SQL Server创建复合索引时,复合索引列顺序对查询的性能影响
说说复合索引
写索引的博客太多了,一直不想动手写,有一下两个原因:
一是觉得有炒剩饭的嫌疑,有兄弟曾说:索引吗,只要在查询条件上建索引就行了,真的可以这么暴力吗?
二来觉得,索引是个非常大的话题,很难概括出所有的情况,你不整出点新意来,倒是有抄袭照搬的嫌疑
既然写了,就写一点稍微不一样的东西出来,
好了,废话打住,开搞
搭建测试环境:
创建一张表,模拟实际业务中的一个表,往里面填入数据,
时间字段上,相对按照时间均匀地填充,其他字段以GUID填充

Create table BusinessInfoTable
(
BuniessCode1 varchar(50),
BuniessCode2 varchar(50),
BuniessCode3 varchar(50),
BuniessCode4 varchar(50),
BuniessStatus1 tinyint,
BuniessStatus2 tinyint,
BuniessDateTime1 Datetime,
BuniessDateTime2 Datetime,
OtherColumn1 varchar(50),
OtherColumn2 varchar(50),
OtherColumn3 varchar(50)
) declare @i int=0
while @i<1000000
begin
insert into BusinessInfoTable
values
(
NEWID(),NEWID(),NEWID(),NEWID(),RAND()*100,RAND()*100,
DATEADD(MI,@i,GETDATE()),DATEADD(MI,@i,GETDATE()),NEWID(),NEWID(),NEWID()
)
set @i=@i+1
end
现在有这么一个查询(实际上查询远比这个复杂,我简化一点,不要说我刻意造环境)
select OtherColumn2,
BuniessStatus1,
BuniessStatus2,
BuniessDateTime1,
BuniessDateTime2
from BusinessInfoTable
where BuniessDateTime1 between '2016-6-21' and '2016-6-28'
and BuniessDateTime2 between '2016-6-21' and '2016-6-28'
and BuniessStatus1 = 55
and BuniessStatus2 = 66
郑重的说明一点:
暂时不考虑聚集索引,毕竟一个表上只能有一个聚集索引,
别人也不是傻子,不会轻易去建聚集索引,聚集索引早被占用了
既然被占用了,我的原则是一般不去动别人现有的东西的,比如别人建了聚集索引,你给人家删了,根据自己的情况建聚集索引
这不是找骂么
有经验的你一定考虑符合索引了,同时考虑到为避免Key Lookup导致的书签查找,我们把查询索要的OtherColumn2列include进来
比如这样
CREATE NONCLUSTERED INDEX IDX_1 ON BusinessInfoTable
(BuniessStatus1,BuniessStatus2,BuniessDateTime1,BuniessDateTime2)
INCLUDE(OtherColumn2)
或者这样,只是索引列顺序不一样
CREATE NONCLUSTERED INDEX IDX_1 ON BusinessInfoTable
(BuniessDateTime1,BuniessDateTime2,BuniessStatus1,BuniessStatus2)
INCLUDE(OtherColumn2)
当然可以随意调整四个列的顺序,我就不过多地做演示了,有兴趣的自己试
这里的前导列的顺序并不会影响到索引的使用,查询的时候都是非聚集索引Seek,绝对的
那么问题来了,完全一样的查询条件,结果一样,使用不同的索引,索引的区别仅仅是列顺序不一样,其代价一样吗,先猜测一下,有区别吗?
同样查询,使用不同索引的结果(分别是上面的IDX_1和IDX_2):
下面看图说话
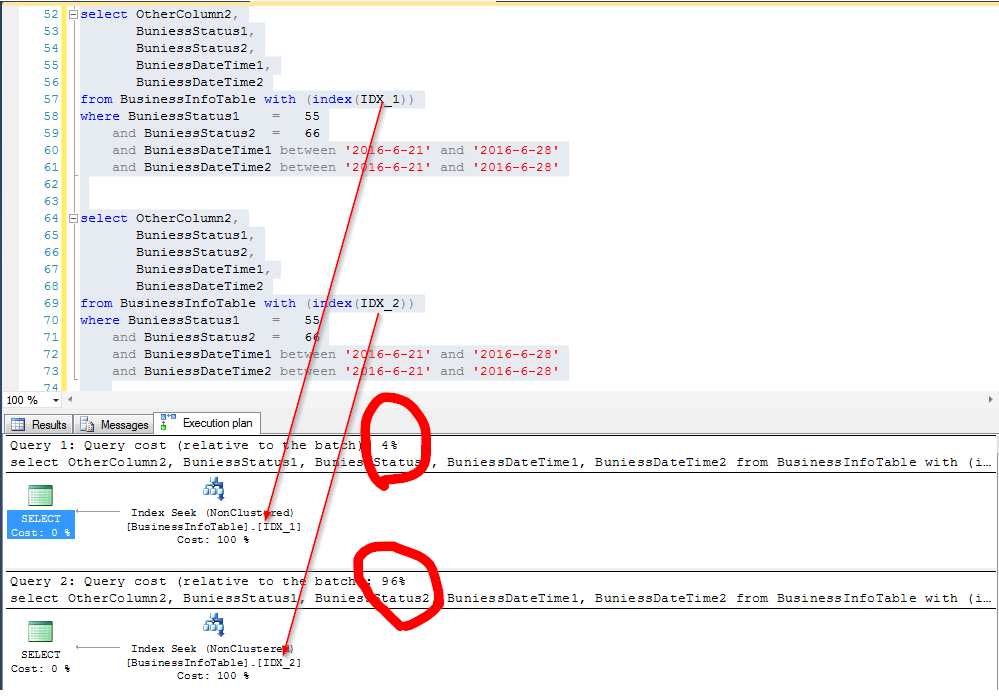
看看IO情况
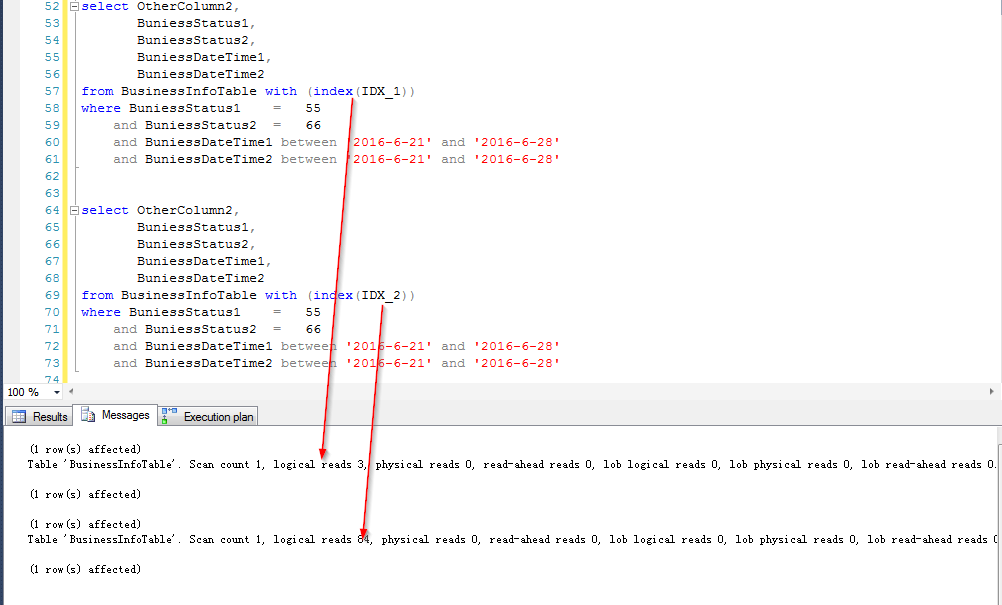
原因分析
看来是有点差别吧,好似乎这个差别还真不小(以往写文章,我测试环境弄不好,对比出来的效果不明显,感觉没啥说服力,这次对比还是比较明显的)
究竟原因在何?
索引是以平衡树(B树)的方式存在的,复合索引的列的顺序决定了B树的信息的存储的顺序
如果是以BuniessStatus1列为前导列,因为BuniessStatus1分布的范围(相对)较小,
这样在查询的时候通过BuniessStatus1=55就可以过滤出来一个比较小的结果集,后面依次用其他条件过滤就相对较快了
比如BuniessStatus1=55过滤出来符合条件的数据有5条,
加上BuniessStatus2 BuniessDateTime1 BuniessDateTime2 这三个条件再过滤,出来一条数据。
如果BuniessDateTime1 是索引的前导列,用BuniessDateTime1 between '2016-6-21' and '2016-6-28'过滤
可能会有10000条数据,然后依次再用 BuniessDateTime2,BuniessStatus1, BuniessStatus2过滤
最后也只有一条符合条件的数据。
差别就在于:一开始的过滤条件,决定了查询多少page初步确定满足条件的数据,再进一步的进行过滤
如果最开始就相对精确地确定了满足查询条件的数据范围,后面可以通过相对较小的代价来最终确认出满足条件的数据
如果最开始相对模糊地却确定了满足查询条件的数据范围,那么这个过程的代价就相对比较大,虽然后面通过每一个条件的过,结果是一样的
当然这种索引的建立跟数据分布有关,
但是,我没有下结论说,复合索引一定要按照什么什么顺序来是最好的
还是那句话:具体问题具体分析,避免经验主义,没有一刀切的手段可以解决所有的问题。
SQL Server创建复合索引时,复合索引列顺序对查询的性能影响的更多相关文章
- SQL Server 创建表 添加主键 添加列常用SQL语句
--删除主键 alter table 表名 drop constraint 主键名 --添加主键 alter table 表名 add constraint 主键名 primary key(字段名1, ...
- SQL Server 创建表 添加主键 添加列常用SQL语句【转】
--删除主键alter table 表名 drop constraint 主键名--添加主键alter table 表名 add constraint 主键名 primary key(字段名1,字段名 ...
- SQL Server创建表超出行最大限制解决方法
问题的现象在创建表A的时候,出现“信息 511,级别 16,状态 1,第 5 行 无法创建大小为 的行,该值大于允许的最大值 8060.”的信息提示.很奇怪,网上查了一下,是因为要插入表的数据类型的 ...
- SQL Server 创建索引方法
转自 <SQL Server 创建索引的 5 种方法> 地址:https://www.cnblogs.com/JiangLe/p/4007091.html 前期准备: create tab ...
- SQL Server创建索引
原文:SQL Server创建索引 什么是索引 拿汉语字典的目录页(索引)打比方:正如汉语字典中的汉字按页存放一样,SQL Server中的数据记录也是按页存放的,每页容量一般为4K .为了加快查找的 ...
- SQL Server 2005 中的分区表和索引
SQL Server 2005 中的分区表和索引 SQL Server 2005 69(共 83)对本文的评价是有帮助 - 评价此主题 发布日期 : 3/24/2005 | 更新 ...
- SQL Server调优系列基础篇 - 索引运算总结
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server 调优系列基础篇 - 索引运算总结
前言 上几篇文章我们介绍了如何查看查询计划.常用运算符的介绍.并行运算的方式,有兴趣的可以点击查看. 本篇将分析在SQL Server中,如何利用先有索引项进行查询性能优化,通过了解这些索引项的应用方 ...
- SQL Server的唯一键和唯一索引会将空值(NULL)也算作重复值
我们先在SQL Server数据库中,建立一张Students表: CREATE TABLE [dbo].[Students]( ,) NOT NULL, ) NULL, ) NULL, [Age] ...
随机推荐
- pod install后无反应
参考这篇文章 http://akinliu.github.io/2014/05/03/cocoapods-specs-/
- Salesforce 使用Js 调用Webservice实例
1,创建 Custom Button 在页面上 2, 创建CustomJs 代码调用Webservice <!--参数名区分大小写,对于跨层object直接在Object名后直接加参字段名即可- ...
- border:none;与border:0;的区别
border:none表示边框样式无,border:0表示边框宽度为0;当定义了border:none,即隐藏了边框的显示,实际就是边框宽度为0. 当定义边框时,必须定义边框的显示样式.因为边框默认样 ...
- Nginx配置文件(nginx.conf)配置详解(2)
Nginx的配置文件nginx.conf配置详解如下: user nginx nginx ; Nginx用户及组:用户 组.window下不指定 worker_processes 8; 工作进程:数目 ...
- Asp.net 未处理异常
页面级捕获未处理异常 - Page 的 Error 事件 Protected Sub Page_Error(ByVal sender As Object, ByVal e As System.Even ...
- btrfs-snapper 实现Linux 文件系统快照回滚
###btrfs-snapper 应用 ----------####环境介绍> btrfs文件系统是从ext4过渡而来的被誉为“下一代的文件系统”.该文件系统具有高扩展性(B-tree).数据一 ...
- C语言中如何产生随机数
今天看到一段小程序 ,里面用到随机数.才发现在C语言中产生随机数不像matlab中那么简单. C中也有rand()函数,但是rand()函数产生的数不是真正意义上的随机数,是一个伪随机数,是根据一个数 ...
- Linux Shell ---系统命令(1)
date命令 功能说明:显示或设置系统时间与日期. 语 法: date [-d <字符串>][-u][+%H%I%K%l%M%P%r%s%S%T%X%Z%a%A%b%B%c%d%D%j%m ...
- LB负载均衡层次结构(摘抄)
作为后端应用的开发者,我们经常开发.调试.测试完我们的应用并发布到生产环境,用户就可以直接访问到我们的应用了.但对于互联网应用,在你的应用和用户之间还隔着一层低调的或厚或薄的负载均衡层软件,它们不显山 ...
- 使用Spring Data JPA查询时,报result returns more than one elements异常
public static <T> T get(String hql, Class<T> t) { EntityManager em = getFactory().create ...