从零开始安装 Ambari (4) -- 通过 Ambari 部署 hadoop 集群
1. 打开 http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin
2. 点击 “LAUNCH INSTALL WIZARD”,开始创建一个集群
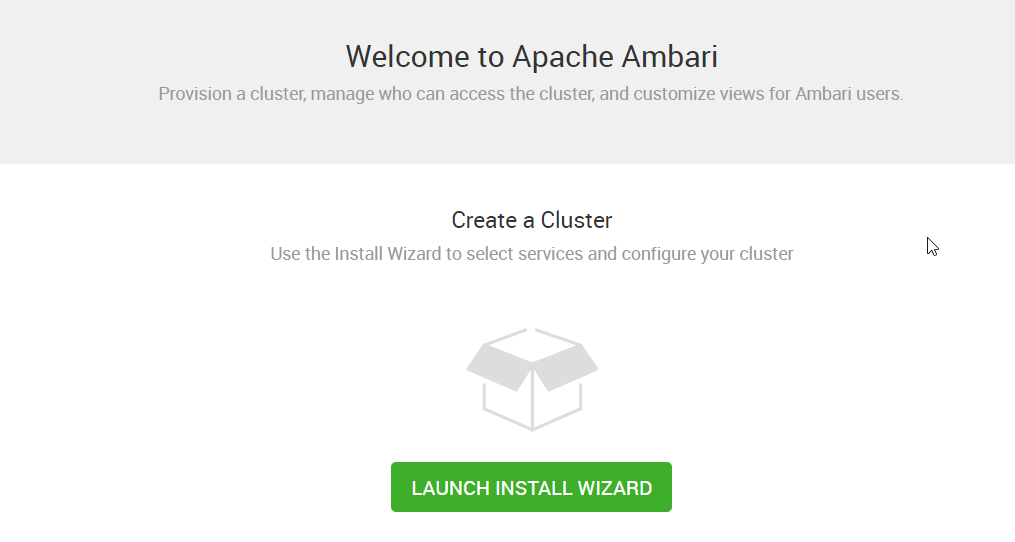
3. 为集群取一个名字
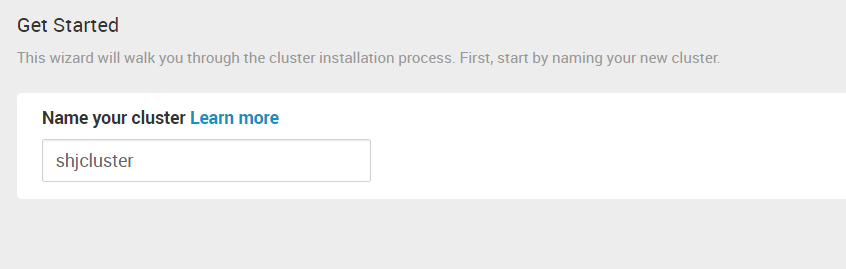
4. 前面我们建了本地的资源库,这里选择 “Use Local Repository”。删除其它的 OS,只留 redhat7 那一行。并且在 Base URL 那一列里填入前面搭建的 web 服务对应的地址。
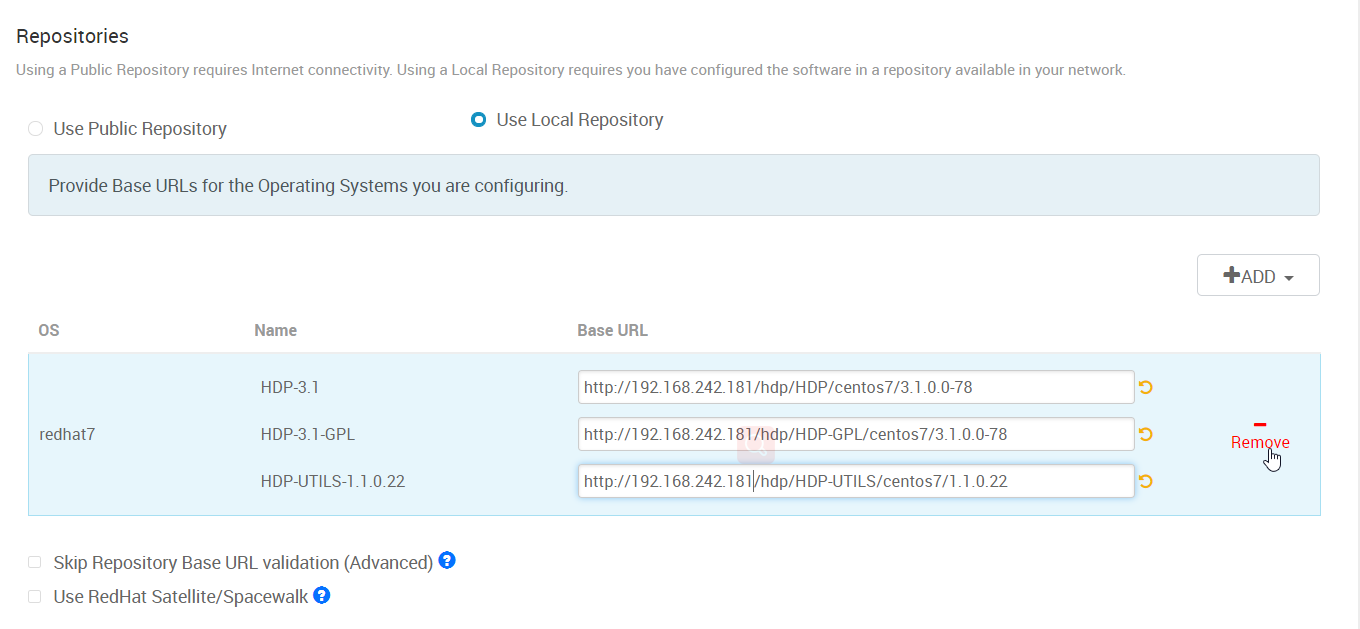
5. 在 “Target Hosts” 里填入 hadoop 集群需要部署到哪些机器。可以填 IP。
SSH Private Key 里选择的文件是 从零开始安装 Ambari (1) -- 安装前的准备工作 中配置免密登陆到其它机器的那台机器的 id_rsa 这个文件。我用的是 root 帐号,所以这个文件是在 /root/.ssh/ 目录下。
6. “Confirm Hosts” 这一步,ambari 会在上面的配置的 hosts 中安装 ambari agent,只需等待即可。
7. 根据需要,选择服务。如果某些服务依赖其它服务,而没有选择依赖的服务的话,点击“Next”时,会做相应的提示。
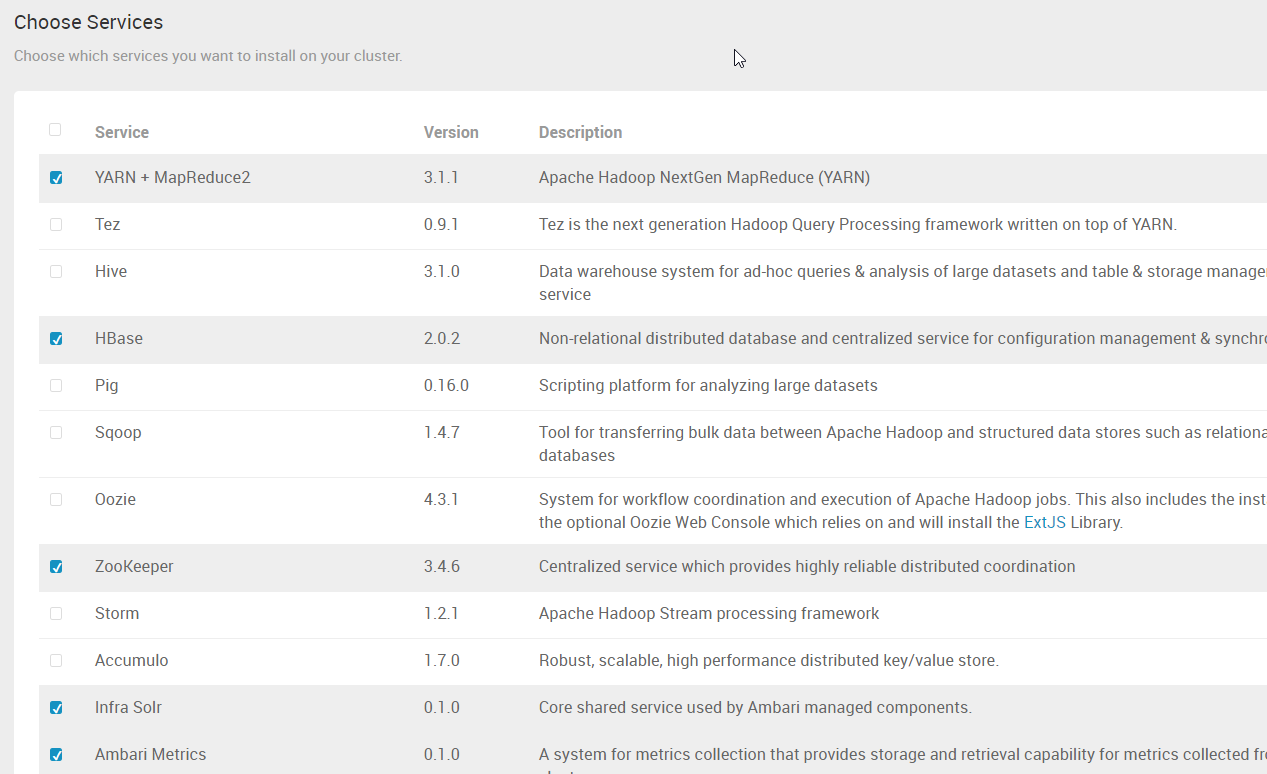
8. 点击 “Next”,如果出现类似下面的警告的话,可以不用管,后续如果需要的话,可以再安装
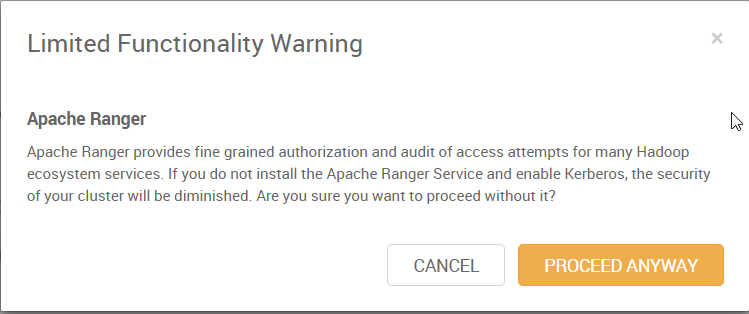
9. “Assign Masters” 这一步,ambari 会自动分配各种服务到不同的机器上。可以手动进行调整。
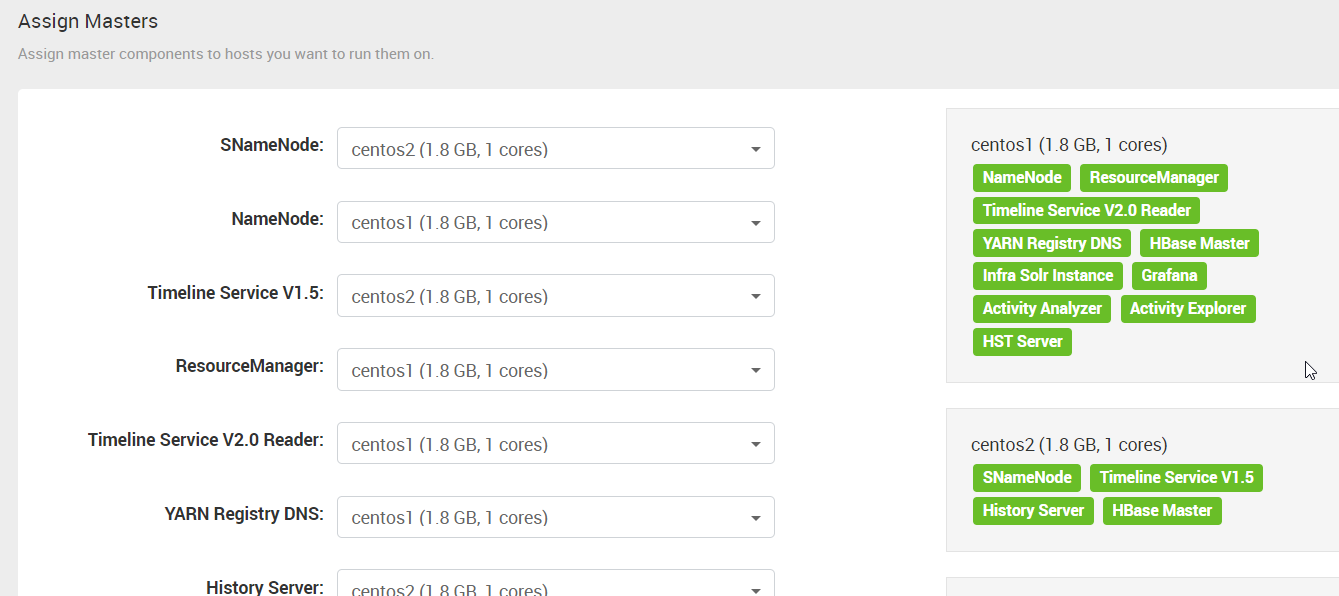
10. “Assign Slaves and Clients” 这一步,手动分配 Hadoop 的 DataNode 节点位置,YARN 的 NodeManager 的位置......
其中 NFSGateway 是通过挂载的方式,像访问本地文件系统一样访问 Hadoop 的文件系统。
Phoenix Query Server 是一个HBase的开源SQL引擎。你可以使用标准的JDBC API代替HBase客户端API来创建表,插入数据,查询你的HBase数据。
11. 设置密码。(有一行的 username 是 N/A,比较奇怪,不知道用在哪)
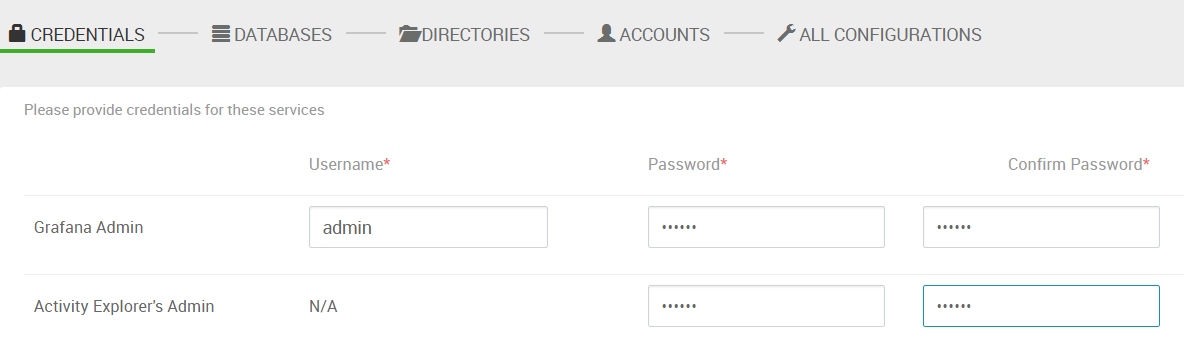
12. 数据库配置。如果选择了安装 hive 或 Ranger,需要输入相关的数据库的信息。此例中没有这一步。
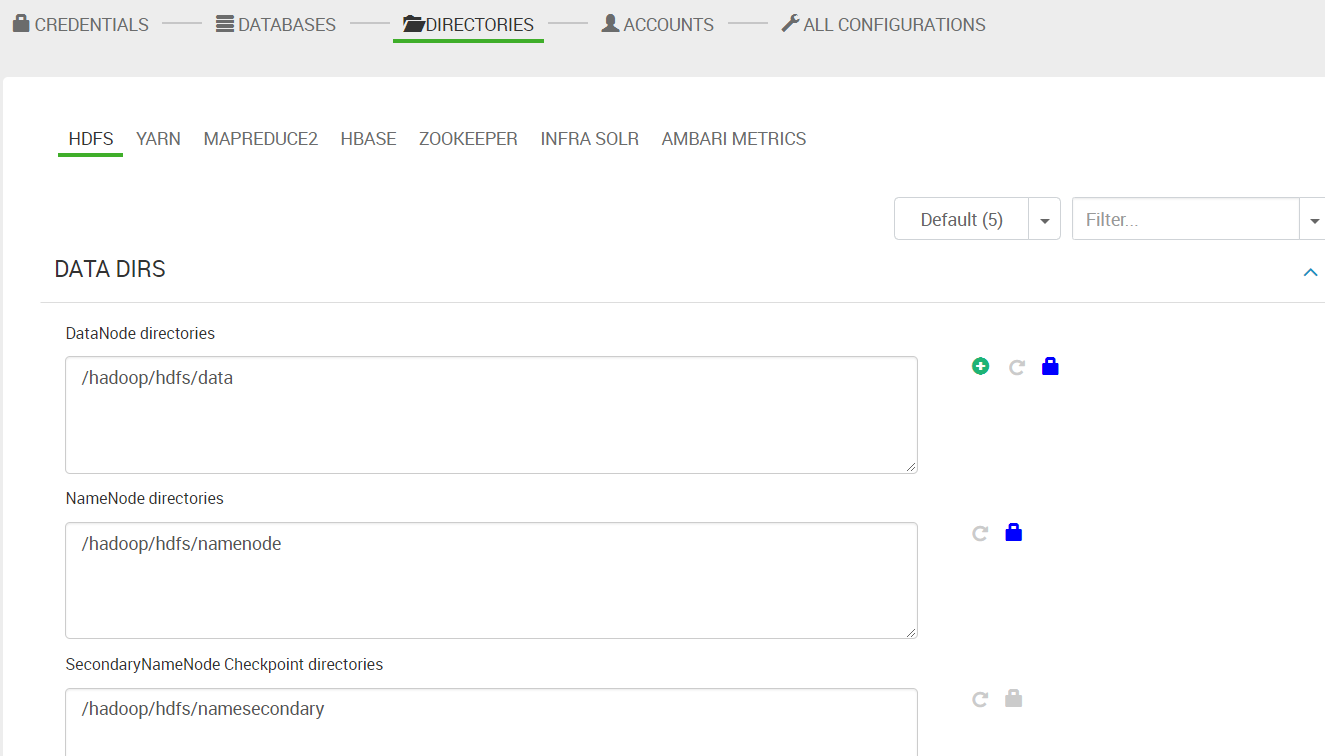
13. 目录配置。配置各个服务需要用到的目录。使用默认值即可。
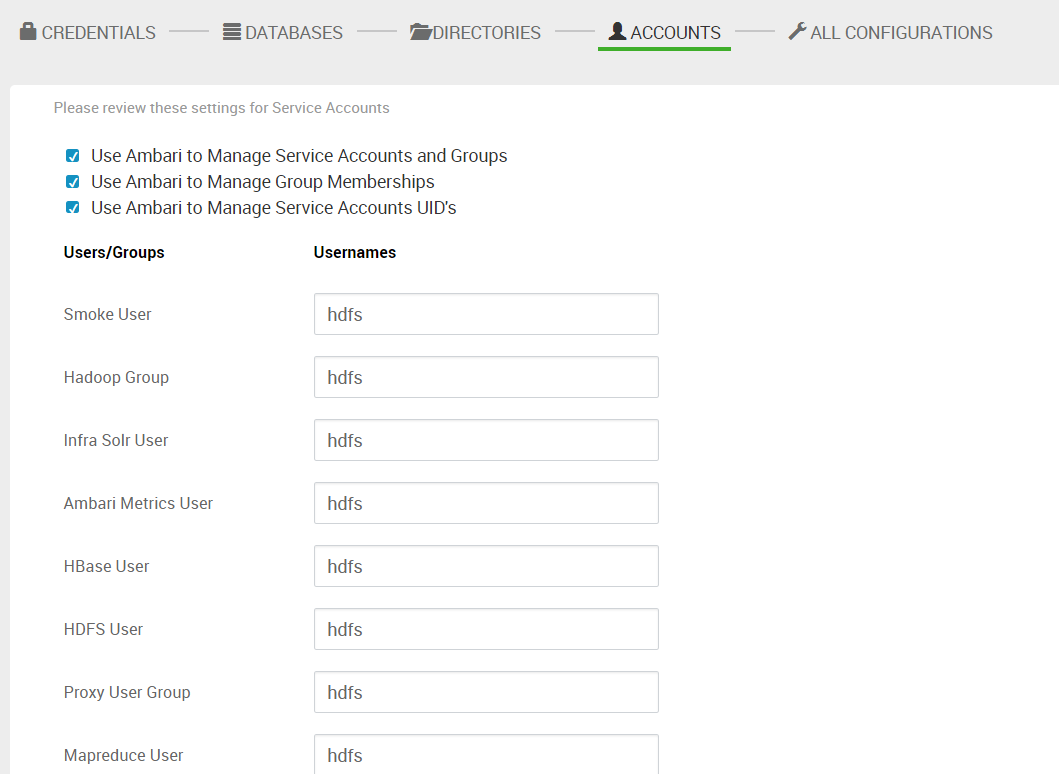
14. 创建用户。默认情况下, ambari 会为每个服务创建一个 linux 的用户,用不同的用户启动不同的服务。我设成了同一个用户。
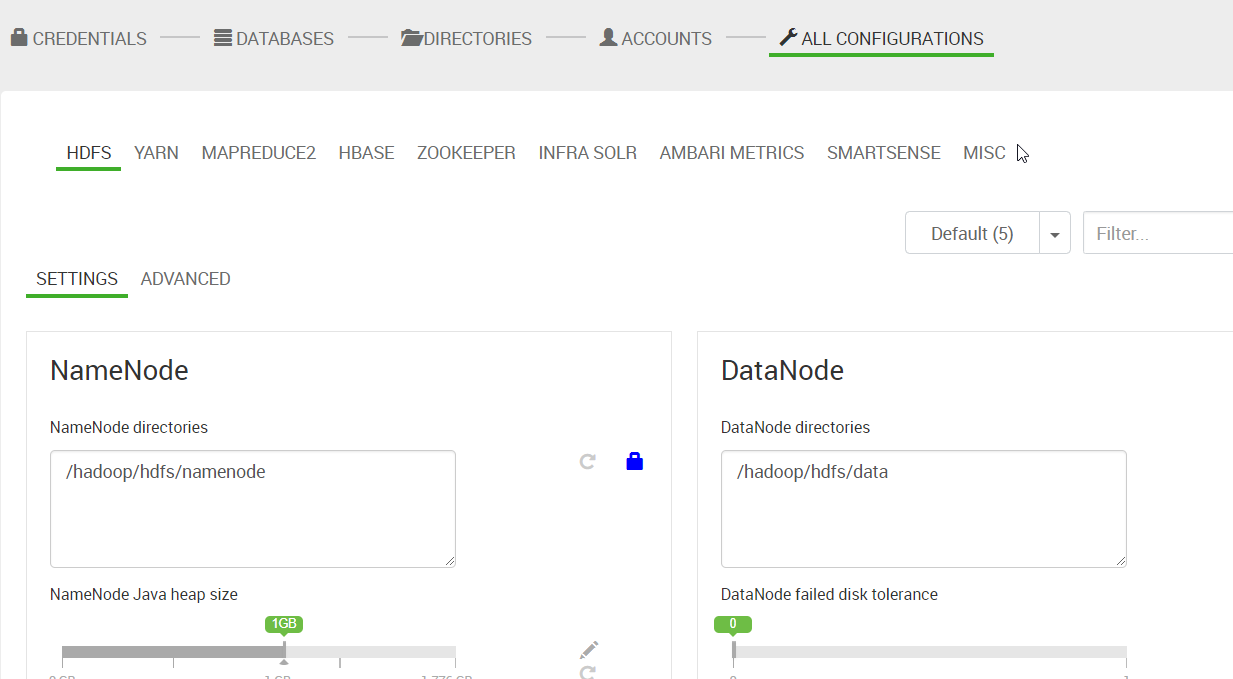
15. “ALL CONFIGURATIONS”,这一步可以修改前面的一些配置
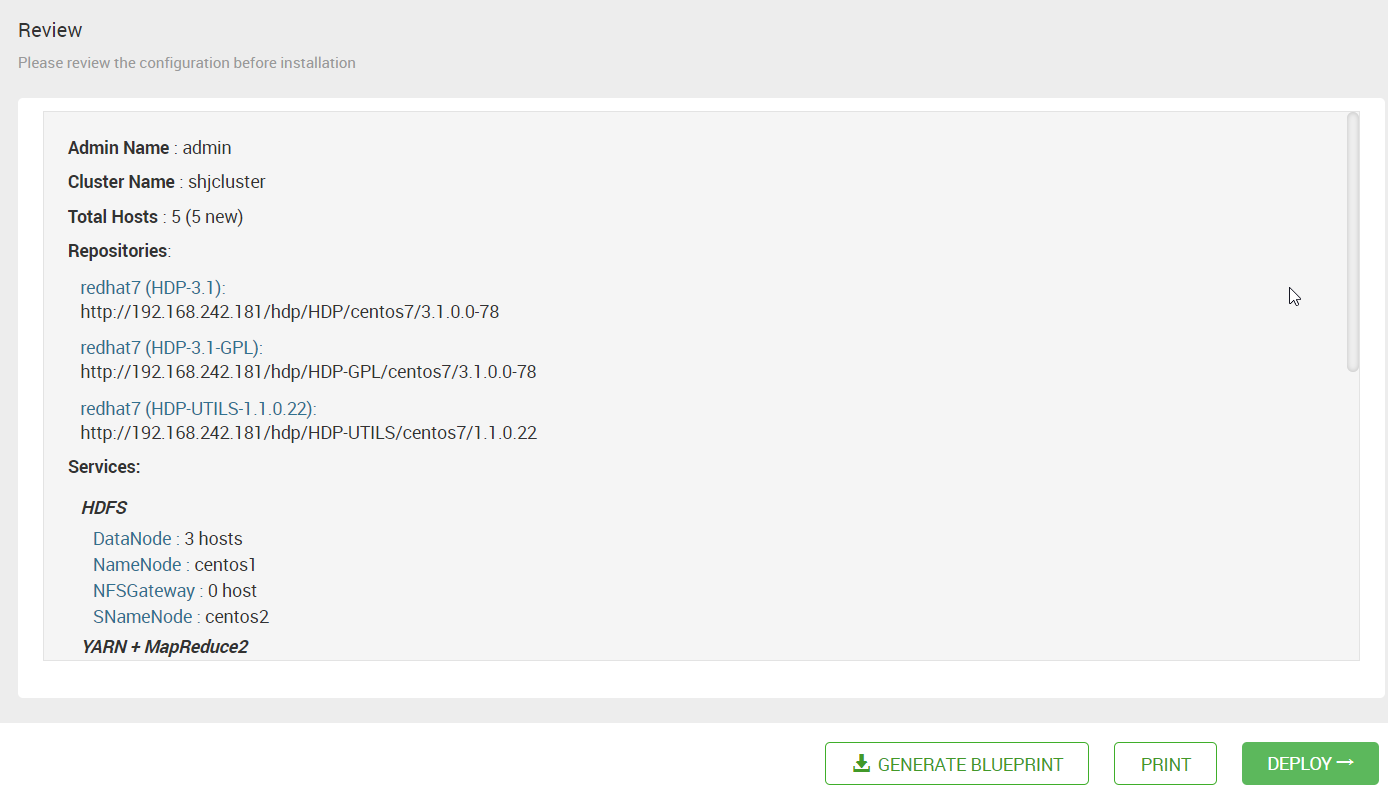
16. 点击 “Next”后,出现总结页。可以下载创建这个集群的元数据信息。点击 “DEPLOY” 后,就开始部署了。
从零开始安装 Ambari (4) -- 通过 Ambari 部署 hadoop 集群的更多相关文章
- 阿里云ECS服务器部署HADOOP集群(六):Flume 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(七):Sqoop 安装
本篇将在 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper) 阿 ...
- 阿里云ECS服务器部署HADOOP集群(五):Pig 安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 1 环境介绍 一台阿里云ECS服务器:master 操作系统:CentOS 7.3 Hadoop ...
- 阿里云ECS服务器部署HADOOP集群(四):Hive本地模式的安装
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建. 本地模式需要采用MySQL数据库存储数据. 1 环境介绍 一台阿里云ECS服务器:master ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- AMBARI部署HADOOP集群(4)
通过 Ambari 部署 hadoop 集群 1. 打开 http://192.168.242.181:8080 登陆的用户名/密码是 : admin/admin 2. 点击 “LAUNCH INS ...
- ambari部署Hadoop集群(2)
准备本地 repository 1. 下载下面的包 wget http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.7.3 ...
- Docker部署Hadoop集群
Docker部署Hadoop集群 2016-09-27 杜亦舒 前几天写了文章"Hadoop 集群搭建"之后,一个朋友留言说希望介绍下如何使用Docker部署,这个建议很好,Doc ...
- 实战CentOS系统部署Hadoop集群服务
导读 Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高 ...
随机推荐
- 三种web性能压力测试工具
三种web性能压力测试工具http_load webbench ab小结 题记:压力和性能测试工具很多,下文讨论的是我觉得比较容易上手,用的比较多的三种 http_load 下载地址:http://w ...
- SUSE eth0 No such device
删除 etc/udev/rules.d/70-persistent-net.rules 文件 之后重启让系统重新生成eth0配置文件 rm -f etc/udev/rules.d/70-persis ...
- HADOOP HDFS BALANCER介绍及经验总结(转)
1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决? 2.尽量不在NameNode上执行start-balancer.sh的原因是什么? 集群平衡介绍 Hadoop的HDFS集群非常 ...
- 使用JSONObject类来生成json格式的数据
JSONObject类不支持javabean转json 生成json格式数据的方式有: 1.使用JSONObject原生的来生成 2.使用map构建json格式的数据 3.使用javabean来构建j ...
- java 类中 static 的使用
在类中 static 主要修饰变量,方法及代码块.大致的执行和使用,据个人理解如下: 1.修饰变量: 在修饰变量时,如 ,表示该变量是静态变量,也可称为类变量.当当前变量是静态变量时,该变量被该类的所 ...
- [codeforces126B]Password
解题关键:KMP算法中NEXT数组的理解. #include<bits/stdc++.h> #define maxn 1000006 using namespace std; typede ...
- Nginx --Windows下和Linux下搭建集群小记
nginx: Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器 特点: 反向代理 负载均衡 动静分离... 反向代理 : 先来了解正向代理:需要我们用户 ...
- 多线程 wait(),notify()方法,案例总结
废话不多说,案例如下 package com.xujingyang.Exok; /** * 商品类 * @author 徐景洋 */ public class Goods { private Stri ...
- Codeforces 58E Expression (搜索)
题意:给你一个可能不正确的算式a + b = c, 你可以在a,b,c中随意添加数字.输出一个添加数字最少的新等式x + y = z; 题目链接 思路:来源于这片博客:https://www.cnb ...
- opencv生成灰度图并保存
#include <opencv2/opencv.hpp>#include <iostream> using namespace cv;using namespace std; ...