSO这个话题<15分钟了解SSO是个什么鬼!>.本篇我们一步步深入分析SSO实现机理,并亲自动手实现一个线上可用的SSO认证服务器!首先,我们来分析下单Web应用系统登录登 ...
- PAT 1138 Postorder Traversal [比较]
1138 Postorder Traversal (25 分) Suppose that all the keys in a binary tree are distinct positive int ...
- cocos代码研究(10)ActionEase子类学习笔记
理论部分 缓动动作的基类,继承自 ActionInterval类.ActionEase本身是一个抽象的概念父类,开发者最好不要在代码中直接创建它的对象,因为它没有具体的执行效果,这一类的子类速度变化大 ...