LR-SVM(有待重新整理)
参考:http://www.zhihu.com/question/26768865
总结:
1)在线学习:SVM不支持在线学习,LR支持
2)不平衡数据:SVM不依赖于数据的分布,所以数据是否平衡影响不是很大(有影响的);LR依赖于数据的分布所以不平衡的数据需要进行平衡处理
3)【解释2】SVM只受少数点的影响,同一类的数据的数量并不影响分类效果;LR每一个数据点对分类平面都是有影响的,它的影响力远离它到分类平面的距离指数递减
4)规范化:SVM依赖数据表达的距离测度,所以需要对数据先做normalization,否则准确率会受到影响;
【 SVM在计算margin有多"宽"的时候是依赖数据表达上的距离测度的,换句话说如果这个测度不好(badly scaled,这种情况在高维数据尤为显著),所求得的所谓Large margin就没有意义了】
LR的结果对是否规范化不敏感,需要normalization的原因主要是为了加快收敛速度,避免因为步长长而导致的不收敛的情况。
5)【调参】对参数的敏感程度:SVM比较依赖penalty的系数(需要交叉验证);(带正则项的)LR比较依赖对参数做L1 regularization的系数;【所以LR需要调的参数相对少】
6)结果解释:LR可以给出每个点属于每一类的概率,对于点击率预测等问题比较适合,而SVM是非概率的
7)训练速度:SVM收敛速度慢,SMO决定了参数迭代过程只能顺序执行;LR收敛速度相对快一些:可以使用梯度下降、拟牛顿法
【SVM对应的是一个有约束的凸优化问题(凸二次规划),只能使用SMO;LR对应的是一个无约束的最优化问题】
8)泛化性能:LR如果不使用正则化项的话,很容易过拟合,因为一旦特征多了,模型就会变得很复杂。可以手动减少特征或者使用正则化项。
SVM的模型复杂度和特征数目关系不大,所以过拟合的风险没那么大。
9)样本特点:SVM对于小样本、高维度数据(前提是规范化好了)的效果比较好;LR则不行
【SVM学习的参数少,所以需要样本少,而且参数只与支持向量有关,而与特征数目无关,所以可以处理高维;而LR的参数是跟特征数量呈正比的】
假设一个数据集已经被Linear SVM求解,那么往这个数据集里面增加或者删除更多的一类点并不会改变重新求解的Linear SVM平面。这就是它区分与LR的特点,下面我们在看看LR值得一提的是求解LR模型过程中,每一个数据点对分类平面都是有影响的,它的影响力远离它到分类平面的距离指数递减。换句话说,LR的解是受数据本身分布影响的。在实际应用中,如果数据维度很高,LR模型都会配合参数的L1 regularization
要说有什么本质区别,那就是两个模型对数据和参数的敏感程度不同,Linear SVM比较依赖penalty的系数和数据表达空间的测度,而(带正则项的)LR比较依赖对参数做L1 regularization的系数。但是由于他们或多或少都是线性分类器,所以实际上对低维度数据overfitting的能力都比较有限,相比之下对高维度数据,LR的表现会更加稳定,为什么呢?
因为Linear SVM在计算margin有多"宽"的时候是依赖数据表达上的距离测度的,换句话说如果这个测度不好(badly scaled,这种情况在高维数据尤为显著),所求得的所谓Large margin就没有意义了,这个问题即使换用kernel trick(比如用Gaussian kernel)也无法完全避免。所以使用Linear SVM之前一般都需要先对数据做normalization,而求解LR(without regularization)时则不需要或者结果不敏感。
、Linear SVM和LR都是线性分类器
、Linear SVM不直接依赖数据分布,分类平面不受一类点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance一般需要先对数据做balancingLinear
、SVM依赖数据表达的距离测度,所以需要对数据先做normalization;LR不受其影响
、Linear SVM依赖penalty的系数,实验中需要做validation
、Linear SVM和LR的performance都会受到outlier的影响
不带正则化的LR,其做normalization的目的是为了方便选择优化过程的起始值,不代表最后的解的performance会跟normalization相关,如果用最大熵模型解释,实际上优化目标是和距离测度无关的,而其线性约束是可以被放缩的(等式两边可同时乘以一个系数),所以做normalization只是为了求解优化模型过程中更容易选择初始值。
前者的任务是找到一个分类平面,让未知数据尽可能少地落在分类面错误的一边(最小化风险,或者说最大化分类面离最近的分类正确的正负例的距离);而后者则是在模型里假设了数据服从一个分布(exponential family),想找到一个参数解释这个分布而已(MAP inference)
LR可以给出每个点属于每一类的概率,而SVM是非概率的
逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
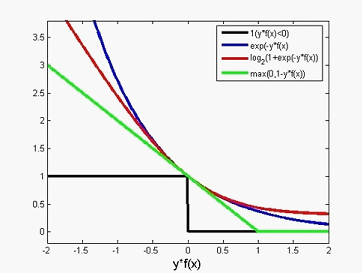
损失函数的关系
SVM的数据需要进行规范化的原因可以从其损失函数(或约束条件)可以看出来。大值数据会掩盖小值数据????错了。。。。
爆炸性消息!!!
LR也可以使用核技巧!
SVM需要存储支持向量,存储参数,用来预测
LR-SVM(有待重新整理)的更多相关文章
- SVM大致思路整理
(一)线性可分 我们忽略建立目标函数的过程,直接写出目标函数. 原问题: 首先,我们得到了目标函数: 这是一个凸优化问题,直接可以用软件可以求解: 对偶问题: 原问题根据一系列的变换,可写成: 满足某 ...
- 支持向量机(SVM)公式整理
支持向量机可以分为三类: 线性可分的情况 ==> 硬间隔最大化 ==> 硬间隔SVM 近似线性可分的情况 ==> 软间隔最大化 ==> 线性支持向量机 线性不可分的情况 ==& ...
- SVM 与 LR的异同
LR & SVM 的区别 相同点 LR和SVM都是分类算法. 如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的. LR和SVM都是监督学习算法. LR和SVM ...
- 【笔记】LR录制方式和常用函数
本文为本人复习LR时,笔记整理.以备后续查阅. 注意:录制脚本时,选择不同的协议下录制时设置选项也是不相同的,我们这里介绍的是基于协议web(http/html)录制选项设置. 对于web(http/ ...
- 转:深度学习斯坦福cs231n 课程笔记
http://blog.csdn.net/dinosoft/article/details/51813615 前言 对于深度学习,新手我推荐先看UFLDL,不做assignment的话,一两个晚上就可 ...
- ML面试1000题系列(31-40)
本文总结ML面试常见的问题集 转载来源:https://blog.csdn.net/v_july_v/article/details/78121924 31.下列哪个不属于CRF模型对于HMM和MEM ...
- Predicting purchase behavior from social media-www2013
1.Information publication:www2013 author:Yongzheng Zhang 2.What 用社交媒体用户特征 预测用户购买商品类别(排序问题) 3.Dataset ...
- 【原创】-- Linux 下利用dnw进行USB下载
原帖地址: http://blog.csdn.net/jjzhoujun2010 http://blog.csdn.net/yf210yf/article/details/6700391 http:/ ...
- 腾讯云总监手把手教你,如何成为AI工程师?
作者:朱建平 腾讯云技术总监,腾讯TEG架构平台部专家工程师 1.关于人工智能的若干个错误认知 人工智能是AI工程师的事情,跟我没有什么关系 大数据和机器学习(AI) 是解决问题的一种途径和手段,具有 ...
随机推荐
- 小程序for循环绑定每组数据的id,并通过id获取里面某个数组的值的方法
WXML: <block wx:for="{{nums}}" wx:for-index='key' wx:for-item='item'> <view class ...
- nextcloud大文件无法上传
I think that if u got a small /tmp like i had u cant upload big file…My /tmp = 462M so i can upload ...
- 一个通过GINA拦截 盗窃登陆口令的病毒分析
病毒行为: 1\将资源中的DLL释放到当前目录下 2\设置注册表,将GINA DLL设置为上一步中释放的DLL DLL行为: 1\在DLL被进程装载时, 装载正常的msgina.dll, 并保存句柄, ...
- 复仇之路——我一定要学会linux系统
说起linux,我不知道大家对这几个字母有什么认识,是不是早已经对这个操作系统已经很熟悉了?还是不知道他是一个操作系统,只是知道他是一个英文单词?或是知道他是一个人的名字?亦或是一本叫做<Lin ...
- flask 第四章 偏函数 Local空间转时间 myLocalStack RunFlask+request 请求上下文
1 . 偏函数 (partial) from functools import partial def func(*args,**kwargs): a=args b=kwargs return a,b ...
- 【webpack学习笔记】a03-管理输出
webpack 中输出管理主要运用了两个插件: html-webpack-plugin clean-webpack-plugin 这两个插件可以满足常规的输出管理需求. html-webpack-pl ...
- linux修改主机名+免密认证+关闭防火墙
在很多软件安装的时候都有这些需求,因此在这里一起讲一下 修改主机名 简单的使用 hostnamectl 命令就好了 hostnamectl set-hostname NAME 免密认证 准备工作,修改 ...
- vmware安装CentOS开发环境搭建
CentOS开发环境搭建 一.安装系统 新建虚拟机 2.选择“自定义(高级)”,并点击[下一步] 3.选择虚拟机硬件兼容性,并点击[下一步] 4.选择“稍后安装操作系统”,并点击[下一步] 5.选 ...
- rtp传输音视频(纯c代码)
参考链接: 1. PES,TS,PS,RTP等流的打包格式解析之RTP流 https://blog.csdn.net/appledurian/article/details/73135343 2. ...
- 如何用css实现一个三角形?
昨天被人问到说如何用css实现一个三角形?em.... 当时被问到了,汗颜,今天找了一些帖子看了一下,也算是记录一下吧 代码如下: 实现效果: