python粗谈面向对象(一)
面向过程编程vs函数式编程
面向过程编程 以计算对象的元素个数为例。
str_1 = 'abcdefg'
count = 0
for i in str_1: # 统计字符串元素个数
count += 1
list_1 = [1,2,3,4]
count = 0
for i in list_1: # 统计列表元素个数
count += 1
由上面的内容我们可以看出如果还有需要统计元素的对象,那么我们还需要写一个for循环。如果有一百个需要统计的对象我们就需要写一百个for循环。但是可以发现for的功能都是一样统计的,都是统计对象元素个数。下面以函数的形式实现上面的例子:
def func(iter):
count = 0
for i in iter:
count += 1
return count
func('abcdefg') # 调用函数统计字符串
func([1,2,3,4]) # 调用函数统计列表
上面的代码先定义一个函数,函数主要用于统计可迭代对象元素的个数,在调用函数时将需要统计元素个数的对象传递给函数即可。代码结构相对于面向过程而言,减少了重复代码,并且结构也更加清晰。
总结:
- 面向函数编程相对于面向过程减少了代码冗余。
- 面向函数编程相对于面向过程代码可读性更高,结构更加清晰。
面向过程编程和面向对象的对比
面向过程编程
# auth 认证相关
def login():
pass
def regisgter():
pass
# account 账户相关
def get_user_pwd():
pass
def check_user_pwd():
pass
# 购物车相关
def shopping(username,money):
pass
def check_paidgoods(username,money):
pass
def check_unpaidgoods(username,money):
pass
def save(username,money):
pass
面向对象编程
class LoginHandler:
def login(self):
pass
def regisgter(self):
pass
class Account:
def get_user_pwd(self):
pass
def check_user_pwd(self):
pass
class ShoppingCar:
def shopping(username,money):
pass
def check_paidgoods(username,money):
pass
def check_unpaidgoods(username,money):
pass
def save(username,money):
pass
从对比可以发现面向对象的编程相比于函数编程代码的可读性更好,结构更加清晰,明确。
类
先来看一下类的示例:
class Personnel:
name = "小明" # 静态属性
age = 21
sex = "男"
def work(self): # 动态方法
print('人类需要工作来获取面包')
类:是一组相似功能的集合,让代码的组织结构更加清晰、规范化。
定义一个类。
class 是关键字与def用法相同,Personnel是此类的类名,类名使用驼峰(CamelCase)命名风格,首字母大写,私有类可用一个下划线开头。
类的结构从大方向来说就分为两部分:
- 属性(静态变量)。
- 方法(动态方法)。
使用类名.__dict__查看类中所有属性、方法。还可以使用.__dict__[属性]的方式查看单个属性,如下:
class Personnel:
name = "小明" # 静态属性
age = 21
def work(self): # 第二部分:方法 函数 动态属性
print('人类需要工作来获取面包')
print(Personnel.__dict__)# 使用dict可以查看类中所有属性,方法
print(Personnel.__dict__["name"]) # 打印类中'name'属性
使用类名.的方式来操作类中的属性和方法
class Personnel:
name = "小明" # 静态属性
age = 21
def work(self): # 第二部分:方法 函数 动态属性
print('人类需要工作来获取面包')
# 操作类中的属性
print(Personnel.name) # 查
Personnel.name = "小红" # 改
Personnel.sex = "女" # 增
del Personnel.age # 删
# 调用类中的方法
Personnel.work(1) # 这里需要随便给一个参数
类在调用自己内部方法时,需要传递一个参数,因为在类中定义实例化方法时会有一个默认参数self,self参数是类实例化对象的指针,用于在类的方法中可以使用对象的属性。所以类在调用方法时要传递一个参数给self。
类可以调用自己内部的属性和方法,如果想要修改属性可以用类进行操作,但是如果想调用类的实例化方法约定俗称使用对象调用,而不是使用类去调用。
类的实例化
class Personnel:
name = "小明" # 静态属性
age = 21
def work(self): # 动态方法
print("人类需要工作来获取面包")
obj = Personnel() # 实例化类
实例化类后就可以通过对象来调用类的方法和属性,对象是不可以修改类的属性和方法的。如果想在类中封装对象的私有属性,可在类中使用__init__函数来封装对象的属性。如下:
class Personnel:
name = "小明" # 静态属性
age = 21
def __init__(self,name,age): # 封装对象属性
self.name = name
self.age = age
obj = Personnel("葫芦娃",12) # 实例化类,并传递属性值
print(obj.name,obj.age) # 打印内容如下
葫芦娃 12
实例化Personnel时,总共发生了三件事:
- 在内存中为对象开辟了一个空间。
- 自动执行类中的__init__方法,并将这个对象空间(内存地址)传给了__init__方法的第一个位置参数self。
- 在__init__ 方法中通过self给对象封装私有属性。
在对象中操作属性:
class Personnel:
def __init__(self,name,age): # 封装对象属性
self.name = name
self.age = age
def work(self): # 第二部分:方法 函数 动态属性
print('人类需要工作来获取面包')
obj = Personnel("葫芦娃",12) # 实例化类,并传递属性值
print(obj.name) # 查
obj.name = "小红" # 改
obj.sex = "女" #增
del obj.age # 删
obj.work() # 调用类中方法
类中的方法一般都是通过对象执行的(除类方法,静态方法外),并且对象执行这些方法都会自动将对象空间传给方法中的第一个参数self以便对象在调用方法时可以使用自己的属性,所以类中的实例化方法都有一个参数self,参数名可以不是self,但是约定俗成函数的第一个参数都使用self。那self 是什么?
self其实就是类中方法(函数)的第一个位置参数,在对象调用类中方法时,会把自己的内存地址传给参数self,这样就可以在类中通过使用self来操作对象的属性了。
对象
对象:是类的具体体现(类的实例化 )。
对象属性的封装,有三种形式:
- 在类内部__init__()方法中封装对象的属性
- 在类内部实例化方法中封装对象的属性
- 在类外部添加对象属性
下面是代码示例:
class Personnel:
def __init__(self,name,age): # 在类__init__方法中封装对象属性
self.name = name
self.age = age
def work(self): # 在类的work()方法添加对象的属性
self.work = "扫地"
print(f"{self.name}通过{self.work}来获取面包")
obj = Personnel("小明",21) # 实例化类
obj.sex = "男" # 在类外添加对象属性
由此我们知道对象的属性可以在类的__init__方法中封装,也可以在类的实例化方法中进行封装,还可以在类外面进行添加,那对象是如何找到这些属性的呢?
通过观察可以发现__init__(self)和类的实例化方法都有一个默认参数self。我们知道self是对象空间指针,所以我们通过self封装对象的属性都是在对象空间的操作。所以也就不难理解对象可以找到这些属性了。至于可以在类外添加对象属性并且能找到也就不难理解了。
对象查找属性的顺序:对象空间 -> 类空间 -> 父类空间 -> object
类名查找属性的顺序:本类空间 -> 父类空间 -> object
面向对象三大特性
面向对象三大特性:封装、继承、多态
1. 封装: 是指将具有相似功能的属性,方法封装在某个对象内部,隐藏代码的实现细节不被外界发现,外界只能通过对象使用该接口,而不能通过任何形式修改对象内部实现,正是由于封装机制,程序在使用某一对象时不需要关心该对象的数据结构细节及实现操作的方法。使用封装能隐藏对象实现细节,使代码更易维护,同时因为不能直接调用、修改对象内部的私有信息,在一定程度上保证了系统安全性。类通过将函数和变量封装在内部,实现了比函数更高一级的封装。
2. 继承: 如果两个类是继承关系,继承的类称为子类(Subclass),而被继承的类称为基类、父类或超类(Base class、Super class)。继承最大的好处是子类获得了父类的全部变量和方法的同时,又可以根据需要封装自己的属性和方法。
3. 多态: Python其实默认就支持多态的,所谓多态是指一类事物可以有多种形态,而Python最大的特性就是一个变量会随着数据类型的改变而自我调整。如a="a" 是一个str类型,a=10就变成了int类型。
鸭子类型:看起来像鸭子就是鸭子(只是名字相似内部具体的实现不一定一样)例如:str类型中的方法index()查询下标,list中也有方法index()用于查下标虽然它们看起来像但是它们不是一个类中的方法。这么做的好处就是统一标准和规范。
类的继承
下面是一段简单代码示例:
class Aniaml(object):
life = "野外"
leg = 4
def __init__(self,name,age,color,food):
self.name = name
self.age = age
self.color = color
self.food = food
def eat(self):
print(f"{self.name}喜欢吃{self.food}")
class Cat(Aniaml):
pass
class Dog(Aniaml):
pass
上面的代码首先定义一个动物类,我们可以把这个类看成一个模板类,里面是一些动物共有的特性,然后创建小猫的类和小狗类继承动物类,这样小猫和小狗的类就继承了动物类的属性和方法,由此继承的优点总结如下:
- 增加了类的耦合性(耦合性不宜多,宜精)。
- 减少了重复代码。
- 使得代码更加规范化,合理化。
继承分为单继承和多继承两类。关于继承有个需要了解的地方,在Python2.2之前如果只是定义class A:那么这个A类将什么都不继承属于独立的类。我们将这种类称为经典类。在Python2.2以后面如果加上object如class A(object)这样便是新式类。在Python3.X中只有新式类,如果没有写object系统隐式的帮我们继承了object类。
单继承:如下示例就属于单继承
class Aniaml(object):
life = "野外"
leg = 4
def __init__(self,name,age,color,food):
self.name = name
self.age = age
self.color = color
self.food = food
def eat(self):
print(f"{self.name}喜欢吃{self.food}")
class Cat(Aniaml):
pass
class Dog(Aniaml):
pass
类的方法重写:
类的查找顺序我们知道首先是在本类中查找,如果本类没有到父类查找以此类推。如下示例:
class Aniaml(object):
life = "野外"
leg = 4
def __init__(self,name,age,color,food):
self.name = name
self.age = age
self.color = color
self.food = food
def eat(self):
print(f"{self.name}喜欢吃{self.food}")
class Cat(Aniaml):
def eat(self):
print(f"{self.name}在吃{self.food}")
obj = Cat("小花猫",21,"黑白花","鱼")
obj.eat() # 调用eat方法 # 打印内容如下
小花猫在吃鱼
上面代码中父类Aniaml中有eat()方法,子类Cat中也有eat方法。执行的结果和我们预想的一样。对象obj执行了本类中的eat方法没有执行父类的eat方法。我们将这种情况称为将父类的方法重写。
当我们想既要执行父类中的eat方法又执行子类中的eat方法可以使用supper方法,如下示例:
class Aniaml(object):
life = "野外"
leg = 4
def __init__(self,name,age,color,food):
self.name = name
self.age = age
self.color = color
self.food = food
def eat(self):
print("吃东西")
class Cat(Aniaml):
def eat(self): # 方法重写
print(f"{self.name}在吃{self.food}")
class Dog(Aniaml):
def eat(self):
super().eat() # 调用父类方法
print(f"{self.name}在吃{self.food}") obj_cat = Cat("小花猫",21,"黑白花","鱼")
obj_cat.eat() # 调用eat方法 obj_dog = Dog("二哈",2,"黑白","西瓜")
obj_dog.eat() # 打印内容如下
小花猫在吃鱼
吃东西
二哈在吃西瓜
多继承
一个类可以继承多个父类。
类的多继承涉及到了类的属性和方法的查找顺序。不像单继承一条路跑到黑一直像父类查找即可。多继承的查找顺序涉及到了深度优先算法和C3算法。
深度优先算法:是经典类中的查找顺序。首先从最左侧的父类开始向上查找,如果父类也是继承多个类那么继续从最左侧继续向上查找直到找到根然后回退查找右侧的父类。如下图示例:
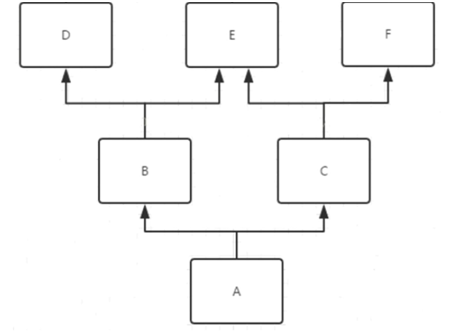
深度优先查找顺序如下图所示:
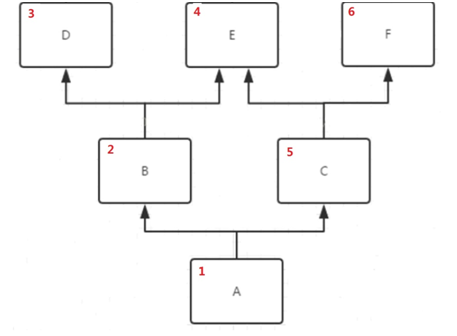
C3算法:主要是在新式类中体现.新式类主要体现在继承object类上,C3算法查找顺序遵循的是mro序列公式:
mro(子类(父类A,父类B))=[子类]+merge(mro(父类A),mro(父类B),[父类A,父类B])
表头和表尾
表头: 列表的第一个元素
表尾: 列表中除表头以外的元素集合(可以为空)
如:列表[A,B,C,D]其中A是表头,B,C,D是表尾.只有表头和表尾的概念没有其它.C3算法的核心是对比表头。
C3继承关系图
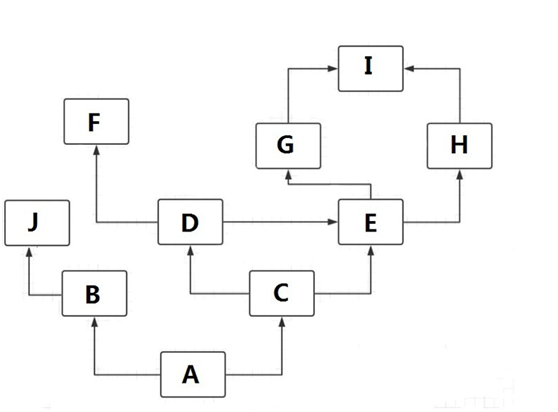
根据上图进行C3算法推算如下:
mro(A(B,C)) = [A] + merge(mro(B), mro(C), [B,C])
第一步:先计算mro(B)
mro(B) = mro(B(J)) = [B] + [J] = [B,J]
第二步:计算mro(C)
mro(C) = mro(C(D,E)) = [C] + merge(mro(D),mro(E),[D,E])
mro(C) = [C] + merge([D,F],mro(E),[D,E])
mro(E)= [E] +([G,I],[H,I],[G,H])
mro(E)= [E,G] +([I],[H,I],[H])
mro(E)= [E,G,H] +([I],[I])
mro(E)= [E,G,H,I]
mro(C) = [C] + merge([D,F],[E,G,H,I] ,[D,E])
= [C,D] + merge([F],[E,G,H,I] ,[E])
= [C,D,F] + merge([E,G,H,I] ,[E])
= [C,D,F,E] + merge([G,H,I])
= [C,D,F,E,G,H,I]
第三步计算mro(A(B,C)) = [A] + merge(mro(B), mro(C), [B,C])
mro(A) = [A] + merge([B,J], [C,D,F,E,G,H,I], [B,C])
= [A,B] + merge([J], [C,D,F,E,G,H,I], [C])
= [A,B,J] + merge( [C,D,F,E,G,H,I], [C])
= [A,B,J,C] + merge( [D,F,E,G,H,I],)
= [A,B,J,C,D,F,E,G,H,I]
最终C3查找顺序图如下:
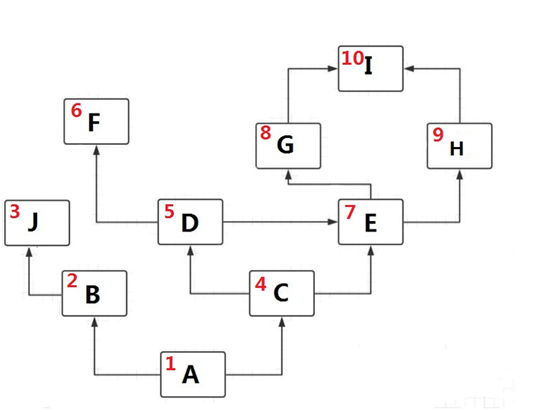
下一篇:super,类方法,双下方法,property,type简单介绍:https://www.cnblogs.com/caesar-id/p/10504964.html
python粗谈面向对象(一)的更多相关文章
- python粗谈面向对象(二)
浅谈super() super并不是一个函数,是一个类名,形如super(B, self)事实上调用了super类的初始化函数,产生了一个super对象:Python的多继承类是通过mro的方式来保证 ...
- python进阶_浅谈面向对象进阶
python进阶_浅谈面向对象进阶 学了面向对象三大特性继承,多态,封装.今天我们看看面向对象的一些进阶内容,反射和一些类的内置函数. 一.isinstance和issubclass class F ...
- python浅谈正则的常用方法
python浅谈正则的常用方法覆盖范围70%以上 上一次很多朋友写文字屏蔽说到要用正则表达,其实不是我不想用(我正则用得不是很多,看过我之前爬虫的都知道,我直接用BeautifulSoup的网页标签去 ...
- python 高级之面向对象初级
python 高级之面向对象初级 本节内容 类的创建 类的构造方法 面向对象之封装 面向对象之继承 面向对象之多态 面向对象之成员 property 1.类的创建 面向对象:对函数进行分类和封装,让开 ...
- sql 中的Bulk和C# 中的SqlBulkCopy批量插入数据 ( 回顾 and 粗谈 )
通常,我们会对于一个文本文件数据导入到数据库中,不多说,上代码. 首先,表结构如下. 其次,在我当前D盘中有个文本文件名为2.txt的文件. 在数据库中,可以这样通过一句代码插入. Bulk in ...
- python高级之面向对象高级
python高级之面向对象高级 本节内容 成员修饰符 特殊成员 类与对象 异常处理 反射/自省 单例模式 1.成员修饰符 python的类中只有私有成员和公有成员两种,不像c++中的类有公有成员(pu ...
- [python 译] 基于面向对象的分析和设计
[python 译] 基于面向对象的分析和设计 // */ // ]]> [python 译] 基于面向对象的分析和设计 Table of Contents 1 原文地址 2 引言 2.1 ...
- 【循序渐进学Python】7.面向对象的核心——类型(上)
我们知道Python是一门面向对象的脚本语言.从C#的角度来看:首先Python支持多继承.Python 类型成员通常都是public的,并且所有成员函数都是virtual的(可以直接重写). 1. ...
- 8.python笔记之面向对象基础
title: 8.Python笔记之面向对象基础 date: 2016-02-21 15:10:35 tags: Python categories: Python --- 面向对象思维导图 (来自1 ...
随机推荐
- 推荐一款接口 API 设计神器!
今天栈长给大家推荐一款接口 API 设计神器,传说中的,牛逼哄洪的 Swagger,它到底是什么?今天为大家揭开谜底! Swagger是什么? 官网:https://swagger.io/ Swagg ...
- JavaScript03-基本概念一
js包括:语法.语句.类型.关键字.保留字.操作符和对象. 语法.关键字.保留字 1.js中一切区分大小写,包括变量.函数名.操作符: 2.标识符规则,第一个字符必须是字母.下划线_.或者美元符号,其 ...
- bootcamp分区_BOOTCAMP 删除分区失败
mac 装了双系统,Mac OS X 分配的内存太少了,导致使用卡顿,要删掉windows系统. 在删除windows的时候出现 “您的磁盘不能恢复为单一的分区” 解决方案: 1.重启Mac,并按下 ...
- 华为oj之字符串最后一个单词的长度
题目: 字符串最后一个单词的长度 热度指数:9697 时间限制:1秒 空间限制:32768K 本题知识点: 字符串 题目描述 计算字符串最后一个单词的长度,单词以空格隔开. 输入描述: 一行字符串,非 ...
- Android--MP3播放器MediaPlayer
前言 Android提供了常见的音频.视频的编码.解码机制.借助于多媒体类MediaPlayer的支持,开发人员可以很方便在在应用中播放音频.视频.本篇博客主要讲解在Android平台下如何播放一个音 ...
- 大战Java虚拟机【3】—— 类加载机制
前言 当你的代码编译成class文件之后,那么虚拟机如何加载这些文件呢?我们需要知道虚拟机到底做了什么样的事情. 类的生命周期 加载--链接---初始化----使用---卸载 类加载过程 1.加载 读 ...
- leetcode — interleaving-string
/** * Source : https://oj.leetcode.com/problems/interleaving-string/ * * * Given s1, s2, s3, find wh ...
- Django学习笔记(6)——Form表单
知识储备:HTML表单form学习 表单,在前端页面中属于最常见的一个东西了.基本上网站信息的提交都用到了表单,所以下面来学习Django中优雅的表单系统:Form 表单的主要作用是在网页上提供一个图 ...
- DSAPI多功能组件编程应用-HTTP监听服务端与客户端
本文中,演示了使用DSAPI.网络相关.HTTP监听,快速建立服务端和客户端. HTTP监听服务端的作用,是监听指定计算机端口,以实现与IIS相同的解析服务,提供客户端的网页请求,当然,这不仅仅是应用 ...
- phpstudy等php本地环境运行缓慢的问题解决方法
我们经常会使用些一键安装包部署本地服务器环境.比如phpstudy.但是会有不少人发现,wordpress等使用数据库的程序打开或者切换页面的速度明显低于静态站点.甚至需要好几秒.这个问题一直困扰了我 ...