Node笔记(2)
写一个可以生成多层级文件夹的函数
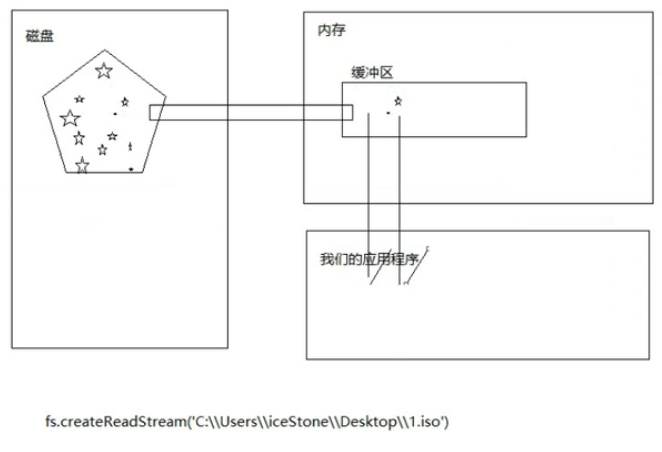
//缓冲区存的就是一个字节数组
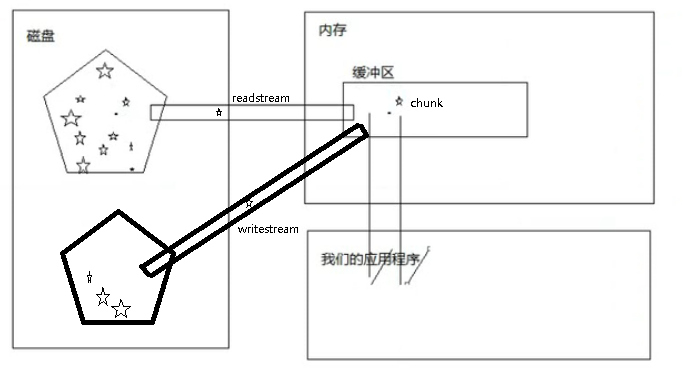
文件流的方式操作只读流
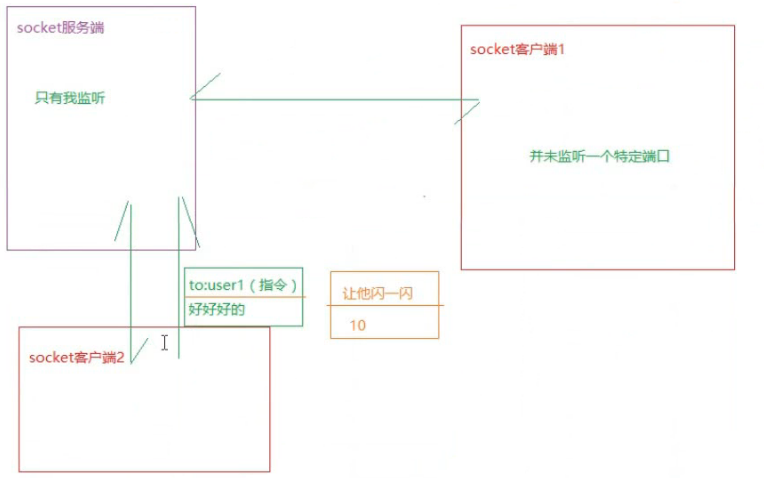
Socket(传输层)

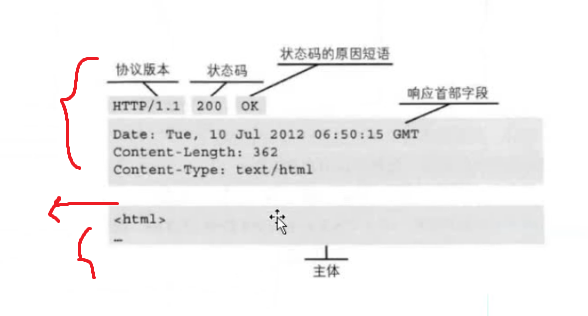
响应报文:
Node笔记(2)的更多相关文章
- node笔记——gulp修改静态文件的名字
cmd小技巧: 1.换到下级或同等级目录 D: 2.换到上级目录 cd.. node 包管理器小技巧[以gulp为例] npm install --save-dev gulp gulp-concat ...
- Node笔记五-进程、线程
进程 -每一个正在运行的应用程序都称之为进程 -每一个应用程序都至少有一个进程 -进程是用来给应用程序提供一个运行的环境 -进程是操作系统为应用程序分配资源的一个单位线程 -用来执行应用程序中的代码 ...
- Node笔记四
异步操作 -Node采用chrome v8 引擎处理javascript脚本 --v8最大特点就是单线程运行,一次只能运行一个任务 -Node大量采用异步操作 --任务不是马上执行,而是插在任务队列的 ...
- Node笔记三
global --类似与客户端javascript运行环境中的window process --用于获取当前node进程信息,一般用于获取环境变量之类的信息 console --node中内置的con ...
- Node笔记二
### 安装包的方式安装 - 安装包下载链接: + Mac OSX: [darwin](http://npm.taobao.org/mirrors/node/v5.7.0/node-v5.7.0.pk ...
- Node笔记一
什么是javascript? --脚本语言 --运行在浏览器中 --一般用来做客户端页面的交互 javascript运行环境 --运行在浏览器内核中的JS引擎 浏览器这种javascript可以做什么 ...
- node笔记
基础入门可参考: <一起学 Node.js>—— https://github.com/nswbmw/N-blog 核心模块使用前需要引入 let fs=require('fs'); ...
- node笔记汇总
项目依赖分两种,一个就是普通的项目依赖比如bootstrap,还用一种只是开发阶段需要用的,这种属于开发依赖比如gulp,开发依赖最终记录在devDependencies节点里面 - ...
- Node笔记(1)
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境. 进程 1.process.argv 用于获取当前进程信息 0--node.exe的目录1--js文件的目录2 ...
- Node笔记 - process.cwd() 和 __dirname 的区别
process.cwd() 返回工作目录 __dirname 返回脚本所在的目录位置 单看概念觉得都差不多,有种似懂非懂的感觉,那么接下用一个简单易懂的例子来理解下这两者的区别,在此之前先看一个方法 ...
随机推荐
- PHP tools for Visual Studio 2013 安装、破解、配置教程
安装 首先,必须要安装vs2013.本人安装的是社区版,免费的同时功能又全面. 然后,去http://download.csdn.net/detail/liangzehong007/9076855 或 ...
- oracle BBED 直接改动数据库block块
1.BBED配置 1)将相应文件放到$ORACLE_HOME/rdbms/mesg和$ORACLE_HOME/rdbms/lib中: --将lib中bbedus.msb和bbedus.msg ...
- POJ 2007
直接求凸包,输出即可. #include <iostream> #include <cstdio> #include <cstring> #include < ...
- OpenStack开发基础-oslo.config
The cfg Module cfg Module来自于OpenStack中的重要的基础组件oslo.config,通过cfg Module能够用来通过命令行或者是配置文件来配置一些options,对 ...
- 【solr基础教程之中的一个】Solr相关知识点串讲
Solr是Apache Lucene的一个子项目.Lucene为全文搜索功能提供了完备的API.但它仅仅作为一个API库存在.而不能直接用于搜索. 因此,Solr基于Lucene构建了一 ...
- Android訪问网络,使用HttpURLConnection还是HttpClient?
原文地址:http://android-developers.blogspot.com/2011/09/androids-http-clients.html 大多数的Android应用程序都会使用HT ...
- Palindrome Linked List 234
推断是否为回文链栈 时间复杂度为O(n) 空间复杂度为O(1) : 运用递归 保证空间复杂度为O(1): 时间复杂度为O(n): 注意定义了一个全局变量 flag = true 用此标记来标记是否在推 ...
- ffmpeg实现
最近做一个小项目,要在线播放录制的 MP4 视频,想开源的 flash player 或 html 5 可以播放.可,虽然 MP4 是 H.264 编码,但就是播放不了.可能是封装方式(PS 方式)不 ...
- Nginx实现负载均衡 + Keepalived实现Nginx的高可用
前言 使用集群是大中型网站解决高并发.海量数据问题的常用手段.当一台服务器的处理能力.存储空间不足时,不要企图去换更强大的服务器,对大型网站而言,不管多么强大的服务器,都满足不了网站持续增长的业务需求 ...
- Codeforces Round #198 (Div. 2)C,D题解
接着是C,D的题解 C. Tourist Problem Iahub is a big fan of tourists. He wants to become a tourist himself, s ...