snakemake使用小结
首先在linux 里配置conda
下载
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh
chmod +x Anaconda3-5.3.1-Linux-x86_64.sh
bash Anaconda3-5.3.1-Linux-x86_64.sh
安装完毕,如果忘记选择yes,敲conda命令报错“command not found" 加上source /root/anaconda3/etc/profile.d/conda.sh
conda env list 得到 /root/anaconda3
export PATH=~/anaconda3/bin:$PATH
不然全局无法使用conda命令,(但是重启putty好像就不管用了,还不清楚原因)
vs code可以不安装
安装tree命令,yum install tree
tree -af 可以查看树形文件结构
snakemake是纯python的任务流程工具(基于python3),以前商业环境用过control-M
https://snakemake.readthedocs.io/en/stable/
首先做个变异检测,就是和标准的序列做对比,有点类似于代码的compare,用过Beyond Compare或svn和git的筒子们应该很熟悉了,
但是基因序列是个非常大的序列文件,在linux也没有windows那样简便的图形操作见面,而且,这种对比工作是大量重复的,需要脚本化。
cd snakemake-snakemake-tutorial-623791d7ec6d
conda env create --name snakemake-tutorial --file environment.yaml
--------------------------------------------------------------
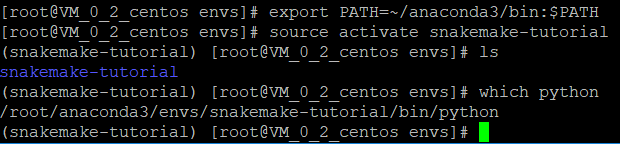
export PATH=~/anaconda3/bin:$PATH
source activate snakemake-tutorial
--------------------------------------------------------------
# 退出当前环境
source deactivate
这里使用到Samtools工具,具体使用方法可以参考https://blog.csdn.net/g863402758/article/details/53081342
他是一个用于处理sam与bam格式的工具软件,能够实现二进制查看、格式转换、排序及合并等功能,
结合sam格式中的flag、tag等信息,还可以完成比对结果的统计汇总。同时利用linux中的grep、awk等操作命令,
还可以大大扩展samtools的使用范围与功能。
conda install snakemake

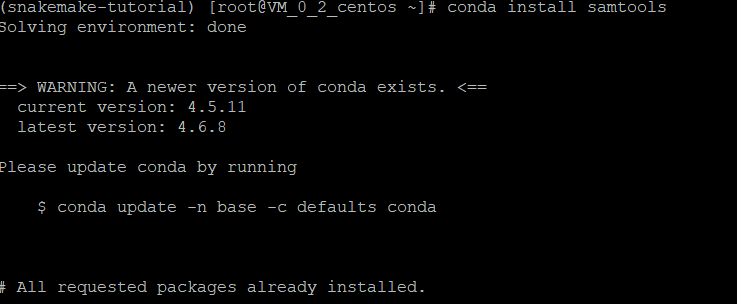
conda install samtools
bowtie2和samtools都是对比工具,bowtie2暂时没安装,安装方法先记录下
sudo wget https://jaist.dl.sourceforge.net/project/bowtie-bio/bowtie2/2.3.4.1/bowtie2-2.3.4.1-linux-x86_64.zip
unzip bowtie2-2.3.4.1-linux-x86_64.zip
vi /etc/environment
添加 bin 目录的路径,并用 : 隔开
source /etc/enviroment 使配置生效
开始写job脚本
rule bwa_map:
input:
"data/genome.fa",
"data/samples/A.fastq"
output:
"mapped_reads/A.bam"
shell:
"""
bwa mem {input} | samtools view -Sb - > {output}
"""
期间一直出一个错误,说Command must be given as string after the shell keyword运行snakemake -np mapped_reads/A.bam检查一下是否会出错

执行这个job,把-n去掉

可以看到,生成了A.bam文件

rule bwa_map:
input:
"data/genome.fa",
"data/samples/{sample}.fastq"
output:
"mapped_reads/{sample}.bam"
shell:
"""
bwa mem {input} | samtools view -Sb - > {output}
"""
将A改成{sample},在输入命令的时候加上你的参数,自动匹配上了,(注意此时文件夹貌似只能有一个脚本文件),cp了一个好像报错了
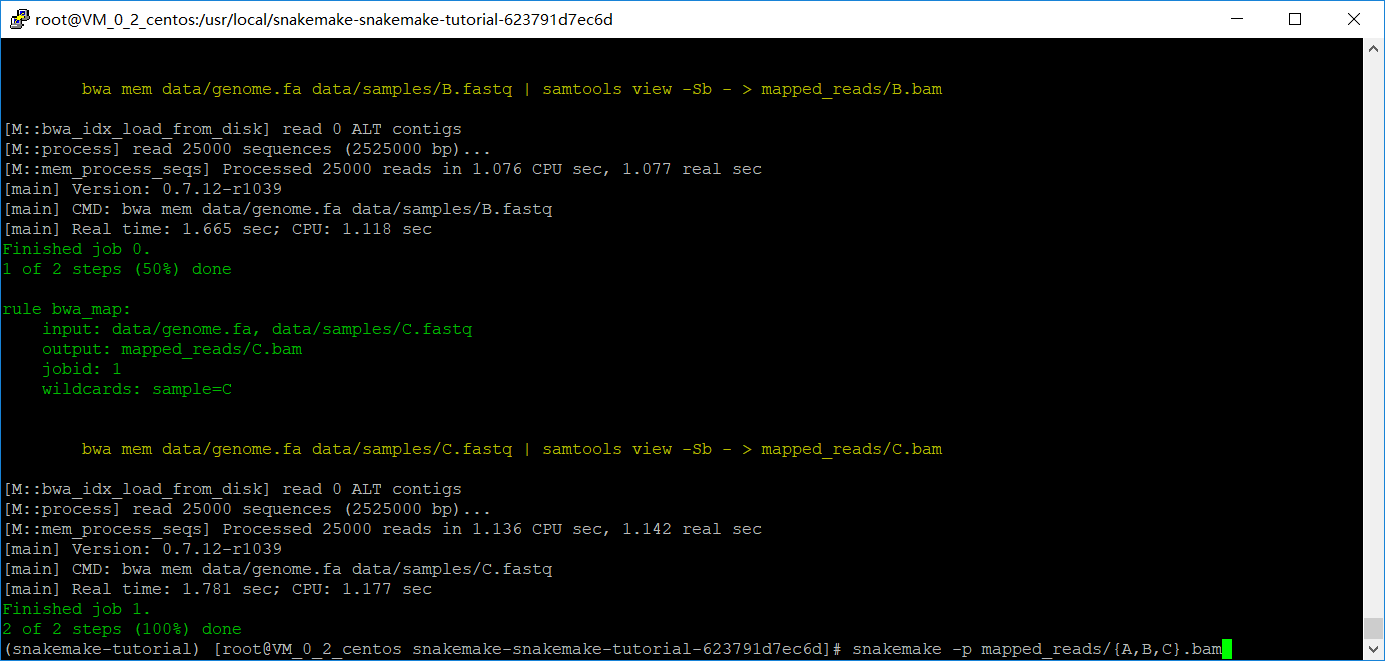
接下来,要做排序了,代码最后一起贴

可以使用dag选项和dot命令对“规则的执行和依赖关系”进行可视化,
snakemake --dag sorted_reads/{A,B,C}.bam.bai | dot -Tpdf > dag.pdf 这个命令好像会报错
snakemake --dag sorted_reads/{A,B,C}.bam.bai | dot -Tsvg > dag.svg
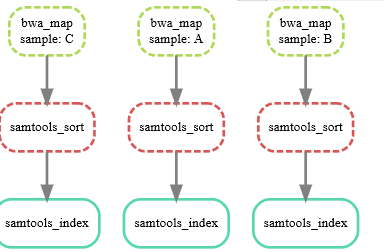
整合之前的BAM文件,做基因组变异识别
SAMPLES=["A","B","C"]
rule bcftools_call:
input:
fa="data/genome.fa",
bam=expand("sorted_reads/{sample}.bam", sample=SAMPLES),
bai=expand("sorted_reads/{sample}.bam.bai", sample=SAMPLES)
output:
"calls/all.vcf"
shell:
"samtools mpileup -g -f {input.fa} {input.bam} | "
"bcftools call -mv - > {output}"
其中expand是自动匹配变量求文件路径的语法糖
检查一下,snakemake -np calls/all.vcf
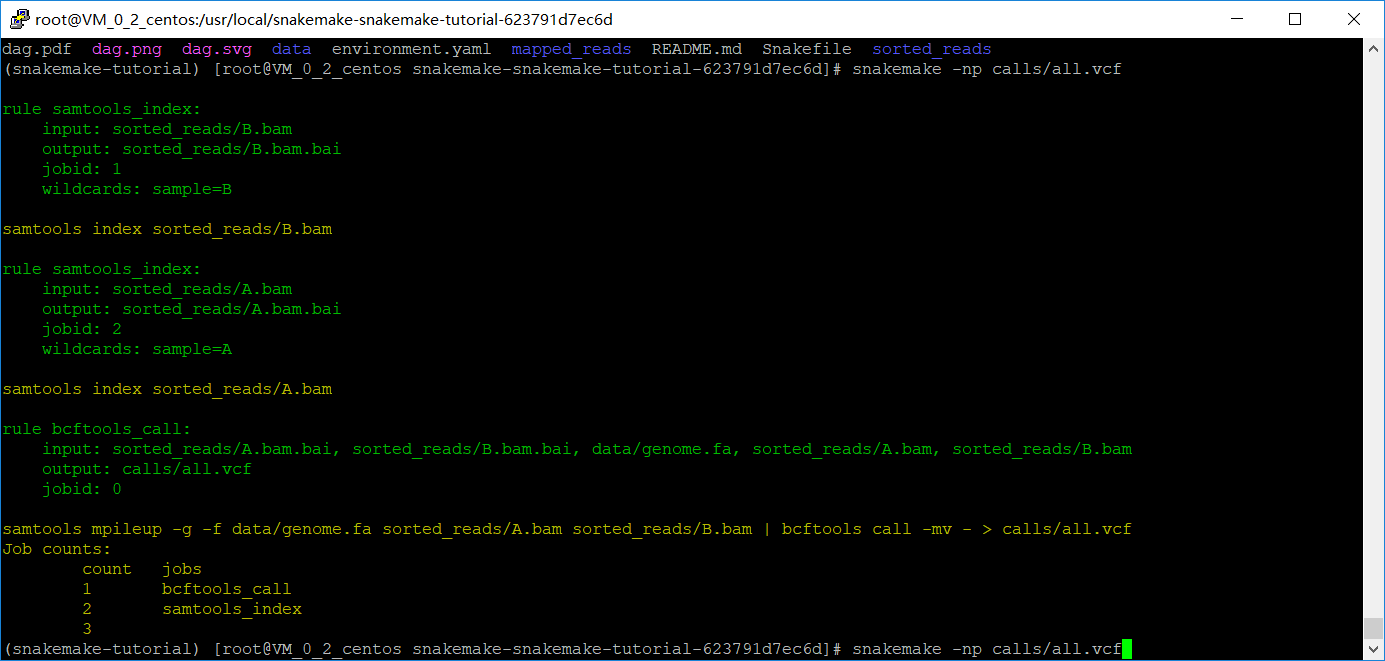
最后出report,以上都是在规则里执行shell脚本,snakemake的一个优点就是可以在规则里面写Python脚本,只需要把shell改成run,此外还不需要用到引号。
测试一下,snakemake -np report.html
画出流程图
snakemake --dag report.html | dot -Tsvg > final.svg
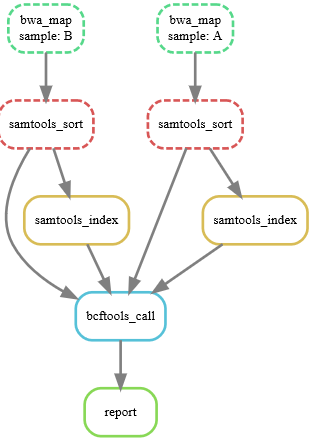
执行一下:snakemake -p report.html
可以看到生成了报告文件

到此,还有
rule all:
log:
多线程thread:
-j 指定cpu核心
params:
加载configfile: "config.yaml"
这几个功能没有操作,留个以后有空再处理
最后,在新建一个snakemake项目时,都先用conda create -n 项目名 python=版本号创建一个全局环境,用于安装一些常用的软件,例如bwa、samtools、seqkit等。然后用如下命令将环境导出成yaml文件
conda env export -n 项目名 -f environment.yaml
以后再部署的时候,
只需要conda env create -f environment.yaml
这个过程类似于ghost系统,或者打包虚拟机类似
参考了以下网址,感谢!https://www.jianshu.com/p/8e57fd2b81b2
http://pedagogix-tagc.univ-mrs.fr/courses/ABD/practical/snakemake/snake_intro.html
snakemake使用小结的更多相关文章
- 从零开始编写自己的C#框架(26)——小结
一直想写个总结,不过实在太忙了,所以一直拖啊拖啊,拖到现在,不过也好,有了这段时间的沉淀,发现自己又有了小小的进步.哈哈...... 原想框架开发的相关开发步骤.文档.代码.功能.部署等都简单的讲过了 ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
- java单向加密算法小结(2)--MD5哈希算法
上一篇文章整理了Base64算法的相关知识,严格来说,Base64只能算是一种编码方式而非加密算法,这一篇要说的MD5,其实也不算是加密算法,而是一种哈希算法,即将目标文本转化为固定长度,不可逆的字符 ...
- iOS--->微信支付小结
iOS--->微信支付小结 说起支付,除了支付宝支付之外,微信支付也是我们三方支付中最重要的方式之一,承接上面总结的支付宝,接下来把微信支付也总结了一下 ***那么首先还是由公司去创建并申请使用 ...
- iOS 之UITextFiled/UITextView小结
一:编辑被键盘遮挡的问题 参考自:http://blog.csdn.net/windkisshao/article/details/21398521 1.自定方法 ,用于移动视图 -(void)mov ...
- K近邻法(KNN)原理小结
K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用.比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出 ...
- scikit-learn随机森林调参小结
在Bagging与随机森林算法原理小结中,我们对随机森林(Random Forest, 以下简称RF)的原理做了总结.本文就从实践的角度对RF做一个总结.重点讲述scikit-learn中RF的调参注 ...
- Bagging与随机森林算法原理小结
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系.另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合. ...
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
随机推荐
- Python基础(六) python生成xml测试报告
思路: 1.使用xslt样式,这样可以很好的和xml结合,做出漂亮的报告 2.生成xml结构 xslt样式是个很有意思,也很强大的,现在用的很多,很方便就能做出一个漂亮的报告,可以百度一下,语法相当简 ...
- TCP 服务端接收数据解析工具类
package com.ivchat.common.util; import java.io.BufferedReader;import java.io.IOException;import java ...
- php实现栈操作(不用push pop 库函数)
直接上代码 <?php /*php不用库函数实现栈操作 * @author Geyaru 2019-04-20 */ class stack{ private $top = -1; //栈指针初 ...
- c#中WebApi开发遇到的坑
一.如何新建一个webApi项目 打开VS→找到解决方案→新建项目→类库或web应用程序→选择空的WebApi项目→在Global.asax文件的Application_Start方法中注册WebAp ...
- MySQL根据出生日期计算年龄
以前使用mysql不是很多,对mysql的函数也不是很熟悉,遇到这个问题第一时间百度搜索,搜索到这两种方法,这两种方法是排在百度第一条的博客. 方法一 SELECT DATE_FORMAT(FROM_ ...
- android 开发设计模式---单例模式
要保证单例,需要做以下几步 必须防止外部可以调用构造函数进行实例化,因此构造函数必须私有化. 必须定义一个静态函数获得该单例 单例使用volatile修饰 使用synchronized 进行同步处理, ...
- Blender学习
学习顺序(下面为引用他人的视频或博客) 51个必须知道的blender操作 https://www.bilibili.com/video/av4619930/ Blender常用快捷键一览表 http ...
- Typora/VSCode/Sublime 更改Markdown默认宽度样式等
Typora 所见即所得Markdown编辑器更改 最大宽度 C:\Users\Desk\AppData\Roaming\Typora\themes\github.css CSS第46行改为 max- ...
- subversion实用命令整理
使用命令在仓库中创建目录 使用命令查看仓库中的内容 使用命令删除仓库中的内容 创建目录 svn mkdir --parents -m 'makeSubDirectory' file:///path/t ...
- Truck Adblue Emulator For SCANIA
For sale online Truck Adblue Emulator For SCANIA See the price Where to buy? Truck Adblue Emulator F ...