CUDA memory
CUDA存储器类型:
每个线程拥有自己的register and loacal memory;
每个线程块拥有一块shared memory;
所有线程都可以访问global memory;
还有,可以被所有线程访问的只读存储器:constant memory and texture memory
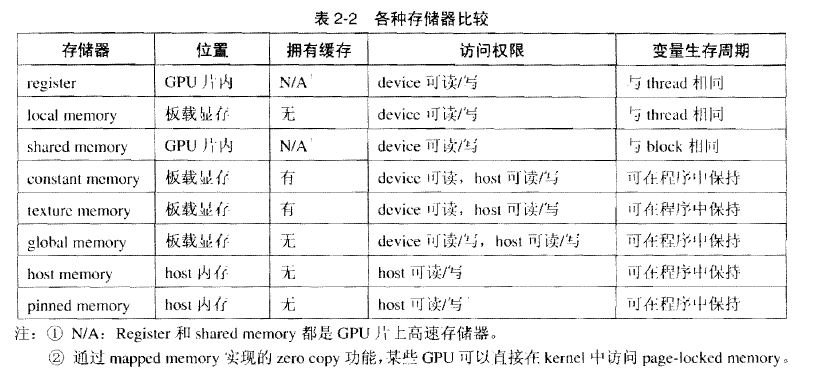
1、 寄存器Register
寄存器是GPU上的高速缓存器,其基本单元是寄存器文件,每个寄存器文件大小为32bit.
Kernel中的局部(简单类型)变量第一选择是被分配到Register中。
特点:每个线程私有,速度快。
2、 局部存储器 local memory
当register耗尽时,数据将被存储到local memory。如果每个线程中使用了过多的寄存器,或声明了大型结构体或数组,或编译器无法确定数组大小,线程的私有数据就会被分配到local memory中。
特点:每个线程私有;没有缓存,慢。
注:在声明局部变量时,尽量使变量可以分配到register。如:
unsigned int mt[3];
改为: unsigned int mt0, mt1, mt2;
3、 共享存储器 shared memory
可以被同一block中的所有线程读写
特点:block中的线程共有;访问共享存储器几乎与register一样快.

1 //u(i)= u(i)^2 + u(i-1)
2 //Static
3 __global__ example(float* u) {
4 int i=threadIdx.x;
5 __shared__ int tmp[4];
6 tmp[i]=u[i];
7 u[i]=tmp[i]*tmp[i]+tmp[3-i];
8 }
9
10 int main() {
11 float hostU[4] = {1, 2, 3, 4};
12 float* devU;
13 size_t size = sizeof(float)*4;
14 cudaMalloc(&devU, size);
15 cudaMemcpy(devU, hostU, size,
16 cudaMemcpyHostToDevice);
17 example<<<1,4>>>(devU, devV);
18 cudaMemcpy(hostU, devU, size,
19 cudaMemcpyDeviceToHost);
20 cudaFree(devU);
21 return 0;
22 }
23
24 //Dynamic
25 extern __shared__ int tmp[];
26
27 __global__ example(float* u) {
28 int i=threadIdx.x;
29 tmp[i]=u[i];
30 u[i]=tmp[i]*tmp[i]+tmp[3-i];
31 }
32
33 int main() {
34 float hostU[4] = {1, 2, 3, 4};
35 float* devU;
36 size_t size = sizeof(float)*4;
37 cudaMalloc(&devU, size);
38 cudaMemcpy(devU, hostU, size, cudaMemcpyHostToDevice);
39 example<<<1,4,size>>>(devU, devV);
40 cudaMemcpy(hostU, devU, size, cudaMemcpyDeviceToHost);
41 cudaFree(devU);
42 return 0;
43 }
4、 全局存储器 global memory
特点:所有线程都可以访问;没有缓存
//Dynamic
__global__ add4f(float* u, float* v) {
int i=threadIdx.x;
u[i]+=v[i];
}
int main() {
float hostU[4] = {1, 2, 3, 4};
float hostV[4] = {1, 2, 3, 4};
float* devU, devV;
size_t size = sizeof(float)*4;
cudaMalloc(&devU, size);
cudaMalloc(&devV, size);
cudaMemcpy(devU, hostU, size,
cudaMemcpyHostToDevice);
cudaMemcpy(devV, hostV, size,
cudaMemcpyHostToDevice);
add4f<<<1,4>>>(devU, devV);
cudaMemcpy(hostU, devU, size,
cudaMemcpyDeviceToHost);
cudaFree(devV);
cudaFree(devU);
return 0;
} //static
__device__ float devU[4];
__device__ float devV[4]; __global__ addUV() {
int i=threadIdx.x;
devU[i]+=devV[i];
} int main() {
float hostU[4] = {1, 2, 3, 4};
float hostV[4] = {1, 2, 3, 4};
size_t size = sizeof(float)*4;
cudaMemcpyToSymbol(devU, hostU, size, 0, cudaMemcpyHostToDevice);
cudaMemcpyToSymbol(devV, hostV, size, 0, cudaMemcpyHostToDevice);
addUV<<<1,4>>>();
cudaMemcpyFromSymbol(hostU, devU, size, 0, cudaMemcpyDeviceToHost);
return 0;
}
5、 常数存储器constant memory
用于存储访问频繁的只读参数
特点:只读;有缓存;空间小(64KB)
注:定义常数存储器时,需要将其定义在所有函数之外,作用于整个文件
1 __constant__ int devVar;
2 cudaMemcpyToSymbol(devVar, hostVar, sizeof(int), 0, cudaMemcpyHostToDevice)
3 cudaMemcpyFromSymbol(hostVar, devVar, sizeof(int), 0, cudaMemcpyDeviceToHost)
6、 纹理存储器 texture memory
是一种只读存储器,其中的数据以一维、二维或者三维数组的形式存储在显存中。在通用计算中,其适合实现图像处理和查找,对大量数据的随机访问和非对齐访问也有良好的加速效果。
特点:具有纹理缓存,只读。
CUDA memory的更多相关文章
- CUDA ---- Memory Model
Memory kernel性能高低是不能单纯的从warp的执行上来解释的.比如之前博文涉及到的,将block的维度设置为warp大小的一半会导致load efficiency降低,这个问题无法用war ...
- CUDA ---- Memory Access
Memory Access Patterns 大部分device一开始从global Memory获取数据,而且,大部分GPU应用表现会被带宽限制.因此最大化应用对global Memory带宽的使用 ...
- 并行程序设计---cuda memory
CUDA存储器模型: GPU片内:register,shared memory: host 内存: host memory, pinned memory. 板载显存:local memory,cons ...
- cuda培训素材
http://www.geforce.cn/hardware/desktop-gpus/geforce-gtx-480/architecture http://cache.baiducontent.c ...
- 详解第一个CUDA程序kernel.cu
CUDA是一个基于NVIDIA GPU的并行计算平台和编程模型,通过调用CUDA提供的API,可以开发高性能的并行程序.CUDA安装好之后,会自动配置好VS编译环境,按照UCDA模板新建一个工程&qu ...
- 2.2CUDA-Memory(存储)和bank-conflict
在CUDA基本概念介绍有简单介绍CUDA memory.这里详细介绍: 每一个线程拥有自己的私有存储器,每一个线程块拥有一块共享存储器(Shared memory):最后,grid中所有的线程都可以访 ...
- [源码解析] PyTorch 流水线并行实现 (2)--如何划分模型
[源码解析] PyTorch 流水线并行实现 (2)--如何划分模型 目录 [源码解析] PyTorch 流水线并行实现 (2)--如何划分模型 0x00 摘要 0x01 问题 0x01 自动平衡 1 ...
- 如何设计一个高内聚低耦合的模块——MegEngine 中自定义 Op 系统的实践经验
作者:褚超群 | 旷视科技 MegEngine 架构师 背景介绍 在算法研究的过程中,算法同学们可能经常会尝试定义各种新的神经网络层(neural network layer),比如 Layer No ...
- TensorRT 开始
TensorRT 是 NVIDIA 自家的高性能推理库,其 Getting Started 列出了各资料入口,如下: 本文基于当前的 TensorRT 8.2 版本,将一步步介绍从安装,直到加速推理自 ...
随机推荐
- oracle 用mybatis生成主键
oracle主键是不能像mysql一样自动管理的,需要自己手动管理,先生成,再插入. <selectKey keyProperty="id" resultType=" ...
- mysql5.7脚本日常使用
#查看数据库物理存放目录show variables like "%datadir%";#查看所有数据库show databases#选择数据库use your_db_name#查 ...
- c++中赋值运算符重载为什么要用引用做返回值?
class string{ public: string(const char *str=NULL); string(const string& str); //copy构造函数的参数 ...
- (转)Shell脚本之break,continue,和exit区别
Linux脚本中的break continue exit return break结束并退出循环 continue在循环中不执行continue下面的代码,转而进入下一轮循环 exit退出脚本,常带一 ...
- 初识contiki(2.7版本)
一个偶然的机会,我接触到了contiki这个家伙. Contiki 是一个开源的.高度可移植的.采用 C 语言开发的非常小型的嵌入式操作系统,针对小内存微控制器设计,适用于联网嵌入式系统和无线传感器网 ...
- 换晶振导致stm32串口数据飞码的解决办法(补充)
今天(2014.4.21)把stm32f107的程序下载到stm32f103的板子上,发现串口收不到数据,突然想起晶振频率没有修改,#define HSE_VALUE ((uint32_t)13 ...
- The function getUserId must be used with a prefix when a default namespace is not specified 解决办法
The function getUserId must be used with a prefix when a default namespace is not specified 解决方法: 1. ...
- schema中属性声明
<attribute name="属性名" default="默认值" fixed="固定值" use="option ...
- EF框架
Linq to EF 添加: //用户注册int IUserDAO.Register(Users user) { ; using (EF.ddgwDBEntities context = new EF ...
- Akka探索第二个例子by fsharp
本文重度借鉴了github上akkabootcamp教程. 先上代码 open Akka open Akka.Actor open System type Message = | ContinuePr ...