Convolutional Neural Networks for Visual Recognition 3
Gradient Computing
前面我们介绍过分类器模型一般包含两大部分,一部分是score function,将输入的原始数据映射到每一类的score,另外一个重要组成部分是loss function,计算预测值
与实际值之间的误差,具体地,给定一个线性分类函数:f(xi;W)=Wxi,我们定义如下的loss function:
我们看到L与参数W有关,所以我们需要找到一个合适的W使得L尽可能小,这个过程称为优化。所以一个完整的分类模型,包括三个核心部分:score function,loss function 以及optimization(优化)。
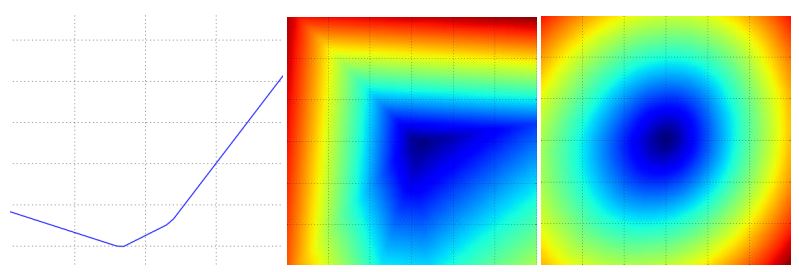
一般来说,我们定义的loss function中,里面涉及的输入变量都是高维的向量,要让它们直接可视化是不可能的,我们可以通过低维的情况下得到一些直观的印象,让loss在直线或者平面上变化,比如
我们可以先初始化一个权值矩阵W,然后让该矩阵沿着方向W1变化,那么可以评估W1不同的幅值对loss的影响,即L(W+aW1),这个loss会随着不同的a生成
一条曲线,同样,我们可以让L在两个方向W1,W2变化,L(W+aW1)+bW2不同的a,b会生成不同的loss,这个loss会形成一个平面,如下图所示:
我们可以通过从数学的角度解释这个loss function,考虑只有一个样本的情况,我们有:
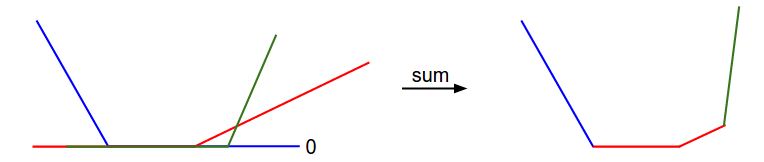
从这个表达式可以看出,样本的loss是W的一个线性函数,如果我们考虑一个含有三个样本(每个样本是一个一维的点)的训练集,这个训练集有三个类别,那么训练集
的loss可以表示为:
因为样本xi是一维的,所以系数wi也是一维的,它们的和L与与W的关系可以由下图表示:
上图给出的是一维的情况,如果是高维的话,这个要复杂的多,我们希望找到一个W使得该loss最小,上图是一个凸函数,对于这类函数的优化,是一大类属于凸优化的
问题,但是我们后面介绍的神经网络,其loss function是比这更复杂的一类函数,不是单纯地凸函数。上面的图形告诉我们这个loss function不是处处可导的,但是我们
可以利用函数subgradient(局部可导)的性质,来优化这个函数。
W的搜寻是属于一个优化问题,由于我们后面介绍的神经网络的loss function并不是凸函数,虽然我们现在看到的SVM loss function是一个凸函数,但是我们并不打算
直接用凸优化的相关方法来找这个W,我们要介绍一种在后面的神经网络也能用到的优化技术来优化这个SVM loss function。
方案一:随机搜索
最简单,但是最糟糕的方案就是随机搜索,我们对W赋予一系列的随机值,然后看哪个随机值对应的loss最低,这样肯定是耗时而且低效的。
方案二:随机局部搜索
在随机搜索的基础上,加上一个局部搜索,即W+σW,我们会判断这个更新是有助于loss减小还是增大,如果是减小,那么我们就更新,反之就不更新,而继续做
局部搜索。
方案三:梯度下降
最简洁高效的算法就是梯度下降法,这种方法也是神经网络优化方法中用的最多的一种方法。
一般来说,我们会Back-propagation去计算loss function对W的偏导数, 这是利用链式法则(chain-rule)来计算梯度的一种方式.
声明:lecture notes里的图片都来源于该课程的网站,只能用于学习,请勿作其它用途,如需转载,请说明该课程为引用来源。课程网站: http://cs231n.stanford.edu/
Convolutional Neural Networks for Visual Recognition 3的更多相关文章
- Convolutional Neural Networks for Visual Recognition 1
Introduction 这是斯坦福计算机视觉大牛李菲菲最新开设的一门关于deep learning在计算机视觉领域的相关应用的课程.这个课程重点介绍了deep learning里的一种比较流行的模型 ...
- Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/ 里面有很多相当好的文章 http://cs231n.github.io/convolutional-networks/ Table of Cont ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- Convolutional Neural Networks for Visual Recognition 8
Convolutional Neural Networks (CNNs / ConvNets) 前面做了如此漫长的铺垫,现在终于来到了课程的重点.Convolutional Neural Networ ...
- Convolutional Neural Networks for Visual Recognition 5
Setting up the data and the model 前面我们介绍了一个神经元的模型,通过一个激励函数将高维的输入域权值的点积转化为一个单一的输出,而神经网络就是将神经元排列到每一层,形 ...
- Convolutional Neural Networks for Visual Recognition 2
Linear Classification 在上一讲里,我们介绍了图像分类问题以及一个简单的分类模型K-NN模型,我们已经知道K-NN的模型有几个严重的缺陷,第一就是要保存训练集里的所有样本,这个比较 ...
- Convolutional Neural Networks for Visual Recognition 7
Two Simple Examples softmax classifier 后,我们介绍两个简单的例子,一个是线性分类器,一个是神经网络.由于网上的讲义给出的都是代码,我们这里用公式来进行推导.首先 ...
- Convolutional Neural Networks for Visual Recognition 4
Modeling one neuron 下面我们开始介绍神经网络,我们先从最简单的一个神经元的情况开始,一个简单的神经元包括输入,激励函数以及输出.如下图所示: 一个神经元类似一个线性分类器,如果激励 ...
- cs231n spring 2017 lecture1 Introduction to Convolutional Neural Networks for Visual Recognition 听课笔记
1. 生物学家做实验发现脑皮层对简单的结构比如角.边有反应,而通过复杂的神经元传递,这些简单的结构最终帮助生物体有了更复杂的视觉系统.1970年David Marr提出的视觉处理流程遵循这样的原则,拿 ...
- Stanford CS231n - Convolutional Neural Networks for Visual Recognition
网易云课堂上有汉化的视频:http://study.163.com/course/courseLearn.htm?courseId=1003223001#/learn/video?lessonId=1 ...
随机推荐
- django模板加载静态资源
1. 目录结构 /mysite/setting.py部分配置: # Django settings for mysite project. import os.path TEMPLATE_DIRS = ...
- 基于Linux整形时间的常用计算思路
上一次分享了Linux时间时区详解与常用时间函数,相信大家对Linux常见时间函数的使用也有了一定的了解,在工作中遇到类似获取时间等需求的时候也一定能很好的处理.本文基于Linux整形时间给出一些简化 ...
- 用javascript简单写的判断电话号码
在很多网站注册的时候,需要我们填写电话号码,本来想糊弄一下,但是还不行,一直提示不正确,我去网上搜了很多,正则表达式,发现有很多不对的, 最后写了一个简单的,但是比较实用的 首先是html部分的内容 ...
- web.xml配置中的log4jRefreshInterval
采用spring框架的项目如何使用log4j在spring中使用log4j,有些方便的地方, 1.动态的改变记录级别和策略,即修改log4j.properties,不需要重启web应用,这需要在web ...
- Java语言实现简单FTP软件------>源码放送(十三)
Java语言实现简单FTP软件------>FTP协议分析(一) Java语言实现简单FTP软件------>FTP软件效果图预览之下载功能(二) Java语言实现简单FTP软件----- ...
- delete 和 truncate 的 区别
如果要清空表中的所有记录,可以使用下面的两种方法: DELETE FROM table1 TRUNCATE TABLE table1 以下 为之区别: 1)执行速度和灵活性 trunca ...
- 读:Instance-aware Image and Sentence Matching with Selective Multimodal LSTM
摘要:有效图像和句子匹配取决于如何很好地度量其全局视觉 - 语义相似度.基于观察到这样的全局相似性是由图像(对象)和句子(词)的成对实例之间的多个局部相似性的复合聚集,我们提出了一个实例感知图像和句子 ...
- iOS JSON 和 Mode l转换
MJExtension 是我们项目开发常用的一个第三方框架 很好用. https://github.com/CoderMJLee/MJExtension 映射 json value key 直 ...
- [原创]java WEB学习笔记39:EL中的运算符号(算术运算符,关系运算符,逻辑运算符,empty运算符,条件运算符,括号运算符)
本博客为原创:综合 尚硅谷(http://www.atguigu.com)的系统教程(深表感谢)和 网络上的现有资源(博客,文档,图书等),资源的出处我会标明 本博客的目的:①总结自己的学习过程,相当 ...
- Android蓝牙开发浅析【转】
本文转载自:http://blog.csdn.net/geekdonie/article/details/7487761 由于近期正在开发一个通过蓝牙进行数据传递的模块,在参考了有关资料,并详细阅读了 ...