从零开始安装 Ambari (4) -- 通过 Ambari 部署 hadoop 集群
1. 打开 http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin
2. 点击 “LAUNCH INSTALL WIZARD”,开始创建一个集群
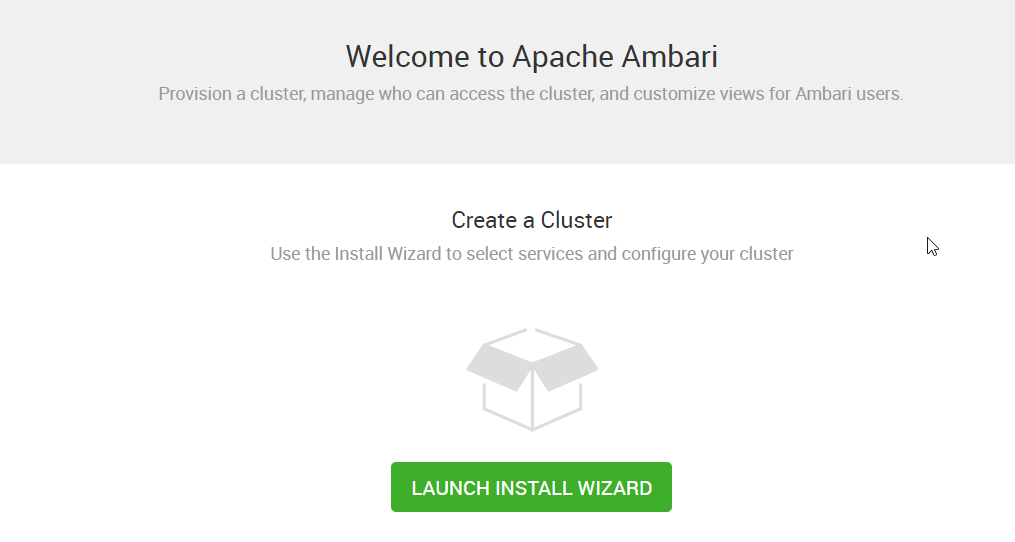
3. 为集群取一个名字
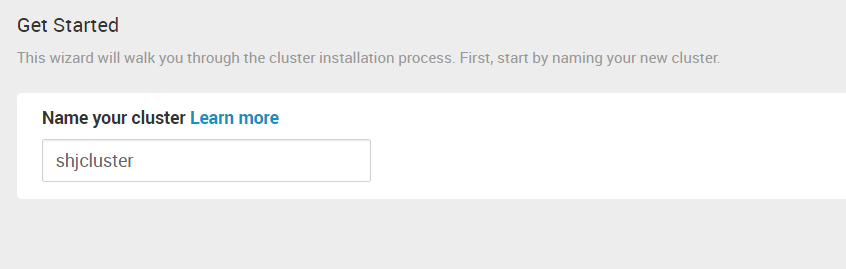
4. 前面我们建了本地的资源库,这里选择 “Use Local Repository”。删除其它的 OS,只留 redhat7 那一行。并且在 Base URL 那一列里填入前面搭建的 web 服务对应的地址。
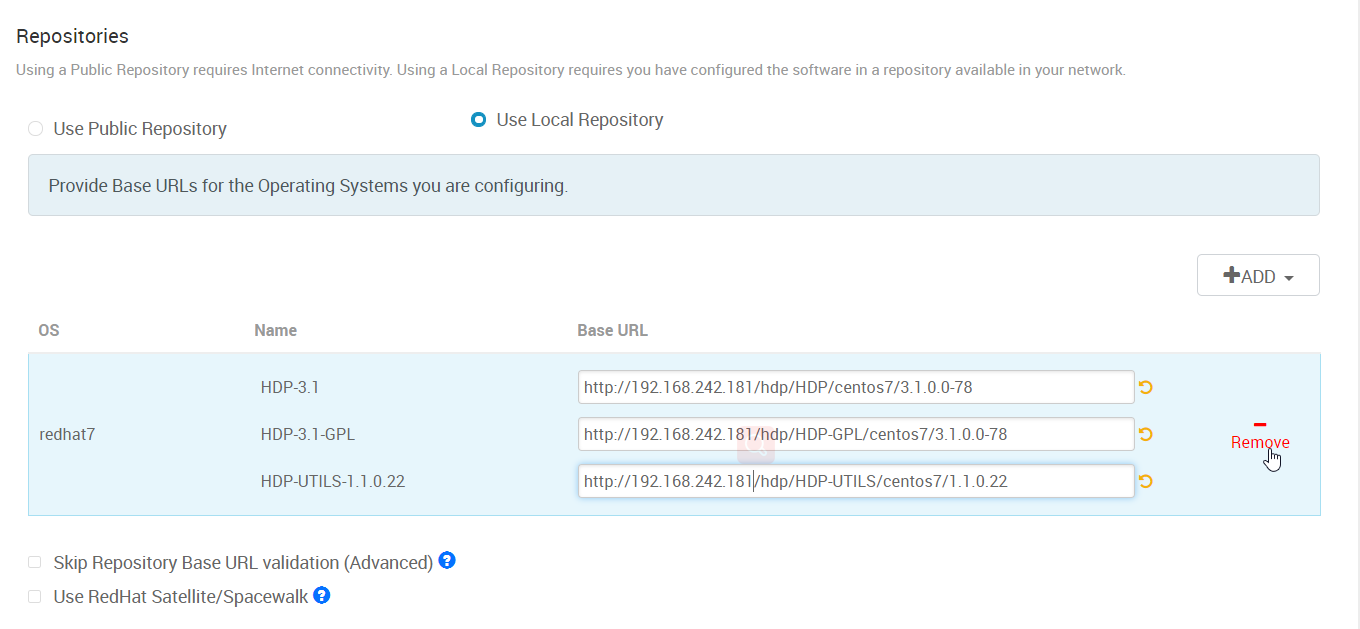
5. 在 “Target Hosts” 里填入 hadoop 集群需要部署到哪些机器。可以填 IP。
SSH Private Key 里选择的文件是 从零开始安装 Ambari (1) -- 安装前的准备工作 中配置免密登陆到其它机器的那台机器的 id_rsa 这个文件。我用的是 root 帐号,所以这个文件是在 /root/.ssh/ 目录下。
6. “Confirm Hosts” 这一步,ambari 会在上面的配置的 hosts 中安装 ambari agent,只需等待即可。
7. 根据需要,选择服务。如果某些服务依赖其它服务,而没有选择依赖的服务的话,点击“Next”时,会做相应的提示。
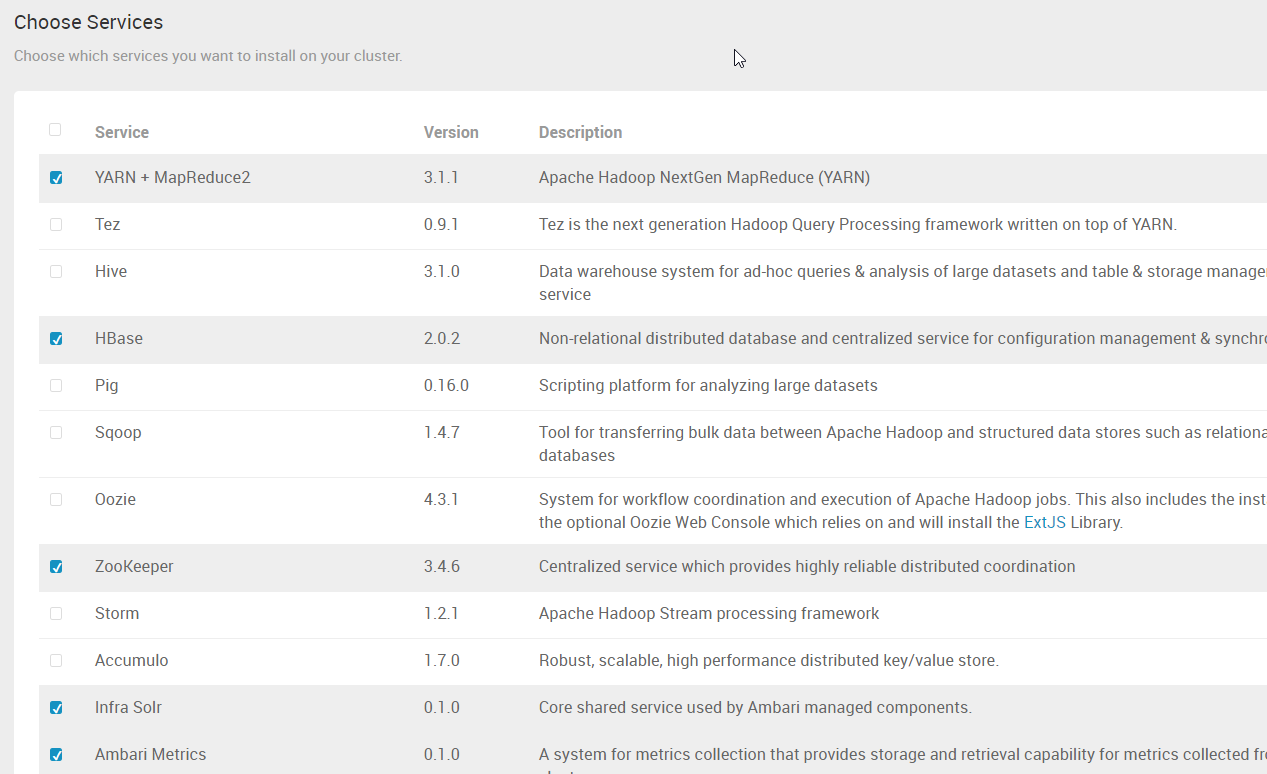
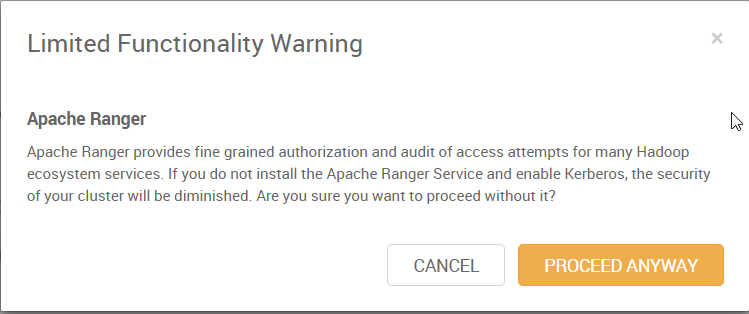
8. 点击 “Next”,如果出现类似下面的警告的话,可以不用管,后续如果需要的话,可以再安装
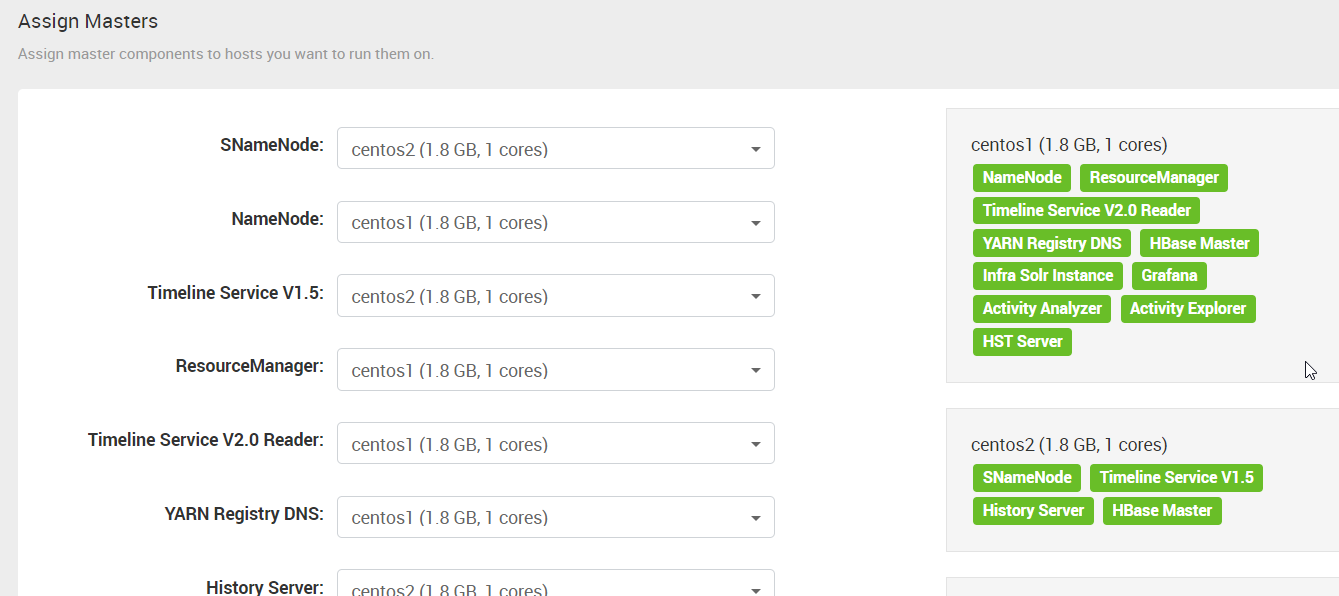
9. “Assign Masters” 这一步,ambari 会自动分配各种服务到不同的机器上。可以手动进行调整。
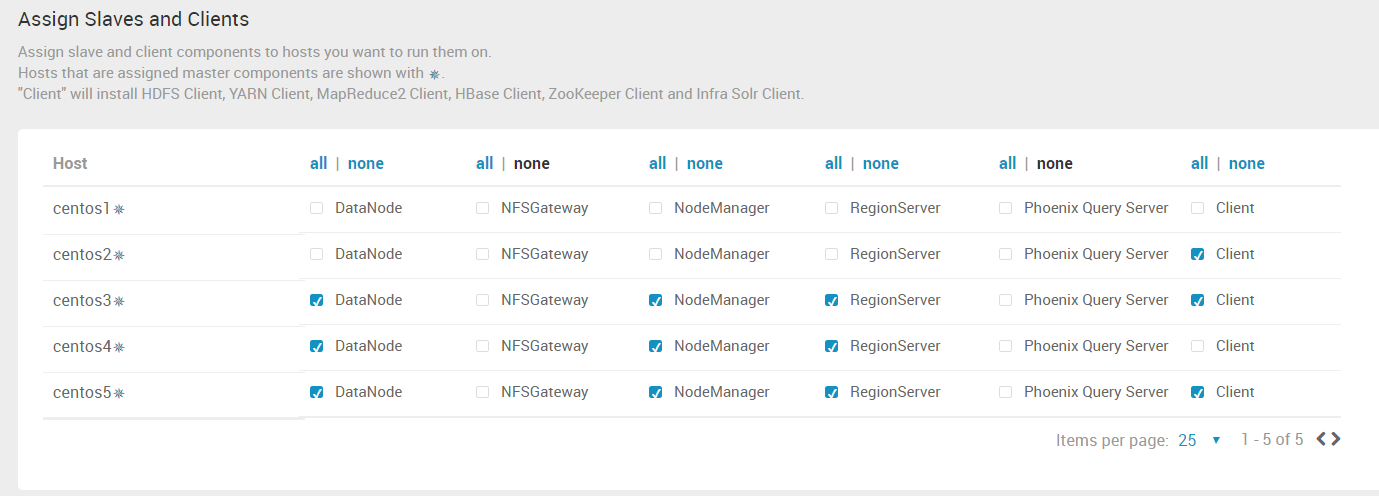
10. “Assign Slaves and Clients” 这一步,手动分配 Hadoop 的 DataNode 节点位置,YARN 的 NodeManager 的位置......
其中 NFSGateway 是通过挂载的方式,像访问本地文件系统一样访问 Hadoop 的文件系统。
Phoenix Query Server 是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
11. 设置密码。(有一行的 username 是 N/A,比较奇怪,不知道用在哪)
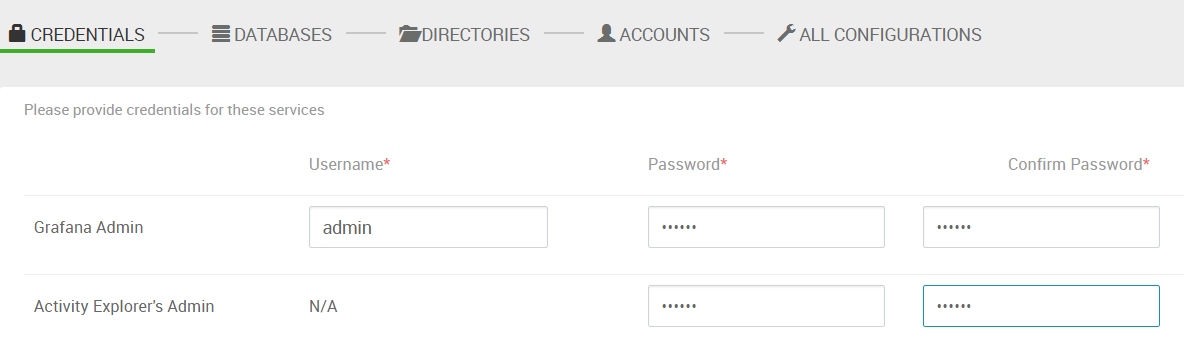
12. 数据库配置。如果选择了安装 hive 或 Ranger,需要输入相关的数据库的信息。此例中没有这一步。
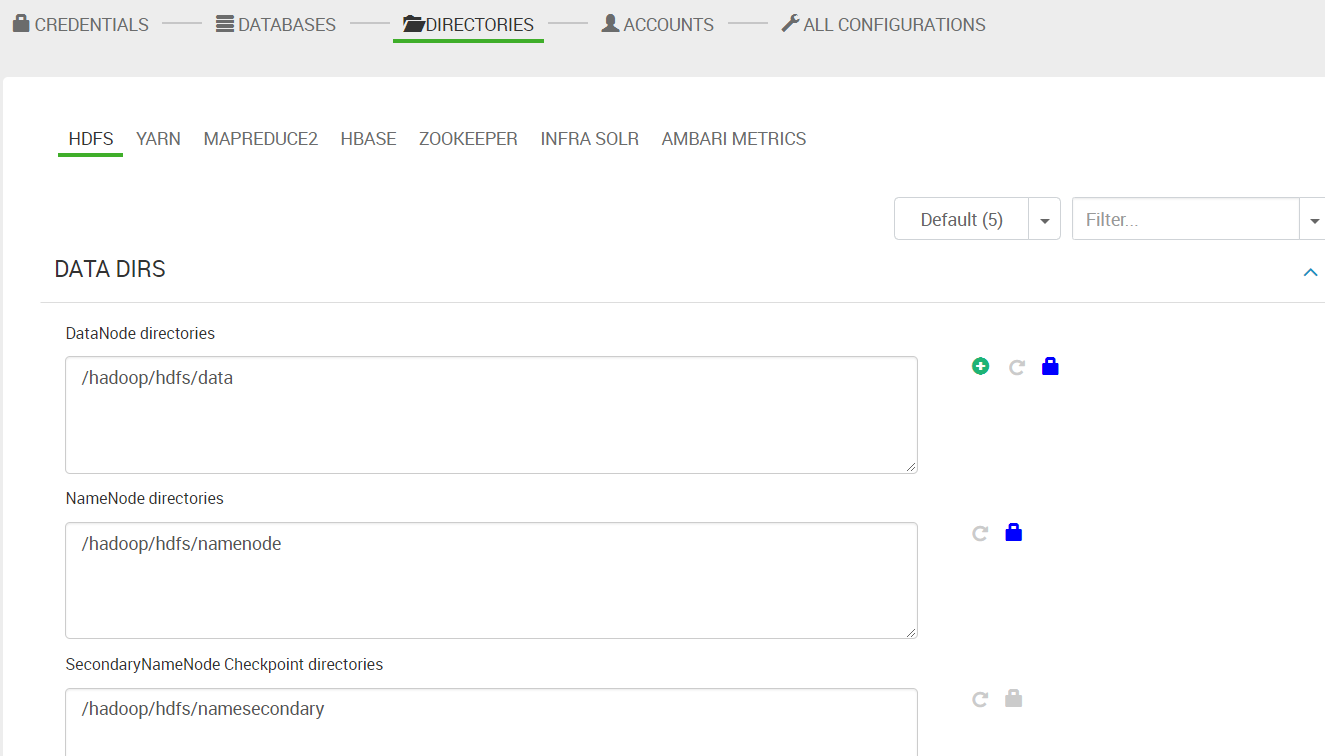
13. 目录配置。配置各个服务需要用到的目录。使用默认值即可。
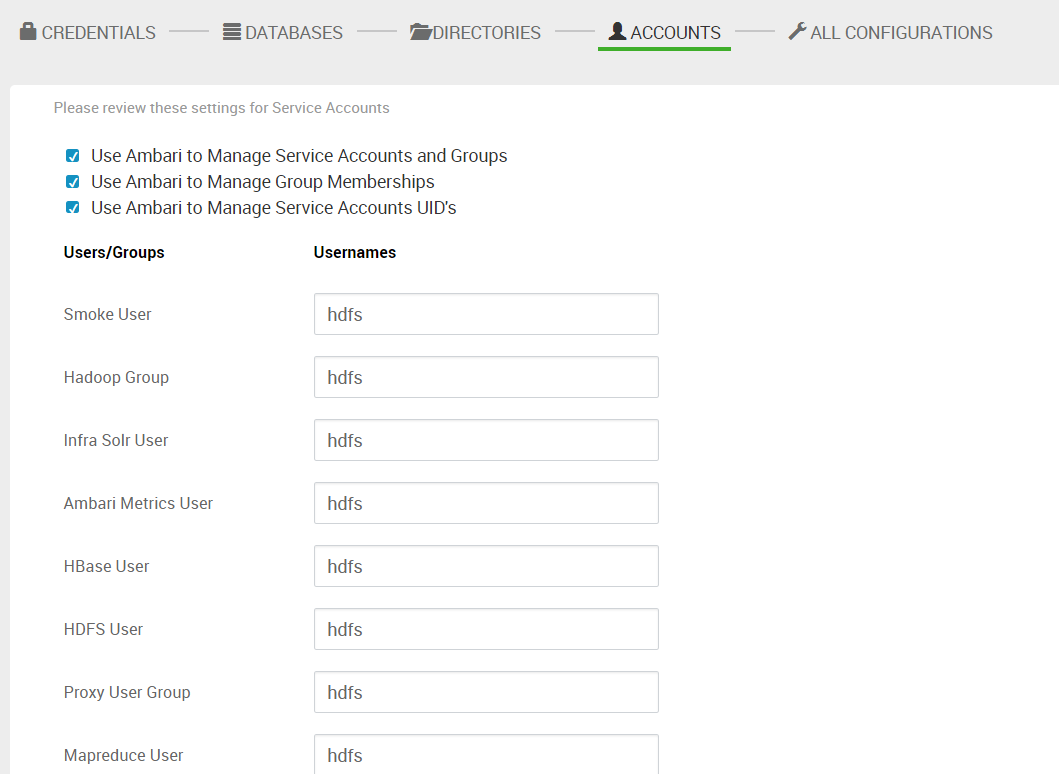
14. 创建用户。默认情况下, ambari 会为每个服务创建一个 linux 的用户,用不同的用户启动不同的服务。我设成了同一个用户。
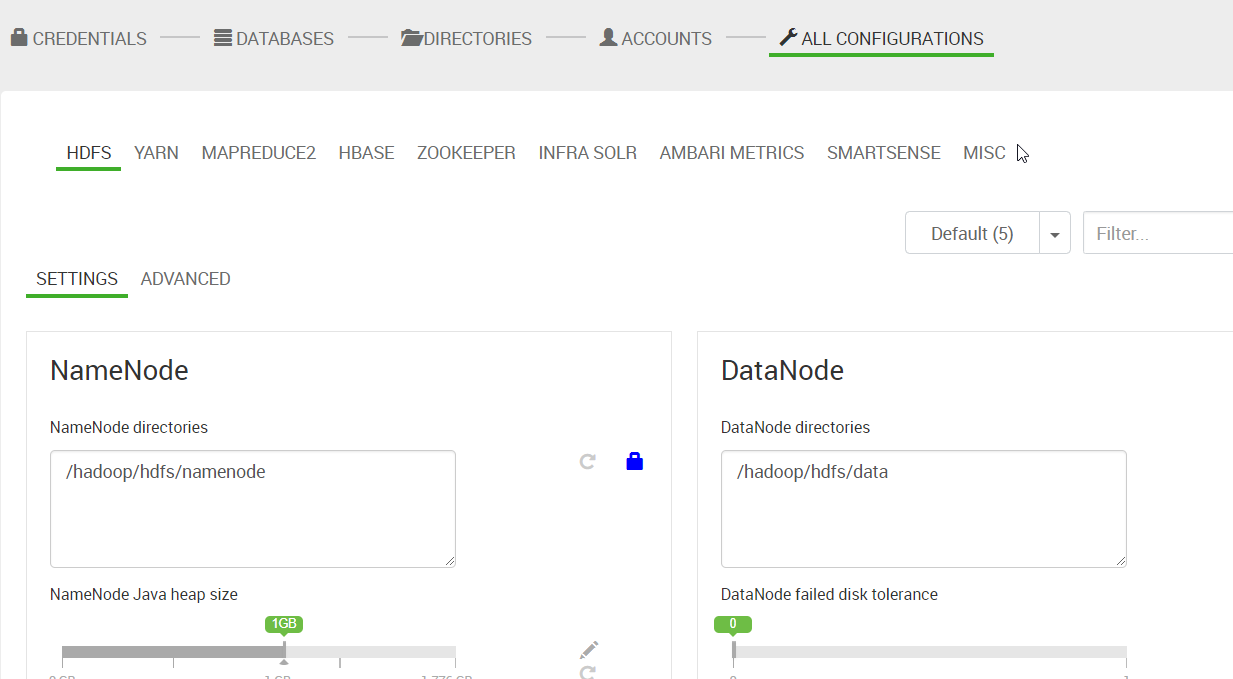
15. “ALL CONFIGURATIONS”,这一步可以修改前面的一些配置
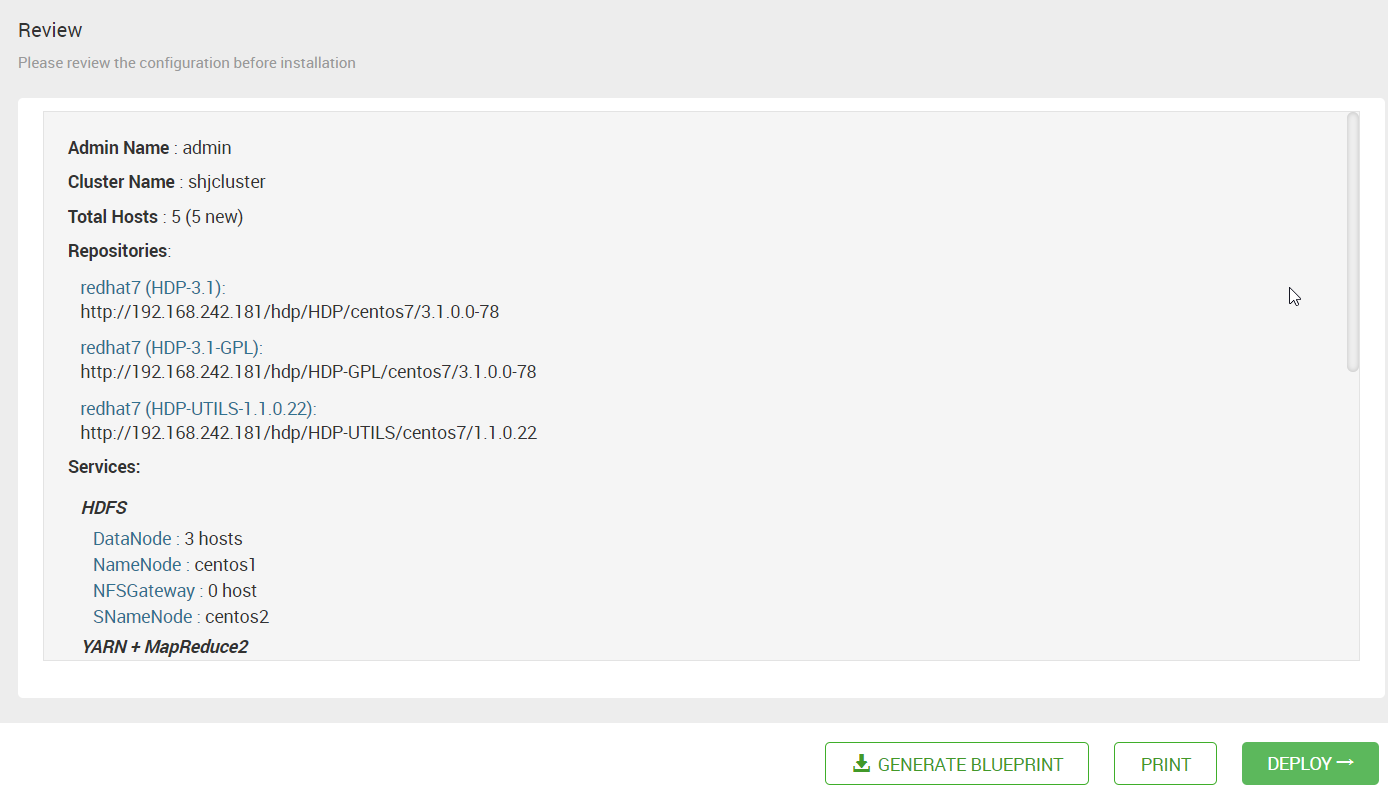
16. 点击 “Next”后,出现总结页。可以下载创建这个集群的元数据信息。点击 “DEPLOY” 后,就开始部署了。
从零开始安装 Ambari (4) -- 通过 Ambari 部署 hadoop 集群的更多相关文章
- 阿里云ECS服务器部署HADOOP集群(六):Flume 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(七):Sqoop 安装
本篇将在 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper) 阿 ...
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(四):Hive本地模式的安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 本地模式需要采用MySQL数据库存储数据. 1 环境介绍 一台阿里云ECS服务器:master ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- AMBARI部署HADOOP集群(4)
通过 Ambari 部署 hadoop 集群 1. 打开 http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin 2. 点击 “LAUNCH INS ...
- ambari部署Hadoop集群(2)
准备本地 repository 1. 下载下面的包 wget http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.7.3 ...
- Docker部署Hadoop集群
Docker部署Hadoop集群 2016-09-27 杜亦舒 前几天写了文章"Hadoop 集群搭建"之后,一个朋友留言说希望介绍下如何使用Docker部署,这个建议很好,Doc ...
- 实战CentOS系统部署Hadoop集群服务
导读 Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高 ...
随机推荐
- [转载]Python print函数用法,print 格式化输出
使用print输出各型的 字符串 整数 浮点数 出度及精度控制 strHello = 'Hello Python' print strHello #输出结果:Hello Python #直接出字符串 ...
- HTML5两个打包工具
AppCan:http://www.appcan.cn/ HBulider:http://www.dcloud.io/
- HTML 和 CSS
HTML html是英文hyper text mark-up language(超文本标记语言)的缩写,它是一种制作万维网页面标准语言. 内容摘要 Doctype 告诉浏览器使用什么样的htm ...
- 修改crushmap实验
标签(空格分隔): ceph,ceph实验,crushmap CRUSH的全称是Controlled Replication Under Scalable Hashing,是ceph数据存储的分布式选 ...
- iOS按home键后程序的状态变化
iOS 的应用里的几种状态: active: 应用在前台正常运行 background: 应用在后台,并且在执行代码. inactive: 这个状态是应用从一个状态向另一个状态的过渡 suspende ...
- python 三元表达式、列表推导式、生成器表达式
一 三元表达式.列表推导式.生成器表达式 一 三元表达式 name=input('姓名>>: ') res='mm' if name == 'hahah' else 'NB' print( ...
- DAY12-前端之HTML
一.html初识 web服务本质 import socket def main(): sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) ...
- hive与hbase整合方式和优劣
分别安装hive 和 hbase 1.在hive中创建与hbase关联的表 create table ganji_ranks (row string,num string) STORED BY 'or ...
- 手动编译安装tmux
tmux的好处就不多说了,总之是多屏管理的神器.通常我们用系统通用的安装方式可以安装到tmux,但有时候,安装到的可能不是我们所需要的版本,又或者软件源里面没有带tmux.这个时候就需要手动编译安装了 ...
- springJDBC01 利用springJDBC操作数据库
1 什么是springJDBC spring通过抽象JDBC访问并一致的API来简化JDBC编程的工作量.我们只需要声明SQL.调用合适的SpringJDBC框架API.处理结果集即可.事务由Spri ...