开放定址法——线性探测(Linear Probing)
之前我们所采用的那种方法,也被称之为封闭定址法。每个桶单元里存的都是那些与这个桶地址比如K相冲突的词条。也就是说每个词条应该属于哪个桶所对应的列表,都是在事先已经注定的。经过一个确定的哈希函数,这些绿色方块只会掉到K这个桶里,它不可能被散列到其他的桶单元。

与此同时,分离链接散列算法还有一个亟待解决的缺点:需要指针,由于给新单元分配地址需要时间,这就导致了速度减慢,所以不太好。还有,因为链表是次第关联的结构,实现算法的代码自身的复杂程度和出错概率会大大增加。而只要采用这种策略,就很难保证每组冲突的词条在空间上能够彼此毗邻,因为动态分配的节点在内存里不一定是连续的,这样一来会导致一个致命缺陷(上篇文章末尾提到过):对于稍大规模的词条集合,查找中将做大量的I/O操作,无法利用系统预先缓存,导致效率低下。
因此或许我们应该放弃这种策略,并反其道而行之,仅仅依靠基本的散列表结构,就地排解冲突反而是更好的选择。也就是采用所谓的开放定址策略,它的特点在于:散列表所占用的空间在物理上始终是地址连续的一块,相应的所有的冲突都在这块连续空间中加以排解。而无需向分离链接那样申请额外的空间。对!所有的散列以及冲突排解都在这样一块封闭的空间内完成。

因此相应地,这种策略也可以称作为闭散列。如果有冲突发生,就要尝试选择另外的单元,直到找到一个可供存放的空单元。具体存放在哪个单元,是有不同优先级的,优先级最高的是他原本归属的那个单元。从这个单元往后,都按照某种优先级规则排成一个序列,而在查找的时候也是按着这个序列行进,每个词条对应的这个序列被称为探测序列or查找链。
抽象来说,就是我们遇到冲突后,会相继尝试h0(x),h1(x),h2(x)这些单元,其中hi(x)= ( Hash( x ) + F ( I ) ) % TableSize,并且约定F(0)=0,F(x)是解决冲突的方法,就是刚才说的那个“优先级规则”。因为所有的数据都要放在这块空间,所以开放定址所需要的表规模比分离链接要大。通常而言开放定址法的装填因子lambda应该低于0.5。而根据对不同F(x)的选择,学界划分出三种常用的探测序列:线性探测法、平方探测法、双散列
下面要求各单位、各部门学习贯彻《关于解决散列表冲突问题的三种开放定址方法》
1.线性探测法
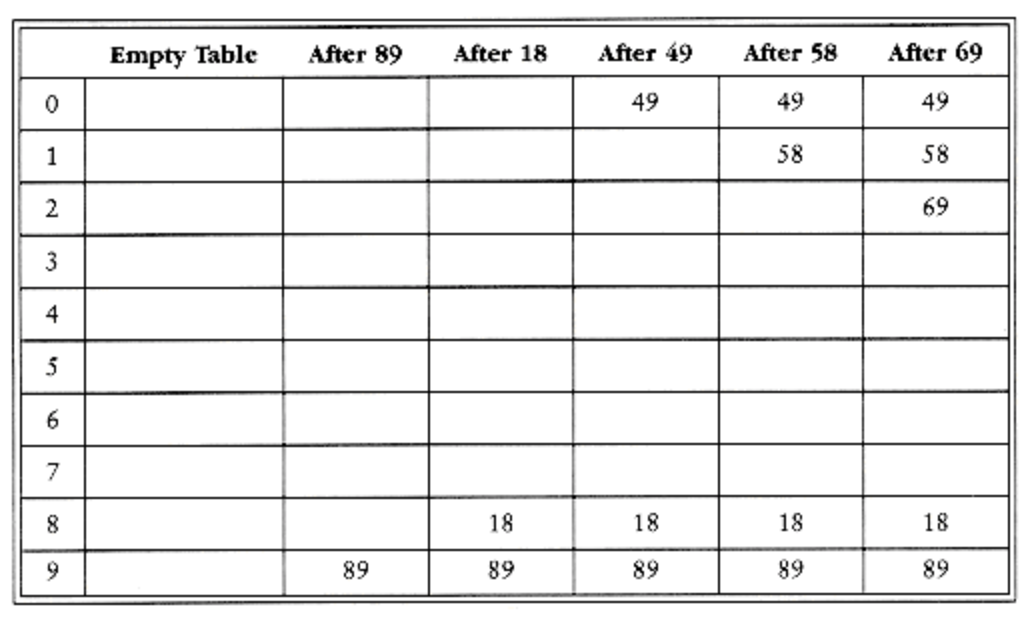
在线性探测法中,函数F是关于i的线性函数,典型的情形是F(i)=i。这相当于逐个探测每个单元(必要时可以绕回)以查找出一个空单元。下面显示了将{89,18,49,58,69}插入到一个散列表中的情况(竖着看),使用了和之前一样的散列函数hash(x)=x%size,他们有冲突怎么办?用F(i)=i这个方法,每次从i=0开始尝试,那么根据hi(x)= ( Hash( x ) + F ( I ) ) % TableSize就可以计算出各自不相冲突的地址了。完美!(暂时的)

我们脑内单步调试一下:第一个冲突在49产生:(49%10+0)%10=9,被89占了,那接着往后试,i=1,(49%10+1)%10=0,空的,放入这个空闲地址,这个地址是开放的。58依次和18,89,49产生冲突,试选三次后才找到一个空单元。对69的冲突也如此解决,一旦冲突,试探紧邻其后的单元,直至找到空单元or抵达散列表末尾。线性探测序列0->1->2->3在物理上保持连贯性的,具有局部性,这样一来系统的缓存作用将得到充分发挥,而对于大规模的数据集,这样一来更是可以减少I/O的次数。只要表足够大,总能找到一个空闲单元,但是这太费时间了。更糟的是——就算一开始空闲区域多,经过多次排解冲突后,数据所占据的单元也会开始形成一些区块,聚集在一起,被称为一次聚集(primary clustering),但在前面动机篇里说过,散列函数的初衷是避免数据扎堆,所以后面必须改进。
那么总体看来散列到区块的任何关键字都需要多次试选单元才能解决冲突,然后被放到对应的那个区块里。下面做一个总结
优点:
- 无需附加空间(指针、链表、溢出区)
- 探测序列具有局部性,可以利用系统缓存,减少IO
缺点:
- 耗费时间>O(1)
- 冲突增多——以往的冲突会导致后续的连环冲突,发生惨烈的车祸

光看这个图可能没什么感觉,举个例子吧,这样感触更深。我们开一个size=7的散列表,也保证了size是素数。把{0,1,2,3,7},就按这个顺序依次插入。前四个数都没问题,依次插入没有冲突。

但是为了插入7,我们先试探0发现非空,往后走,依次试探1,2,3都非空,直到4可以放进去。

在这个散列表的生存期里只有1个发生冲突。看似很棒对吧,再来看另一插入次序:{7,0,1,2,3}。

插入7没问题,但插入0的时候就有冲突了,实际上自此之后每一个数插入都会遇到冲突,前后对比可以看出,第二种插入顺序发生的很多冲突本来是可以避免的。这个时候想必我们改进这种策略的意愿就十分迫切了。
要支持词条的删除则需要格外的小心,现在我们来做一探讨。按照线性探测的规则,先后插入彼此冲突的一组词条都将存放在同一个查找序列中,而更确切的讲:它们应该按照逻辑次序构成整个查找链的一个前缀,其中不得有任何的空桶缝隙。因此词条的删除操作需要做额外的一些处理,如果我们不做一些事先准备,直接将词条删除(就类似对于链表,删除节点的时候不做链条调整,而直接free那个单元,那不直接凉了),就会造成查找链断裂,后续词条丢失——明明存在但访问不到。
对于这种连续空间的单元删除,一个直观的构想是:将后续词条悉数取出,再重新插入。但这太特么慢了,时间复杂度爆炸。其实对于这个问题有一种典型的处理手法:lazy delete,仅做一个删除标记,比如里面预留一个del变量,设置为TRUE。

那么在日后查找中,遇到他之后就应该越过继续往后查找而不是在此返回。在插入时遇到,就把它视作一个空单元,数据覆盖即可。应该说针对开放定址策略,懒惰删除不仅是“不得已而为之”的方法,甚至可以说是针对这种情况的最优方法。因为毕竟在开放定址策略中,每一个桶单元都同时属于多个查找链。
下面咱们聊聊严肃点的事,做一些细致分析。可以证明的是,使用线性探测的预期探测次数和装填因子存在函数关系,对于插入、查找失败的情况,大约需要$\frac{1}{2}\left( 1+\frac{1}{^{\left( 1-\lambda\right)^{2}}} \right)$次,对于查找成功的情况需要$\frac{1}{2}\left( 1+\frac{1}{\left( 1-\lambda\right)} \right)$次,这个显然更快一些。相关的证明过程和计算推导有点复杂…这里就直接给出结论。
那这个性能如何呢,我们仔细来推敲一下,虽然刚才从感性认识的角度,我们能察觉到线性探测是有必要改进的,因为:我们能感知到,表中已有元素越多,新插入时需要探测的次数就越多,这貌似不是个好兆头。但是用数学背景作为背书才是有说服力的。(下面可能有点难以理解,但尽量试着理解吧)

对于随机冲突的解决方法而言,可以假设每次探测与之前的探测无关,这是成立的,因为随机。并且假设有一个很大规模的表,先计算单次失败查找的期望探测次数——这也是找到一个空单元的期望次数。已知空单元所占比例是1-λ,那么预计需要探测的单元数量是$\frac{1}{1-\lambda}$。因此我们可以使用单次失败查找的开销来计算查找成功的平均开销。
这句话的内在逻辑是这样的“失败查找的探测次数=插入时探测次数=查找成功的探测次数”,看似挺矛盾的,我一开始也不太理解,但我们仔细分析一下就能认识到它的道理:首先,右式,一次成功查找的探测次数就等于这个元素插入的探测次数,这个不难理解,插入的时候探测n次,然后放入空单元;之后查找时也是探测n次,第n+1次探测直接命中,两者相等。然后说左式,在插入之前,即将插入时的的探测次数=失败查找的探测次数,因为插入前没有这个元素,自然查找失败。所以左式=右式,这就能大概理解了吧。
还有一件事,早期的λ比较小,所以造次插入开销较低,从更降低了平均开销。比如在上面那个表中,λ=0.5。
访问18的开销是在18被插入时确定的,此时λ=0.2,而由于18是插入到一个比较稀疏的表中,因此对他的访问比更晚插入的元素(e.g. 69)更容易。我们可以通过积分来估计平均的插入时间:
$I\left(\lambda\right)=\frac{1}{\lambda}\int_{0}^{\lambda }{\frac{1}{1-x}dx=\frac{1}{\lambda }\ln \frac{1}{1-\lambda}}$
这就比之前线性探测的公式更好了,另外,聚集这个问题,不仅是理论上棘手,在具体实现中也时隐时现,就像幽灵一样。一个幽灵,数据聚集的幽灵,在开放定址表里徘徊。为了对这个幽灵进行神圣的围剿,学界的一切势力,计算机科学家,数学家,还有各路工程师都联合起来了。(这个幽灵的确也为散列理论的创新发展提供了动力,是有一定进步意义的)
我们再来看,如果λ=0.75,那么上面的公式指出,线性探测中1次插入预计要进行8.5次探测。如果λ=0.9,你猜猜我们要找多少次能找到空单元?50次!这绝对不合理。从这些公式我们可以窥见:如果整个表>50%的区域被填满,那么线性探测就不是个好办法。但另一方面,如果是个稀疏表,λ很小,那么线性探测可谓如鱼得水了——我们就算按这个“小”的概念里撑死了说,λ=0.5,插入时平均只用探测…..猜猜….2.5次!,并且对于成功查找平均只需要探测1.5次,酷不酷! 要以时间条件地点为转移。
这再次说明了CS里权衡之术的地位,也是矛盾论的胜利,在矛盾普遍性原理的指导下,具体分析矛盾的特殊性,并找出解决矛盾的正确方法2333(扯远了扯远了)
下一篇我们讨论一个更优化的方案——平方探测法。
ps.转载请注明出处
开放定址法——线性探测(Linear Probing)的更多相关文章
- java 解决Hash(散列)冲突的四种方法--开放定址法(线性探测,二次探测,伪随机探测)、链地址法、再哈希、建立公共溢出区
java 解决Hash(散列)冲突的四种方法--开放定址法(线性探测,二次探测,伪随机探测).链地址法.再哈希.建立公共溢出区 标签: hashmaphashmap冲突解决冲突的方法冲突 2016-0 ...
- 开放定址法——平方探测(Quadratic Probing)
为了消除一次聚集,我们使用一种新的方法:平方探测法.顾名思义就是冲突函数F(i)是二次函数的探测方法.通常会选择f(i)=i2.和上次一样,把{89,18,49,58,69}插入到一个散列表中,这次用 ...
- Java解决Hash(散列)冲突的四种方法--开放地址法(线性探测,二次探测,伪随机探测)、链地址法、再哈希、建立公共溢出区
最近时间有点紧,暂时先放参考链接了,待有时间在总结一下: 查了好多,这几篇博客写的真心好,互有优缺点,大家一个一个看就会明白了: 参考 1. 先看这个明白拉链法(链地址法),这个带源码,很好看懂,只不 ...
- Python与数据结构[4] -> 散列表[2] -> 开放定址法与再散列的 Python 实现
开放定址散列法和再散列 目录 开放定址法 再散列 代码实现 1 开放定址散列法 前面利用分离链接法解决了散列表插入冲突的问题,而除了分离链接法外,还可以使用开放定址法来解决散列表的冲突问题. 开放定 ...
- C# Dictionary源码剖析---哈希处理冲突的方法有:开放定址法、再哈希法、链地址法、建立一个公共溢出区等
C# Dictionary源码剖析 参考:https://blog.csdn.net/exiaojiu/article/details/51252515 http://www.cnblogs.com/ ...
- Hash冲突的线性探测开放地址法
在实际应用中,无论如何构造哈希函数,冲突是无法完全避免的. 开放地址法 这个方法的基本思想是:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止.这个过程可用下式描述: ...
- [MIT6.006] 10. Open Addressing, Cryptographic Hashing 开放定址,加密哈希
前几节课讲散列表的时候,我们需要用Chaining,链接法需要用到指针pointer,但有一种方法可以不要Chaining和指针,还能在发生冲突时,为产生冲突的关键字寻找下一个"空" ...
- 线性探测再散列 建立HASH表
根据数据元素的关键字和哈希函数建立哈希表并初始化哈希表,用开放定址法处理冲突,按屏幕输出的功能表选择所需的功能实现用哈希表对数据元素的插入,显示,查找,删除. 初始化哈希表时把elem[MAXSIZE ...
- 面试准备 - HashTable 的C#实现 开放地址法
Hashtable是很经常在面试中遇到的数据结构,因为他的O(1)操作时间和O(n)空间 之所以自己写一份是因为: 加深对于hashtable的理解 某些公司面试的时候需要coding....... ...
随机推荐
- Python介绍以及Python环境搭建
Python介绍以及Python环境搭建 1.Python 发展历史 Python是由Guido van Rossum在八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的,据说是在圣诞 ...
- Struts2_Action和Result总结
Action 1.实现一个Actiond的最常用方式:从ActionSupport继承2.DMI动态方法调用3.通配符配置 *{1}{2}... a) *_*4.接收参数的方法(一般用属性或者Doma ...
- [RDLC]心得整理(一)
2014年在做项目的时候, 过用过RDLC, 之后便在没有使用过了. 最近又有项目使用rdlc, 感觉有些陌生,然后重新阅读了以前的笔记,想做一下整理. 常见问题: 1. 为什么rdlc报表出来的pd ...
- Azure进阶攻略丨如何驾驭罢工的Linux虚机网卡?
很多人的生活中,流传着一个屡试不爽,据说可以解决任何问题的百宝锦囊: 所以经常可以听到类似这样的对话: -我的电脑咋上不去网了? -重启一下电脑. -还是不行呢! -重启一下路由器. -怎么还不行-_ ...
- 《反脆弱》:软件业现成的鲁棒性(Robust)换了个说法变成了作者的发明,按作者的理论推导出许多可笑愚蠢的原则来
本书作者名气比较大,写过<黑天鹅><随机漫步的傻瓜>等书,据称专门研究不确定度性.本书是他以前的书的内容的延续. 所谓的反脆弱,其实软件业有现成的名词鲁棒性(Robust)就是 ...
- java文件
File类 为了很方便的代表文件的概念,以及存储一些对于文件的基本操作,在java.io包中设计了一个专门的类——File类. 在File类中包含了大部分和文件操作的功能方法,该类的对象可以代表一个具 ...
- unixbench安装及使用
unixbench 是一个用于測试 unix 系统性能的工具.也是一个比較通用的 benchmark, 此測试的目的是对类Unix 系统提供一个主要的性能指示,非常多測试用于系统性能的不同方面,这些測 ...
- 并查集,是否成树,Poj(1308)
思路: 对于每一条新的边的两个端点,是否是属于一颗树,要是的话,就不是一颗树.否则,就合并. 这里要注意的是,不能是森林,我这里WA了两次了.只不过在最后,查看每个节点的祖先是否是同一个就可以了. # ...
- VPS一键测试脚本 / 自带结果导出
脚本命令 一下脚本可能卡住,运行时间长,建议在screen中运行. 1.秋水逸冰大佬的Bench.sh脚本 特点:用时较短,对系统测试全面,英文:但缺少国内节点测速 有趣的是,bench.sh既是脚本 ...
- CSS select样式优化
下拉选择菜单基本的CSS样式不怎么好看,通过一些简单的样式优化,就可以起到美化的作用了. <div class="sel_wrap"> <label>请选择 ...