基于Netty的四层和七层代理性能方面的一些压力测试
本文我们主要是想测试和研究几点:
- 基于Netty写的最简单的转发HTTP请求的程序,四层和七层性能的差异
- 三种代理线程模型性能的差异,下文会详细解释三种线程模型
- 池和非池化ByteBuffer性能的差异
本文测试使用的代码在:
https://github.com/JosephZhu1983/proxytest
在代码里我们实现了两套代理程序:
测试使用的机器配置是(阿里云ECS):
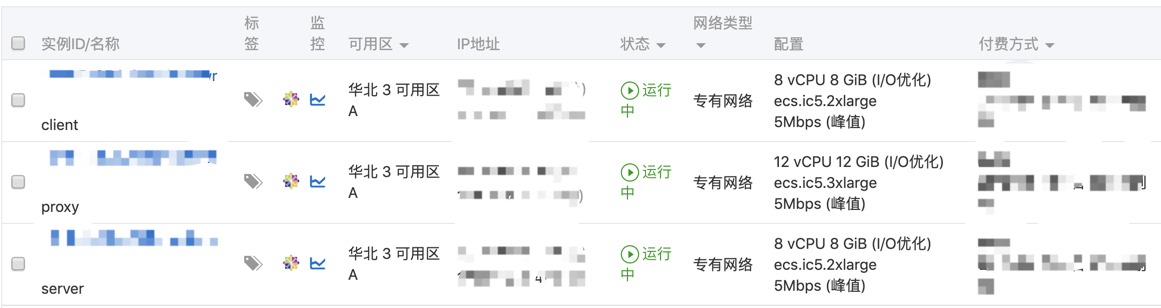
一共三台机器:
- server 服务器安装了nginx,作为后端
- client 服务器安装了wrk,作为压测客户端
- proxy 服务器安装了我们的测试代码(代理)
Nginx后端
nginx 配置的就是默认的测试页(删了点内容,减少内网带宽):
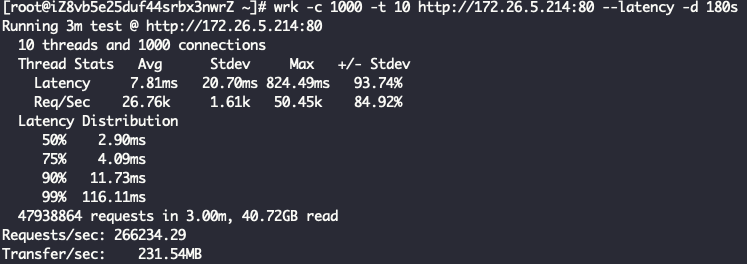
直接对着nginx压测下来的qps是26.6万:
有关四层和七层
四层的代理,我们仅仅是使用Netty来转发ByteBuf。
七层的代理,会有更多额外的开销,主要是Http请求的编码解码以及Http请求的聚合,服务端:
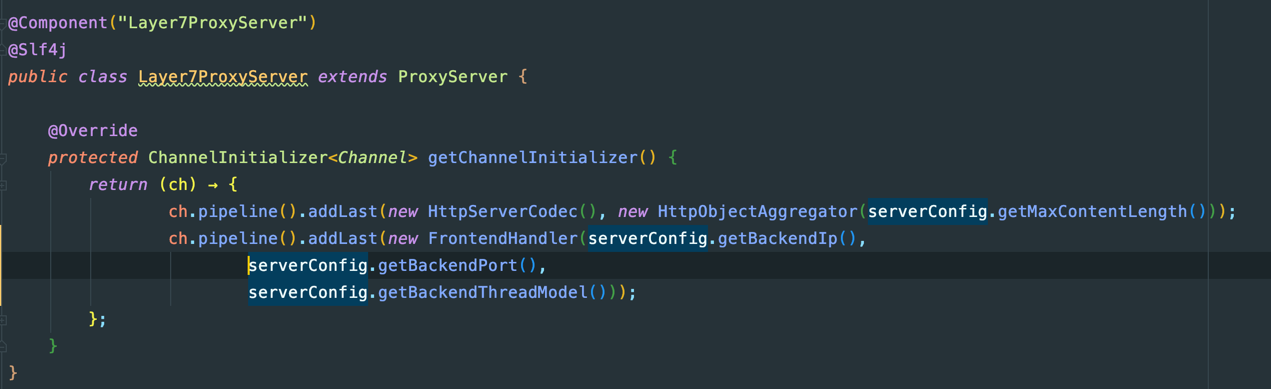
客户端:

这里我们可以想到,四层代理因为少了Http数据的编解码过程,性能肯定比七层好很多,好多少我们可以看看测试结果。
有关线程模型
我们知道作为一个代理,我们需要开启服务端从上游来获取请求,然后再作为客户端把请求转发到下游,从下游获取到响应后,返回给上游。我们的服务端和客户端都需要Worker线程来处理IO请求,有三种做法;
- A:客户端Bootstrap和服务端ServerBootstrap独立的线程池NioEventLoopGroup,简称IndividualGroup
- B:客户端和服务端共享一套线程池,简称ReuseServerGroup
- C:客户端直接复用服务端线程EventLoop,简称ReuseServerThread
以七层代理的代码为例:
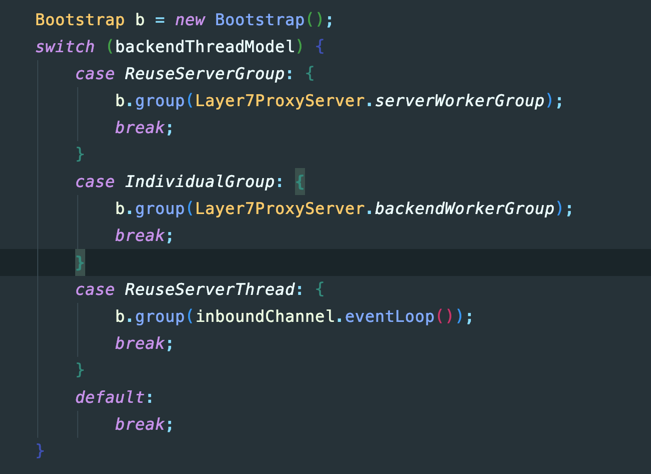
接下去的测试我们会来测试这三种线程模型,这里想当然的猜测是方案A的性能是最好的,因为独立了线程池不相互影响,我们接下去看看结果
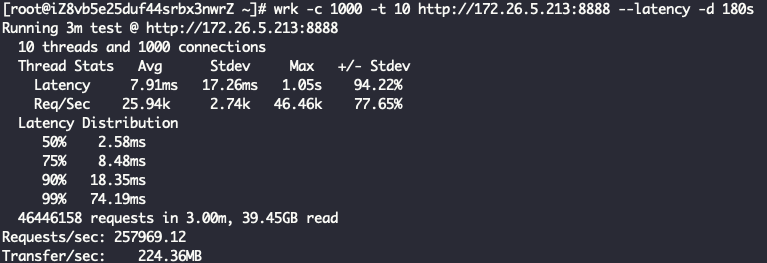
四层代理 + ReuseServerThread线程模型
Layer4ProxyServer Started with config: ServerConfig(type=Layer4ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
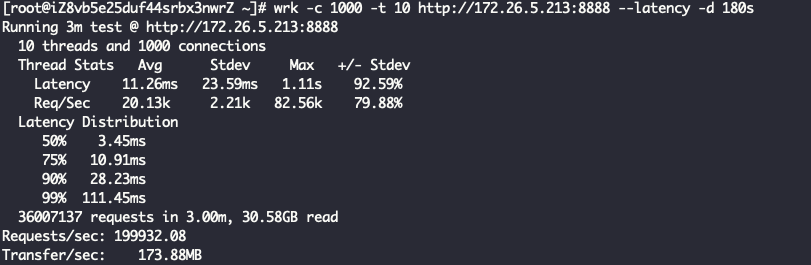
四层代理 + IndividualGroup线程模型
Layer4ProxyServer Started with config: ServerConfig(type=Layer4ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=IndividualGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
四层代理 + ReuseServerGroup线程模型
Layer4ProxyServer Started with config: ServerConfig(type=Layer4ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
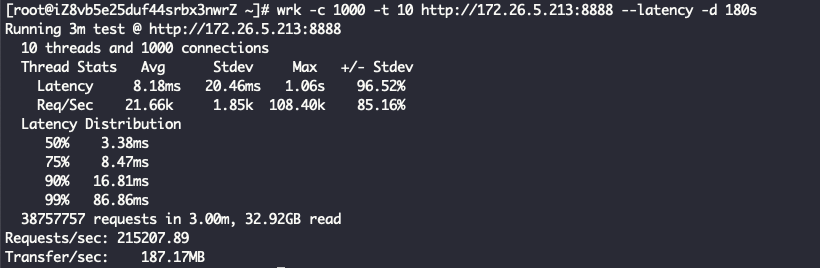
看到这里其实已经有结果了,ReuseServerThread性能是最好的,其次是ReuseServerGroup,最差是IndividualGroup,和我们猜的不一致。
四层系统监控图
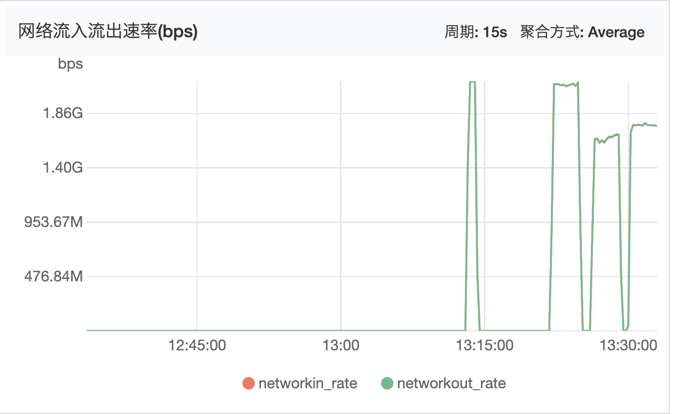
从网络带宽上可以看到,先测试的ReuseServerThread跑到了最大的带宽(后面三个高峰分别代表了三次测试):
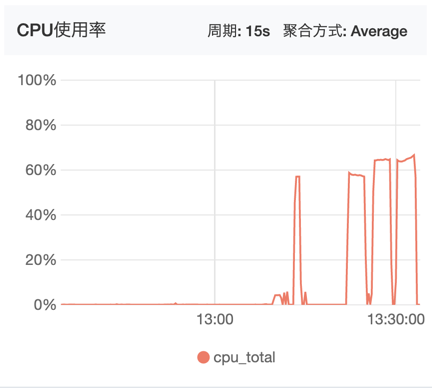
从CPU监控上可以看到,性能最好的ReuseServerThread使用了最少的CPU资源(后面三个高峰分别代表了三次测试):
七层代理 + ReuseServerThread线程模型
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
七层代理 + IndividualGroup线程模型
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=IndividualGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
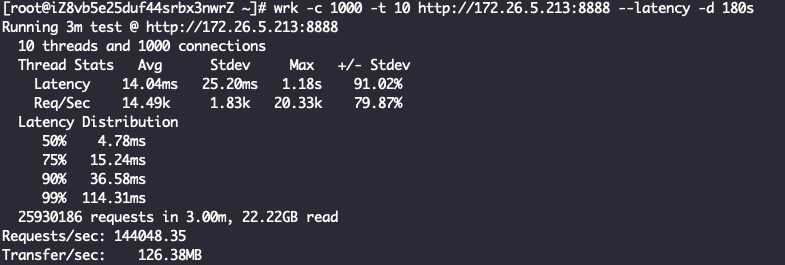
七层代理 + ReuseServerGroup线程模型
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerGroup, receiveBuffer=10240, sendBuffer=10240, allocatorType=Unpooled, maxContentLength=2000)
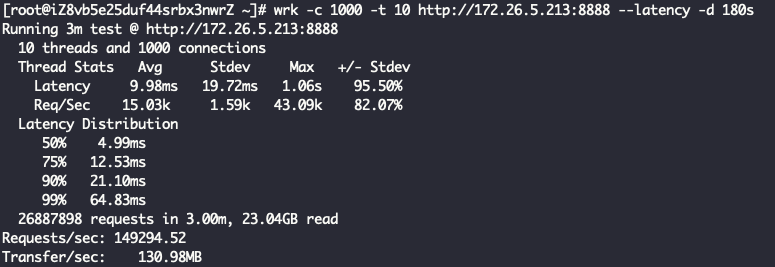
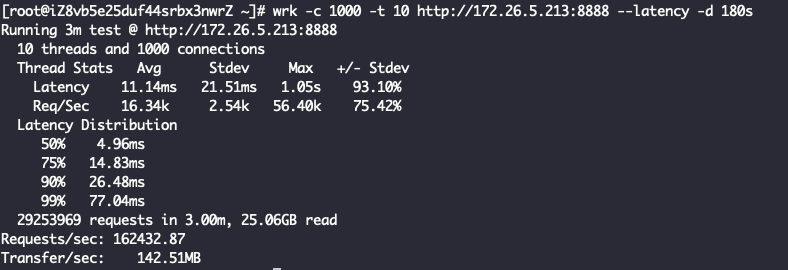
结论一样,ReuseServerThread性能是最好的,其次是ReuseServerGroup,最差是IndividualGroup。我觉得是这么一个道理:
- 复用IO线程的话,上下文切换会比较少,性能是最好的,后来我也通过pidstat观察验证了这个结论,但是当时忘记截图
- 复用线程池,客户端有机会能复用到服务端线程,避免部分上下文切换,性能中等
- 独立线程池,大量上下文切换(观察下来是复用IO线程的4x),性能最差
七层系统监控图
下面分别是网络带宽和CPU监控图:
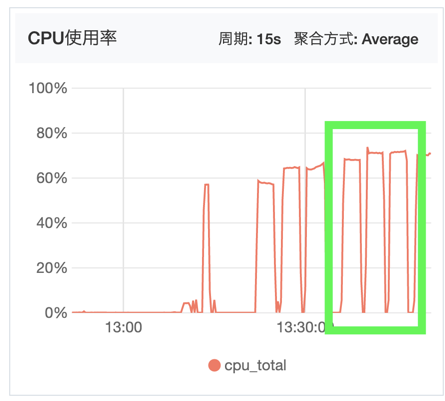
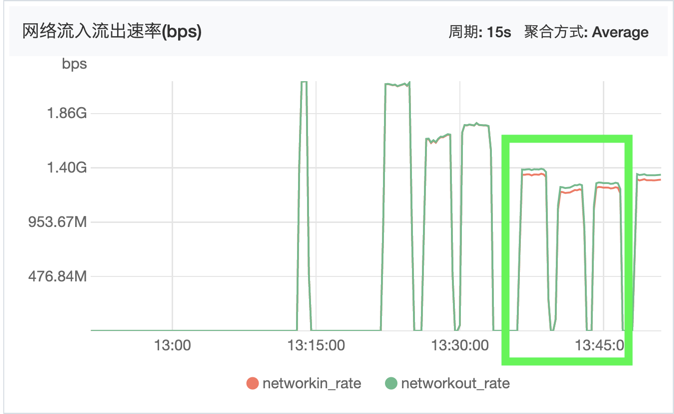
可以看到明显七层代理消耗更多的资源,但是带宽相比四层少了一些(QPS少了很多)。
出流量比入流量多一点,应该是代码里多加的请求头导致:
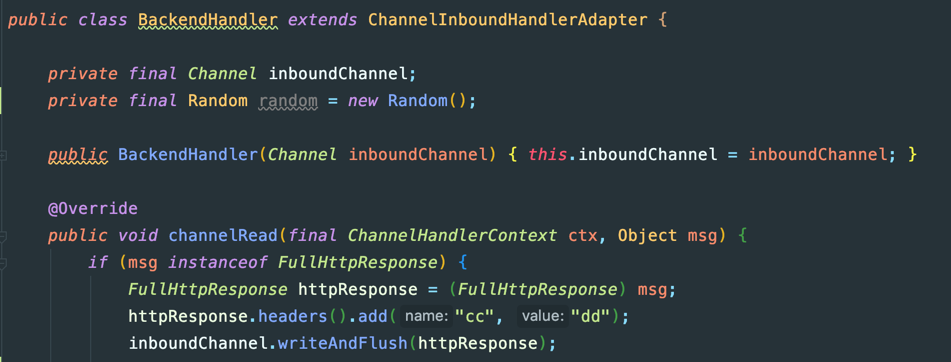
试试HttpObjectAggregator设置较大maxContentLength
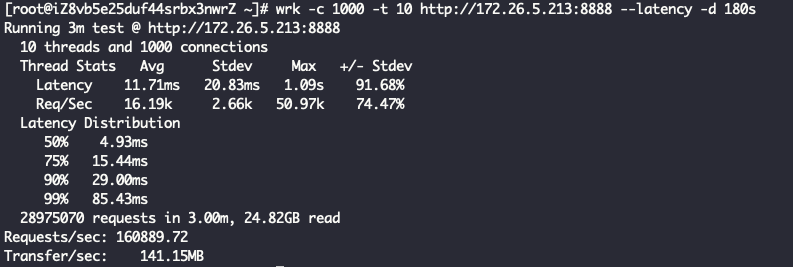
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Pooled, maxContentLength=100000000)
试试PooledByteBufAllocator
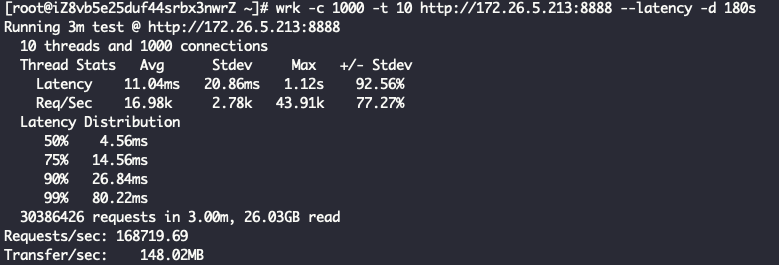
Layer7ProxyServer Started with config: ServerConfig(type=Layer7ProxyServer, serverIp=172.26.5.213, serverPort=8888, backendIp=172.26.5.214, backendPort=80, backendThreadModel=ReuseServerThread, receiveBuffer=10240, sendBuffer=10240, allocatorType=Pooled, maxContentLength=2000)
可以看到Netty 4.1中已经把默认的分配器设置为了PooledByteBufAllocator

总结
这里总结了一个表格,性能损失比例都以第一行直接压Nginx为参照:
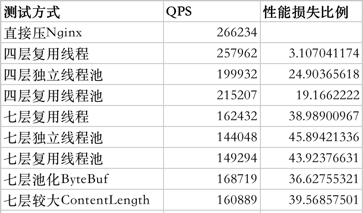
结论是:
- Nginx很牛,其实机器配置不算太好,在配置比较好的物理机服务器上跑的化,Nginx单机百万没问题
- Netty很牛,毕竟是Java的服务端,四层转发仅损失3% QPS
- 不管是七层还是四层,复用线程的方式明显性能最好,占用CPU最少
- 因为上下文切换的原因,使用Netty开发网络代理应该复用IO线程
- 七层的消耗比四层大很多,即使是Netty也避免不了,这是HTTP协议的问题
- PooledByteBufAllocator性能比UnpooledByteBufAllocator有一定提升(接近3%)
- HttpObjectAggregator如果设置较大的最大内容长度,会略微影响点性能
基于Netty的四层和七层代理性能方面的一些压力测试的更多相关文章
- Nginx的四层和七层代理
理论部分: 所谓四层负载均衡,也就是主要通过报文中的目标地址和端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器,它一般走的是tcp,udp协议 所谓七层负载均衡,也称为“内 ...
- linux负载均衡总结性说明(四层负载/七层负载)
在常规运维工作中,经常会运用到负载均衡服务.负载均衡分为四层负载和七层负载,那么这两者之间有什么不同?废话不多说,详解如下: 一,什么是负载均衡1)负载均衡(Load Balance)建立在现有网络结 ...
- 老斜两宗事-七层代理模式还是IP层VPN
1.七层代理模式还是IP层VPN 非常多人会问,我究竟是使用代理模式呢,还是使用VPN模式,假设我想数据在中间不安全的链路上实现加密保护的话.这个问题有一个背景.那就是,你想保护你的数据,能够使用VP ...
- 四层和七层负载均衡的特点及常用负载均衡Nginx、Haproxy、LVS对比
一.四层与七层负载均衡在原理上的区别 图示: 四层负载均衡与七层负载均衡在工作原理上的简单区别如下图: 概述: 1.四层负载均衡工作在OSI模型中的四层,即传输层.四层负载均衡只能根据报文中目标地址和 ...
- Web负载均衡学习笔记之四层和七层负载均衡的区别
0x00 简介 简单理解四层和七层负载均衡: ① 所谓四层就是基于IP+端口的负载均衡:七层就是基于URL等应用层信息的负载均衡:同理,还有基于MAC地址的二层负载均衡和基于IP地址的三层负载均衡. ...
- 四层and七层负载均衡
四层负载/七层负载 在常规运维工作中,经常会运用到负载均衡服务.负载均衡分为四层负载和七层负载,那么这两者之间有什么不同? 废话不多说,详解如下: 1. 什么是负载均衡 1)负载均衡(Load ...
- kubernetes系列(十) - 通过Ingress实现七层代理
1. Ingress入门 1.1 Ingress简介 1.2 原理和组成部分 1.3 资料信息 2. Ingress部署的几种方式 2.1 前言 2.1 Deployment+LoadBalancer ...
- 搭建Nginx七层反向代理
基于https://www.cnblogs.com/Dfengshuo/p/11911406.html这个基础上,在来补充下七层代理的配置方式.简单理解下四层和七层协议负载的区别吧,四层是网络层,负载 ...
- 四层LB和七层LB
总结: 基于MAC地址玩的是二层(虚拟MAC地址接收请求,然后再分配到真实的MAC地址), 基于IP地址玩的是三层(虚拟IP地址接收请求,然后再分配到真实的IP地址), 基于IP地 ...
随机推荐
- wxWidgets谁刚开始学习指南(5)——使用wxSmith可视化设计
wxWidgets谁刚开始学习的整个文件夹指南 PDF版及附件下载 1 前言2 下载.安装wxWidgets3 wxWidgets应用程序初体验4 wxWidgets学习资料及利用方法指导5 用w ...
- 仿照Android的池化技术
/** * 仿照Android池化技术 * @author fgtian * */ public class ObjectCacheTest { public static class ObjectI ...
- 道量化交易程序猿(25)--Cointrader之MarketData市场数据实体(12)
转载注明出处:http://blog.csdn.net/minimicall.http://cloudtrade.top/ 前面一节我们说到了远端事件.当中.市场数据就属于远端事件.市场数据有什么?我 ...
- 学习 NLP(一)—— TF-IDF
TF-IDF(Term Frequency & Inverse Document Frequency),是一种用于信息检索与数据挖掘的常用加权技术.它的主要思想是:如果某个词或短语在一篇文章中 ...
- Android 项目编译过程
Android 工程构建的持续集成,需要搭建一套编译和打包自动化流程,比如建立每日构建系统.自动生成发布文件等等.这些都需要我们对Android工程的编译和打包有一个比较深入的理解,例如知道它的每一步 ...
- 采用Fiddler建立Asp.net webapi与Android/IOS调试环境
最近,他们正在做Android+Asp.net WebApi练习,通过发现visual studio debug模式启动Asp.net之后,无法响应Android寄过来http求,设置一个很好的休息不 ...
- WPF 3D中多个模型如何设置某一个在最前?
原文:WPF 3D中多个模型如何设置某一个在最前? 问题:我们的模型包括导入的3D solid模型和axis坐标轴模型,当模型旋转的时候,3D会将axis挡住. 期望:axis一直在最前面,不会被3D ...
- 简单推导 PCA
考虑二维数据降低到一维的例子,如下图所示: 最小化投影方差(maximize projected variance): 1N∑n=1N(uuT1xn−uuT1x¯)=uuT1Suu1,s.t.uuT1 ...
- uwp 沉浸式状态栏
//隐藏状态栏if (ApiInformation.IsTypePresent(typeof(StatusBar).ToString())) { StatusBar statusBar = Statu ...
- 使用HANDLE_MSG宏简化Win32应用的开发
http://blog.csdn.net/daiyutage/article/details/17241161 Win32应用中的回调函数WndProc用于接收Windows向应用程序直接发送的消息, ...