Lucene学习入门——核心类API
本文讲解Lucene中,创建索引、搜索等常用到的类API
搜索操作比索引操作重要的多,因为索引文件只被创建一次,却要被搜索多次。

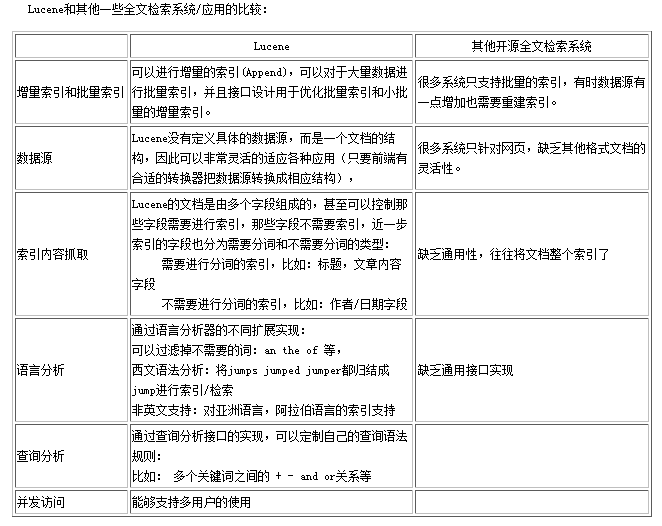

索引过程的核心类:
执行简单的索引过程需要如下几个类:IndexWriter, Directory, Analyzer, Document, Field

一、IndexWriter类
IndexWriter(写索引)是索引过程的核心组件。
负责创建新索引或者打开已有索引,以及向索引中添加、删除或更新被索引文档的信息。
它为你提供对索引文件的写入操作,但不能用于读取或搜索索引。IndexWriter需要开辟一定空间来存储索引,该功能可以由Directory完成。
二、Directory类
描述了Lucene索引的存放位置。是一个抽象类,它的子类负责具体指定索引的存储位置。
FSDirectory.open方法来获取真实文件在文件系统的存储路径,然后将它们依次传递给IndexWriter类构造方法。
Lucene包含大量有趣的Directory实现。IndexWriter不能直接索引文本,这需要先由Analyzer将文本分割成独立的单词才行。
三、Analyzer类
文件文件在被索引之前,需要经过Analyzer(分析器)处理。
Analyzer是由IndexWriter的构造方法来指定的,它负责从被索引文本文件中提取语汇单元,并提出剩下的无用信息。
如果被索引内容不是纯文本文件,那就需要先将其转换为文本文档。(Tika从常用的多媒体格式文件中提取文本内容)
Analyzer是一个抽象类,而Lucene提供了几个类实现它。这些类有的用于跳过停用词(stop words)(指一些常用的且不能帮助区分文档的词,如a, an,the, in,on等);有的用于把词汇单元转成小写形式,以使搜索过程能忽略大小写差别;除此之外,还有一些其他类。
Analyzer是Lucene很重要的一部分,它的用途远远不止过滤输入这一项。
分析器的分析对象为文档,该文档包含一些分离的能被索引的域。
四、Document
Document(文档)对象代表一些域(Field)的集合。可以将Document对象理解为虚拟文档——比如Web页面、E-mail信息或者文本文件——然后可以从中取回大量数据。
文档的域代表文档或者和文档相关的一些元数据。
文档的数据源(比如数据库记录、Word文档、书中的某章节等)对呀Lucene来说是无关紧要的。
Lucene只处理从二进制文档中提取的以Field实例形式出现的文本。
上述元数据(如作者、标题、主题和修改日期等)都作为文档的不同域单独存储并被索引。
Document对象的结构比较简单,为一个包含多个Field对象的容器;Field是指包含能被索引的文本内容的类。
五、Field类
索引中的每个文档都包含一个或多个不同命名的域,这些域包含在Field类中。每个域都有一个域名和对应的域只,以及一组选项来精确控制Lucene索引操作各个域值。
搜索过程的核心类:
IndexSearcher, Term, Query, TermQuery, TopDocs
一、IndexSearcher类
IndexSearcher类用于搜索由IndexWriter类创建的索引:公开了几个搜索方法,它是连接索引的中心环节。
Donate捐赠
如果我的文章帮助了你,可以赞赏我 6.66 元给我支持,让我继续写出更好的内容)


(微信) (支付宝)
微信/支付宝 扫一扫
Lucene学习入门——核心类API的更多相关文章
- Lucene学习入门——下载初识
本文从官网下载Lucene开始,一步一步进行Lucene的应用学习研究.下载初识Snowball Stemmer 1.下载 (1)首先,去Lucne的Apache官网主页 http://lucene. ...
- Lucene 02 - Lucene的入门程序(Java API的简单使用)
目录 1 准备环境 2 准备数据 3 创建工程 3.1 创建Maven Project(打包方式选jar即可) 3.2 配置pom.xml, 导入依赖 4 编写基础代码 4.1 编写图书POJO 4. ...
- U3D学习004——核心类和代码运行
1.U3D核心类 2.变量 只有public变量才可以显示在inspector面板中,[serializeField]可以使private和protected变量显示在inspector面板中. 3. ...
- Java学习_Java核心类
字符串和编码 字符串在String内部是通过一个char[]数组表示的,因此,可以按下面的写法: String s2 = new String(new char[] {'H', 'e', 'l', ' ...
- Javaweb学习笔记——(十七)——————JDBC的原理、四大核心类、四大参数、预编译、Dao模式、批处理、大数据、时间类型的转换
JDBC入门 *导入jar包:驱动 *加载驱动类:Class.forName("类名"); *给出url.username.password,其中url背下来 *使用DriverM ...
- 理解Lucene索引与搜索过程中的核心类
理解索引过程中的核心类 执行简单索引的时候需要用的类有: IndexWriter.Directory.Analyzer.Document.Field 1.IndexWriter IndexWr ...
- Lucene.net入门学习系列(2)
Lucene.net入门学习系列(2) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 在使用Luce ...
- Webwork 学习之路【03】核心类 ServletDispatcher 的初始化
1. Webwork 与 Xwork 搭建环境需要的的jar 为:webwork-core-1.0.jar,xwork-1.0.jar,搭建webwork 需要xwork 的jar呢?原因是这样的,W ...
- Lucene.net入门学习
Lucene.net入门学习(结合盘古分词) Lucene简介 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全 ...
随机推荐
- vue四、实例
1.new Vue创建根实例 2.data对象,所有的属性加入到 Vue 响应式系统-值发生改变时,视图自动变更为新值 只有实例被创建时存在的属性才会响应式改变,后增加的不会 vue定义的实例属性和方 ...
- hdu3567 八数码2(康托展开+多次bfs+预处理)
Eight II Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 130000/65536 K (Java/Others)Total S ...
- poj1125传播谣言(弗洛伊德,求最长路)
Stockbroker Grapevine Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 38541 Accepted: ...
- 07-图5 Saving James Bond - Hard Version (30 分)
This time let us consider the situation in the movie "Live and Let Die" in which James Bon ...
- asp.net搭建项目架构
项目的架构决定这个项目的好坏. 今天我说说传统三层架构的搭建 第一步 创建一个解决方案 例如 TaskSystem 接着这个解决方案下创建六个项目分别: TaskSystem.DAL TaskSyst ...
- n阶乘,位数,log函数,斯特林公式
一.log函数 头文件: #include <math.h> 使用: 引入#include<cmath> 以e为底:log(exp(n)) 以10为底:log10(n) 以m为 ...
- spark第一篇:RDD Programming Guide
预览 在高层次上,每一个Spark应用(application)都包含一个驱动程序(driver program),该程序运行用户的主函数(main function),并在集群上执行各种并行操作. ...
- 配置编译器(GCC和GFortran)
平台信息 Description: CentOS Linux release 7.6.1810 (Core) 检查环境 $ gfortran -v $ gcc -v 安装 GCC和Fortran 环境 ...
- android Activity启动过程(一)从startActivty开始说起
从启动startActivity开始说起 MainActivity.startActivity() Activity.startActivity() Activity.startActivityFor ...
- jndi理解
java中很多这些接口规范,jndi就是其中一个,而下面那些包就是jndi接口的提供商程序实现包,他们都是遵循jndi规范的. 主要接口功能是:添加命名与对象的映射到jndi树中,客户能快速查找并使用 ...