linux标准IO缓冲(apue)
为什么需要标准IO缓冲?
LINUX用缓冲的地方遍地可见,不管是硬件、内核还是应用程序,内核里有页高速缓冲,内存高速缓冲,硬件更不用说的L1,L2 cache,应用程序更是多的数不清,基本写的好的软件都有。但归根结底这些缓冲的作用是相同的,都是为了提高机器或者程序的性能。而需要缓冲大部分的情况都是为了协调两个设备或者两个系统间速度的不匹配。
大家都知道IO设备的访问速度与CPU的速度相差好几个数量级,所以为了协调IO设备与CPU的速度的不匹配,对于块设备内核使用了页高速缓存。也就是说,数据会先被拷贝到操作系统内核的页缓存区中,然后才会从操作系统内核的缓存区拷贝到应用程序的地址空间。
当应用程序尝试读取某块数据的时候,如果这块数据已经存放在页缓存中,那么这块数据就可以立即返回给应用程序,而不需要经过实际的物理读盘操作。当然,如果数据在应用程序读取之前并未被存放在页缓存中,那么就需要先将数据从磁盘读到页缓存中去。对于写操作来说,应用程序也会将数据先写到页缓存中去,数据是否被立即写到磁盘上去取决于应用程序所采用的写操作机制:如果用户采用的是同步写机制,那么数据会立即被写回到磁盘上,应用程序会一直等到数据被写完为止;如果用户采用的是延迟写机制,那么应用程序就完全不需要等到数据全部被 写回到磁盘,数据只要被写到页缓存中去就可以了。在延迟写机制的情况下,操作系统会定期地将放在页缓存中的数据刷到磁盘上。与异步写机制不同的是,延迟写机制在数据完全写到磁盘上得时候不会通知应用程序,而异步写机制在数据完全写到磁盘上得时候是会返回给应用程序的。所以延迟写机制本省是存在数据丢失的风险的,而异步写机制则不会有这方面的担心。
在应用程序中,我们经常也使用缓存来解决IO设备与CPU速度的不匹配,如下面的read和write函数:
1 ssize_t read(int filedes, void *buf, size_t nbytes);
2 ssize_t write(int filedes, const void *buf, size_t nbytes);
我们调用read函数从文件读取数据或者调用write来写数据到文件中,一般都是一次性的写多个数据,很少一次写一个byte的数据(除了一些特殊的场景)。所以上面传递给read和write的buf参数其实就是我们的缓冲,这个缓冲的大小都是我们在写程序的时候自己定义的。但问题就来了,我们应该定义多大的缓冲大小才能使IO性能达到最大呢?对于一些不了解内核或者文件系统的人来说是很难知道这个大小的,下面是apue作者自己测试的不同缓冲大小对IO性能的影响的数据:
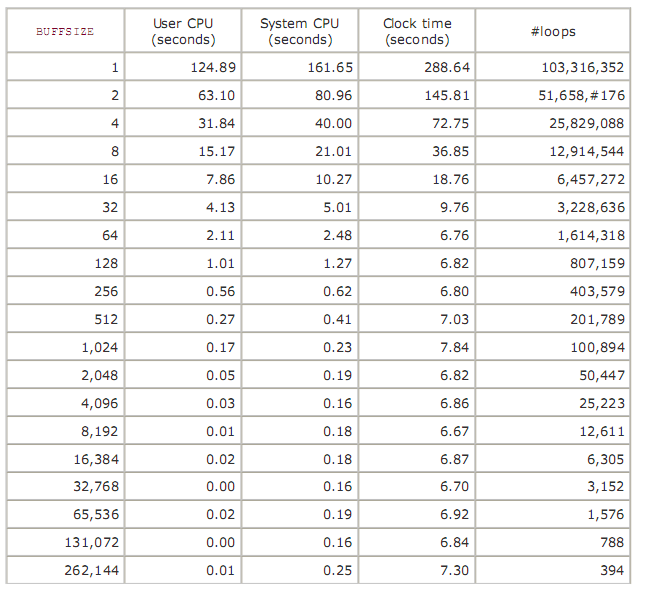
从上图可以知道当缓冲达到4096大小的时候,继续增加缓冲大小对IO性能影响不大。这个4096大小由文件系统的块大小决定,由于上面的测试所用的文件系统是Linux ext2,块大小是4096。
标准IO库则很好的解决了设置缓冲大小的问题,标准IO会选择最佳的缓存大小,使得我们不用再关心设置缓存大小的问题,事实上标准IO库会对每个IO流自动进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的麻烦。不过使用标准IO库最大的问题也是它的缓冲,使用的不好很容易出现莫名其妙的结果。
标准IO提供的三种类型的缓冲
全缓冲
在填满标准IO缓冲区后才进行实际的IO操作。对于在磁盘上的文件通常由标准IO库实施全缓冲的。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用malloc获得需使用的缓存区。
行缓冲
当在输入和输出中遇到换行符时,标准IO库执行IO操作。这允许我们一次输出一个字符(用标准IO函数fputc),但只有在写了一行之后才进行实际IO操作。通常涉及到终端(例如标准输入和标准输出)使用的是行缓冲。
对于行缓冲有两个限制。第一,因为标准IO库用来收集每一行的缓冲区的长度是固定的,所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行IO操作。第二,任何时候只要通过标准IO库要求从(a)一个不带缓存的流,或者(b)一个行缓存的流(它要求从内核得到数据)得到输入数据,那么就会造成冲洗所有行缓冲输出流(因为后面读取的数据可能就是前面输出的数据)。其实第二种情况我们会经常遇到,当我们先调用printf输出一串不带换行符的字符时,执行完这条printf语句并不会立刻在屏幕中显示我们输出的数据,当我们接下来调用scanf从标准输入读取数据时,我们才看到前面输出的数据。
不带缓冲
标准IO库不对字符进行存储。例如,如果用标准IO函数fputs写15个字符到不带缓冲的流中,则该函数很可能直接调用write系统调用将这些字符立即写到相关的文件中。标准出错流stderr是不带缓冲的,这样为了让出错的信息可以尽快的显示出来。
修改默认IO缓冲
对于上面提到的每种文件流,IO库都默认分配一个对应的缓冲给它,但有时候我们想自己设置这些缓冲,不要默认的,那么我们可以使用下面两个函数来达到目的:
1 void setbuf(FILE *restrict fp, char *restrict buf);
2 void setvbuf(FILE *restrict fp, char *restrict buf, int mode, size_t size);
第一个函数用来打开或者关闭缓冲机制,如果buf为NULL,则关闭缓冲,否则buf指向缓冲区,不过缓冲区的类型和文件流有关。第二个函数可以精确的指定我们所需要的缓冲类型,如下图所示。

获取标准IO默认缓冲大小
下面我们编写一个小的程序来获得标准IO默认缓冲的大小,代码如下:
#include <stdio.h> int stream_attribute(FILE *fp)
{
if(fp->_flags & _IO_UNBUFFERED)
{
printf("The IO type is unbuffered\n");
}else if(fp->_flags & _IO_LINE_BUF){
printf("The IO type is line buf\n");
}else{
printf("The IO type is full buf\n");
}
printf("The IO size : %d\n",fp->_IO_buf_end - fp->_IO_buf_base);
return ;
}
int main()
{
FILE *fp;
stream_attribute(stdin);
printf("___________________________________\n\n");
stream_attribute(stdout);
printf("___________________________________\n\n");
stream_attribute(stderr);
printf("___________________________________\n\n");
if((fp = fopen("test","w+")) == NULL)
perror("fail to fopen");
stream_attribute(fp);
return ;
}
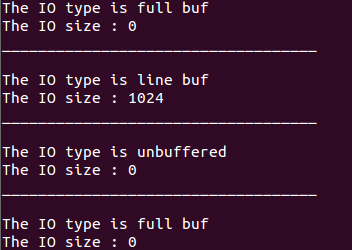
在ubuntu下运行结果为:
下面修改下代码,从键盘读入一串字符并写入到test文件中,代码如下:
#include <stdio.h> int stream_attribute(FILE *fp)
{
if(fp->_flags & _IO_UNBUFFERED)
{
printf("The IO type is unbuffered\n");
}else if(fp->_flags & _IO_LINE_BUF){
printf("The IO type is line buf\n");
}else{
printf("The IO type is full buf\n");
}
printf("The IO size : %d\n",fp->_IO_buf_end - fp->_IO_buf_base);
return ;
}
int main()
{
FILE *fp;
char buf[]; printf("input a string(<20):");
scanf("%s", buf);
stream_attribute(stdin);
printf("___________________________________\n\n");
stream_attribute(stdout);
fprintf(stderr, "___________________________________\n\n");
stream_attribute(stderr);
printf("___________________________________\n\n");
if((fp = fopen("test.txt","w+")) == NULL)
perror("fail to fopen");
fputs(buf, fp);
stream_attribute(fp);
return ;
}
运行结果如下:
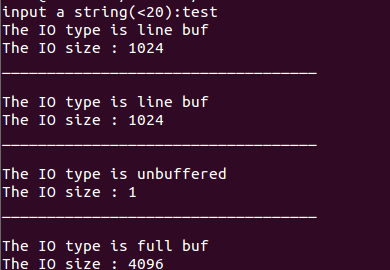
从上面的运行结果可以看出标准IO库对流的缓冲不是在一开始就分配的,只有对流进行了输入或者输出才会实际的分配。在linux下,行缓冲的默认大小是1K,全缓冲的大小默认是4K,无缓冲的默认大小是1字节。
参考
《APUE》
http://blog.chinaunix.net/uid-26833883-id-3198114.html
linux标准IO缓冲(apue)的更多相关文章
- 为什么需要标准IO缓冲?
(转)标准I/O缓冲:全缓冲.行缓冲.无缓冲 标准I/O库提供缓冲的目的是尽可能地减少使用read和write调用的次数.它也对每个I/O流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点所带来的 ...
- linux标准io的copy
---恢复内容开始--- 1.linux标准io的copy #include<stdio.h> int main(int argc,char **argv) { if(argc<3) ...
- Linux标准IO和管道
Linux标准IO和管道 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.标准输入和输出 程序:指令+数据 读入数据:Input 输出数据:Output 打开的文件都有一个fd: ...
- [Linux]标准IO全缓冲和行缓冲
概述 标准IO中,标准错误是不带缓冲的.若是指向终端设备的流才是行缓冲的,否则是全缓冲的. 行缓冲也可以分配缓冲区,当遇到超大行(超过缓冲区的行),缓冲区内容也会优先刷出. 示例 #include & ...
- 1.Linux标准IO编程
1.1Linux系统调用和用户编程接口 1.1.1系统调用 用户程序向操作系统提出请求的接口.不同的系统提供的系统调用接口各不相同. 继承UNIX系统调用中最基本和最有用的部分. 调用按照功能分:进程 ...
- Linux 标准IO库介绍
1.标准IO和文件IO有什么区别? (1).看起来使用时都是函数,但是:标准IO是C库函数,而文件IO是Linux系统的API. (2).C语言库函数是由API封装而来的.库函数内部也是通过调用API ...
- linux 标准io笔记
三种缓冲 1.全缓冲:在缓冲区写满时输出到指定的输出端. 比如对磁盘上的文件进行读写通常是全缓冲的. 2.行缓冲:在遇到'\n'时输出到指定的输出端. 比如标准输入和标准输出就是行缓冲, 回车后就会进 ...
- 标准IO缓冲机制
参考资料: https://q16964777.iteye.com/blog/2228244 知道缓冲有几种模式:无缓冲.行缓冲.全缓冲.通过判断FILTE中的 _flags 的判断可以知道究竟是那种 ...
- (一) 一起学 Unix 环境高级编程 (APUE) 之 标准IO
. . . . . 目录 (一) 一起学 Unix 环境高级编程 (APUE) 之 标准IO (二) 一起学 Unix 环境高级编程 (APUE) 之 文件 IO (三) 一起学 Unix 环境高级编 ...
随机推荐
- Master-Slave通用基础框架
一.设计目的 设计出一个通用的Master-Slave基础框架,然后可以基于这个框架来实现特定的业务需求,比如实现多节点并行计算.分布式处理等. 二.设计理念 基于经典的命令模式,Master和Sla ...
- HTML元素基础学习
HTML元素 HTML文档是由HTML元素定义的.HTML元素是指从start tag(opening tag)到end tag(closing tag)的所有代码,即start tag + cont ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- 有状态Bean和无状态Bean的定义
有状态会话bean :每个用户有自己特有的一个实例,在用户的生存期内,bean保持了用户的信息,即“有状态”:一旦用户灭亡(调用结束或实例结束),bean的生命期也告结束.即每个用户最初都会得到一个初 ...
- Android之Json的学习
json数据包含json对象,json数组,对象是{ },数组是[ ], 数组里面还可以包含json对象,json对象之间是用逗号(,)隔开 形式如下: { "languages" ...
- 一些linux包相关命令
针对centos 查看CentOS版本方法: lsb_release -a #result------------ LSB Version: :base-4.0-amd64:base-4.0-noar ...
- 使div下的图片自适应div的大小
div img{ max-width:100%; height:auto; } 这里div 要给固定的宽度 开始这里还想了半天 用网上的方法也不行 问老大 又一句话就给我解决了...老大真男神啊!!! ...
- Android-Parcelable
Parcelable和Serializable的区别: android自定义对象可序列化有两个选择一个是Serializable和Parcelable 一.对象为什么需要序列化 1.永久 ...
- .NET Fringe 定义未来
在dotnetconf 2015会宣布了4.12-14 在波特兰召开 .NET Fringe http://dotnetfringe.org/ ,中文社区很少有相关的介绍,本文向大家介绍下这个.NET ...
- 剑指Offer面试题:25.二叉搜索树与双向链表
一.题目:二叉搜索树与双向链表 题目:输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表.要求不能创建任何新的结点,只能调整树中结点指针的指向.比如输入下图中左边的二叉搜索树,则输出转换之后的 ...