SSD-tensorflow-3 重新训练模型(vgg16)
一、修改pascalvoc_2007.py
生成自己的tfrecord文件后,修改训练数据shape——打开datasets文件夹中的pascalvoc_2007.py文件,
根据自己训练数据修改:NUM_CLASSES = 类别数(不包含背景);
# TRAIN_STATISTICS = {
# 'none': (0, 0),
# 'aeroplane': (238, 306),
# 'bicycle': (243, 353),
# 'bird': (330, 486),
# 'boat': (181, 290),
# 'bottle': (244, 505),
# 'bus': (186, 229),
# 'car': (713, 1250),
# 'cat': (337, 376),
# 'chair': (445, 798),
# 'cow': (141, 259),
# 'diningtable': (200, 215),
# 'dog': (421, 510),
# 'horse': (287, 362),
# 'motorbike': (245, 339),
# 'person': (2008, 4690),
# 'pottedplant': (245, 514),
# 'sheep': (96, 257),
# 'sofa': (229, 248),
# 'train': (261, 297),
# 'tvmonitor': (256, 324),
# 'total': (5011, 12608),
# }
# TEST_STATISTICS = {
# 'none': (0, 0),
# 'aeroplane': (1, 1),
# 'bicycle': (1, 1),
# 'bird': (1, 1),
# 'boat': (1, 1),
# 'bottle': (1, 1),
# 'bus': (1, 1),
# 'car': (1, 1),
# 'cat': (1, 1),
# 'chair': (1, 1),
# 'cow': (1, 1),
# 'diningtable': (1, 1),
# 'dog': (1, 1),
# 'horse': (1, 1),
# 'motorbike': (1, 1),
# 'person': (1, 1),
# 'pottedplant': (1, 1),
# 'sheep': (1, 1),
# 'sofa': (1, 1),
# 'train': (1, 1),
# 'tvmonitor': (1, 1),
# 'total': (20, 20),
# }
# SPLITS_TO_SIZES = {
# 'train': 5011,
# 'test': 4952,
# }
# SPLITS_TO_STATISTICS = {
# 'train': TRAIN_STATISTICS,
# 'test': TEST_STATISTICS,
# }
# NUM_CLASSES = 20
TRAIN_STATISTICS = {
'none': (0, 0),
'flower': (35,35),
'total': (35, 35),
}
TEST_STATISTICS = {
'none': (0, 0),
'flower': (15,15)
}
SPLITS_TO_SIZES = {
'train': 35,
'test': 15
}
SPLITS_TO_STATISTICS = {
'train': TRAIN_STATISTICS,
'test': TEST_STATISTICS,
}
NUM_CLASSES = 1 #类别,不包含背景
二、修改ssd_vgg_300.py
根据自己训练类别数修改96 和97行:等于类别数+1
三、修改eval_ssd_network.py
修改类别数和batchsize

四、修改train_ssd_network.py
数据格式改为 NHWC:

numclasses改为类别数加1:

batch_size该为自己设置的:

修改训练步数(None代表无限训练下去):

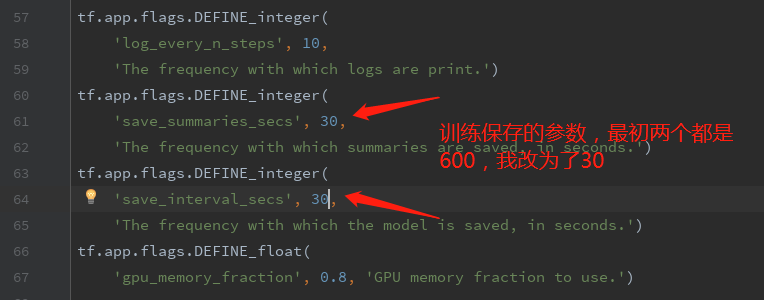
可以更改模型保存的参数:
五:加载VGG_16,重新训练模型
将VGG_16放在checkpoint文件夹下面:

从VGG16开始训练其中某些层的参数
# 通过加载预训练好的vgg16模型,对“voc07trainval+voc2012”进行训练
# 通过checkpoint_exclude_scopes指定哪些层的参数不需要从vgg16模型里面加载进来
# 通过trainable_scopes指定哪些层的参数是需要训练的,未指定的参数保持不变,若注释掉此命令,所有的参数均需要训练
DATASET_DIR=/home/doctorimage/kindlehe/common/dataset/VOC0712/
TRAIN_DIR=.././log_files/log_finetune/train_voc0712_20170816_1654_VGG16/
CHECKPOINT_PATH=../checkpoints/vgg_16.ckpt python3 ../train_ssd_network.py \
--train_dir=${TRAIN_DIR} \ #训练生成模型的存放路径
--dataset_dir=${DATASET_DIR} \ #数据存放路径
--dataset_name=pascalvoc_2007 \ #数据名的前缀
--dataset_split_name=train \
--model_name=ssd_300_vgg \ #加载的模型的名字
--checkpoint_path=${CHECKPOINT_PATH} \ #所加载模型的路径
--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \ #每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=24 \
--gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
接下来可以进行fine-tunning
(当你的模型通过vgg训练的模型收敛到大概o.5mAP的时候,可以进行这一步的fine-tune) # 通过加载预训练好的vgg16模型,对“voc07trainval+voc2012”进行训练
# 通过checkpoint_exclude_scopes指定哪些层的参数不需要从vgg16模型里面加载进来
# 通过trainable_scopes指定哪些层的参数是需要训练的,未指定的参数保持不变
DATASET_DIR=/home/doctorimage/kindlehe/common/dataset/VOC0712/
TRAIN_DIR=.././log_files/log_finetune/train_voc0712_20170816_1654_VGG16/
CHECKPOINT_PATH=./log_files/log_finetune/train_voc0712_20170712_1741_VGG16/model.ckpt-253287 python3 ../train_ssd_network.py \
--train_dir=${TRAIN_DIR} \ #训练生成模型的存放路径
--dataset_dir=${DATASET_DIR} \ #数据存放路径
--dataset_name=pascalvoc_2007 \ #数据名的前缀
--dataset_split_name=train \
--model_name=ssd_300_vgg \ #加载的模型的名字
--checkpoint_path=${CHECKPOINT_PATH} \ #所加载模型的路径
--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \ #每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=24 \
--gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
补充:还可以拿来训练vgg512
从自己训练的ssd_300_vgg模型开始训练ssd_512_vgg的模型。
因此ssd_300_vgg中没有block12,又因为block7,block8,block9,block10,block11,中的参数张量两个网络模型中不匹配,因此ssd_512_vgg中这几个模块的参数不从ssd_300_vgg模型中继承,因此使用checkpoint_exclude_scopes命令指出。
因为所有的参数均需要训练,因此不使用命令--trainable_scopes。
1 #/bin/bash
2 DATASET_DIR=/home/data/xxx/imagedata/xing_tf/train_tf/
3 TRAIN_DIR=/home/data/xxx/model/xing300512_model/
4 CHECKPOINT_PATH=/home/data/xxx/model/xing300_model/model.ckpt-60000 #加载的ssd_300_vgg模型
5 python3 ./train_ssd_network.py \
6 --train_dir=${TRAIN_DIR} \
7 --dataset_dir=${DATASET_DIR} \
8 --dataset_name=pascalvoc_2007 \
9 --dataset_split_name=train \
10 --model_name=ssd_512_vgg \
11 --checkpoint_path=${CHECKPOINT_PATH} \
12 --checkpoint_model_scope=ssd_300_vgg \
13 --checkpoint_exclude_scopes=ssd_512_vgg/block7,ssd_512_vgg/block7_box,ssd_512_vgg/block8,ssd_512_vgg/block8_box, ssd_512_vgg/block9,ssd_512_vgg/block9_box,ssd_512_vgg/block10,ssd_512_vgg/block10_box,ssd_512_vgg/block11,ssd_512_vgg/b lock11_box,ssd_512_vgg/block12,ssd_512_vgg/block12_box \
14 #--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block1 0,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_3 00_vgg/block10_box,ssd_300_vgg/block11_box \
15 --save_summaries_secs=28800 \
16 --save_interval_secs=28800 \
17 --weight_decay=0.0005 \
18 --optimizer=adam \
19 --learning_rate_decay_factor=0.94 \
20 --batch_size=16 \
21 --num_classes=4 \
22 -gpu_memory_fraction=0.8 \
23
六、全部从头开始训练自己的模型
# 注释掉CHECKPOINT_PATH,不提供初始化模型,让模型自己随机初始化权重,从头训练
# 删除checkpoint_exclude_scopes和trainable_scopes,因为是从头开始训练
# CHECKPOINT_PATH=./log_files/log_finetune/train_voc0712_20170712_1741_VGG16/model.ckpt-253287 python3 ../train_ssd_network.py \
--train_dir=${TRAIN_DIR} \ #训练生成模型的存放路径
--dataset_dir=${DATASET_DIR} \ #数据存放路径
--dataset_name=pascalvoc_2007 \ #数据名的前缀
--dataset_split_name=train \
--model_name=ssd_300_vgg \ #加载的模型的名字
#--checkpoint_path=${CHECKPOINT_PATH} \ #所加载模型的路径,这里注释掉
#--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名
--save_summaries_secs=60 \ #每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.00001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=32
SSD-tensorflow-3 重新训练模型(vgg16)的更多相关文章
- 【目标检测】SSD+Tensorflow 300&512 配置详解
SSD_300_vgg和SSD_512_vgg weights下载链接[需要科学上网~]: Model Training data Testing data mAP FPS SSD-300 VGG-b ...
- tensorflow利用预训练模型进行目标检测(一):安装tensorflow detection api
一.tensorflow安装 首先系统中已经安装了两个版本的tensorflow,一个是通过keras安装的, 一个是按照官网教程https://www.tensorflow.org/install/ ...
- 我的Keras使用总结(3)——利用bottleneck features进行微调预训练模型VGG16
Keras的预训练模型地址:https://github.com/fchollet/deep-learning-models/releases 一个稍微讲究一点的办法是,利用在大规模数据集上预训练好的 ...
- tensorflow利用预训练模型进行目标检测(二):预训练模型的使用
一.运行样例 官网链接:https://github.com/tensorflow/models/blob/master/research/object_detection/object_detect ...
- Tensorflow CPU mask-rcnn 训练模型
基于cpu版的tensorflow ,使用mask_rcnn训练识别箱子的模型 代码参考(https://blog.csdn.net/disiwei1012/article/details/79928 ...
- tensorflow利用预训练模型进行目标检测(四):检测中的精度问题以及evaluation
一.tensorflow提供的evaluation Inference and evaluation on the Open Images dataset:https://github.com/ten ...
- tensorflow利用预训练模型进行目标检测(三):将检测结果存入mysql数据库
mysql版本:5.7 : 数据库:rdshare:表captain_america3_sd用来记录某帧是否被检测.表captain_america3_d用来记录检测到的数据. python模块,包部 ...
- SSD:TensorFlow中的单次多重检测器
SSD:TensorFlow中的单次多重检测器 SSD Notebook 包含 SSD TensorFlow 的最小示例. 很快,就检测出了两个主要步骤:在图像上运行SSD网络,并使用通用算法(top ...
- 深度学习tensorflow实战笔记 用预训练好的VGG-16模型提取图像特征
1.首先就要下载模型结构 首先要做的就是下载训练好的模型结构和预训练好的模型,结构地址是:点击打开链接 模型结构如下: 文件test_vgg16.py可以用于提取特征.其中vgg16.npy是需要单独 ...
- TensorFlow迁移学习的识别花试验
最近学习了TensorFlow,发现一个模型叫vgg16,然后搭建环境跑了一下,觉得十分神奇,而且准确率十分的高.又上了一节选修课,关于人工智能,老师让做一个关于人工智能的试验,于是觉得vgg16很不 ...
随机推荐
- 那些年尝试过的效率工具之Total Commander
昨天电脑文件很乱,想整理一下发现移动.复制文件要来回目录切换很麻烦,突然就又想起了用Total Commander——简称TC,很久之前尝试过但没坚持使用的工具. 借此机会总结一下自己对TC的认识,后 ...
- Page Layout里的javascript (jquery)不执行
在page layout 中通过 _spBodyOnLoadFunctionNames.push("js 方法名") 的方式实现. 但切记,代码要放到 PlaceHolderMai ...
- vue+Element实现tree树形数据展示
组件: Element(地址:http://element.eleme.io/#/zh-CN/component/tree):Tree树形控件 <el-tree ref="expand ...
- nginx的location 匹配的规则问题
正则解释: ~ #匹配一个正则匹配,区分大小写~* #匹配一个正则,不区分大小写^~ #普通字符匹配,如果该选择匹配不匹配别的选项,一般用来匹配目录= #精确匹配 匹配案例:location = / ...
- tp框架--------where("1")
今天看代码的时候看到一个令我难以理解的sql查询语句,这是tp框架里的 return $this->where("1")->order('ar_id desc')-&g ...
- var和let的区别
//var 和let的区别 通过var定义的变量,作用域是整个封闭的函数,是全域的, 通过let定义的变量,作用域是在块级或者是子块中 for (let i = 0; i < 10; i++) ...
- MVC 单元测试xUnit初探
对于.NET项目 Web Api的业务逻辑后台开发[特别是做Web Api接口]而言,编写单元测试用例,会极大的减轻代码帮助与运行的方式.然而使用测试框架,相对于自带的,我更加推荐是用xUnit.ne ...
- 计算机组成原理--64位CPU装载32位操作系统,它的寻址能力还是4GB吗?
借由这个问题,今天我们就把 32 位 CPU.64 位 CPU.32 位操作系统.64 位操作系统之间的区别与联系彻底搞清楚.对于这个问题,博主也是一知半解了好长时间啊~ 基本概念 32位的CPU与6 ...
- [NOIP补坑计划]NOIP2012 题解&做题心得
场上预计得分:100+90+70+100+100+3060=490520(省一分数线245) 题解: D1T1 Vigenère 密码 题面 水题送温暖~~ #include<iostream& ...
- HDU-1257 最少拦截系统 贪心/DP 最长上升子序列的长度==最长不上升子序列的个数?
题目链接:https://cn.vjudge.net/problem/HDU-1257 题意 中文题咯中文题咯 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统.但是这种导弹拦截系统有一个缺陷:虽然 ...