由定时脚本错误以及Elasticsearch配置错误引发的Flink线上事故
近期接手离职同事项目,突然遇到线上事故,Flink无法正常聚合数据生成指标.
以下是详细的排查过程:
问题复现
清晨,运维报告Flink数据分析模块无法正常生成指标数据.
赶紧登陆Flink所在机器,使用如下语句简单查看Job状态.
./bin/flink list
查看输出,发现故障Job在Running状态.
因为数据分析模块运行时间较久,近期没有更新过,因此怀疑是依赖的中间件问题.
问题根源定位
(1) 查看数据源
数据分析模块依赖于Kafka,因此登陆Kafka所在机器,查看相应topic的消费情况.
./bin/kafka-consumer-groups.sh --describe --bootstrap-server 192.*.*.*:9092 --group data_prod_consumer
得到结果如下所示:
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
qq_data 0 340155122 340155407 285 - - -
多次运行命令(间隔一段时间),发现LOG-END-OFFSET的增长速度远大于CURRENT-OFFSET,导致LAG指标不断上升,最高时达到17000.
让同事紧急修改日志输出,屏蔽非核心业务的日志,然而作用不大,LAG仍然在缓慢的持续增长.
LOG-END-OFFSET意为当前最新数据偏移量,CURRENT-OFFSET意为当前消费者消费的偏移量,LAG为LOG-END-OFFSET与CURRENT-OFFSET之间的差值.
通过LAG数值,可以观察到topic的消费情况,从而确定是否有数据积累.
观察flink机器负载,发现负载较低,消费瓶颈不应该是Flink.
(2) 查看数据输出
数据分析模块的Sink是Elasticsearch(单节点运行),因此查看ES的运行状况.
curl 'localhost:9200/_cat/indices?v'
查数据分析模块输出的数据库,发现数据库大小正常,感觉疑惑.
使用top查看机器的负载信息,大吃一惊:
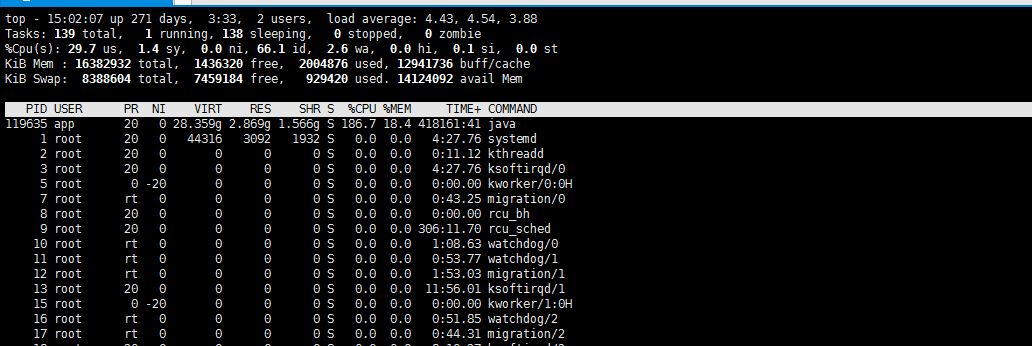
由上图可知,ES应用的虚拟内存(VIRY)占用高达28G,此外,机器的load average高达4.43.
基本上,可以确定是Elasticsearch异常引发数据分析模块运行异常.
重新查看ES索引信息,发现有四个Type数据量不对(非相关业务数据表),其中一张表的数据量多达2800万条(此业务有过了解).
询问离职同事,经过询问大致可确定这四张表的数据量不对,此表数据未设置TTL,而是依赖于数据库定时删除脚本完成过期数据删除操作.
(3) 确定问题
查看数据库定期删除脚本执行日志,发现脚本在较长的一段时间内未能正常运行.
原因是脚本在这执行删除操作时,未根据业务的变更而修改脚本,导致在删除已废弃表中数据时出现异常而终止运行.
因为当前故障业务的数据库删除命令在异常前,故当前业务的数据量维持在正常的水平线上.
ps -ef|grep elasticsearch
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -XX:+HeapDumpOnOutOfMemoryError -Des.path.home=/home/app/elasticsearch-6.1.2 -Des.path.conf=/home/app/elasticsearch-6.1.2/config -cp /home/app/elasticsearch-6.1.2/lib/* org.elasticsearch.bootstrap.Elasticsearch -d
此外,查看Elasticsearch的运行信息时,发现其配置明显存在不足,Xms分配为1G,Xmx分配为1G.
然而当前机器仅运行Elasticsearch,因此暂停依赖于Elasticsearch的相应业务,调整配置信息,重新启动.
ps -ef|grep elasticsearch
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre/bin/java -Xms8g -Xmx8g -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+ParallelRefProcEnabled -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -XX:+HeapDumpOnOutOfMemoryError -Des.path.home=/home/app/elasticsearch-6.1.2 -Des.path.conf=/home/app/elasticsearch-6.1.2/config -cp /home/app/elasticsearch-6.1.2/lib/* org.elasticsearch.bootstrap.Elasticsearch -d
修改后,Xms以及Xmx响应调整为8G,按照Elasticsearch推荐配置,保留8G内存供系统使用.
此外,临时修改数据库脚本并执行,删除各表中的过期数据.
curl -XPOST "http://localhost:9200/data/_delete_by_query?conflicts=proceed" --header 'Content-Type:application/json' -d @delete_data_condition.txt
使用上述语句删除过期数据,删除条件置于delete_data_condition.txt文件中.
需要注意,因为Elasticsearch版本控制的原因,容易导致数据删除失败,因此添加conflicts=proceed条件解决版本冲突导致的数据删除失败.
问题解决
经过上述操作后,发现Elasticsearch数据库的负载明显下降,观察Topic的消费情况,发现LAG指标在快速回落.
待观察一段时间后,发现数据分析模块能够正常聚合,业务恢复正常.
不过还是留下了问题,就是因为Elasticsearch导致Flink消费Kafka数据过慢,出现了重复读进一步拖慢聚合速度,这个问题需要后续深入研究解决.
这就是一个删除脚本异常引起的血案,中间件虽然带来了极大的便利,但是也提升了问题排查的难度.
因此,不仅要知道中间件怎样部署,更要学会如何部署更优,为业务的正常运行奠定基础.
PS:
如果您觉得我的文章对您有帮助,请关注我的微信公众号,谢谢!

由定时脚本错误以及Elasticsearch配置错误引发的Flink线上事故的更多相关文章
- Druid连接池参数maxWait配置错误引发的问题
Druid连接池参数maxWait配置错误引发的问题 1. 背景 数据库服务器(服务部署在客户内网环境)的运行一段时间后,网卡出现了问题,导致所有服务都连接不上数据库,客户把网络恢复之后,反馈有个服务 ...
- Vue 2.x 3.x 配置项目开发环境跟线上环境
先找到package.json (这是nuxt版的vue 可能会跟一般vue不一样 当然总体上差不多的) "scripts": { "dev": " ...
- 记一次真实的线上事故:一个update引发的惨案!
目录 前言 项目背景介绍 要命的update 结语 前言 从事互联网开发这几年,参与了许多项目的架构分析,数据库设计,改过的bug不计其数,写过的sql数以万计,从未出现重大纰漏,但常在河边走,哪 ...
- Elasticsearch常见错误与配置简介
一.常见错误 1.1 root用户启动elasticsearch报错 Elasticsearch为了安全考虑,不让使用root启动,解决方法新建一个用户,用此用户进行相关的操作.如果你用root启动, ...
- java dump 内存分析 elasticsearch Bulk异常引发的Elasticsearch内存泄漏
Bulk异常引发的Elasticsearch内存泄漏 2018年8月24日更新: 今天放出的6.4版修复了这个问题. 前天公司度假部门一个线上ElasticSearch集群发出报警,有Data Nod ...
- elasticsearch配置详解
一.说明 使用的是新版本5.1,直接从官网下载rpm包进行安装,https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5 ...
- Spring-boot2.0.1.BUILD-SNAPSHOT整合Elasticsearch报failed to load elasticsearch nodes错误解决办法
spring-boot整合es的application.properties的默认配置为: spring.data.elasticsearch.cluster-nodes=localhost:9200 ...
- elasticsearch启动错误整理
一.elasticsearch错误复现 (一).环境 配置环境 OS:CentOS 7.4 64bit elasticsearch版本: - ip:10.18.43.170 java版本:java - ...
- Tomcat启动报错org.springframework.web.context.ContextLoaderListener类配置错误——SHH框架
SHH框架工程,Tomcat启动报错org.springframework.web.context.ContextLoaderListener类配置错误 1.查看配置文件web.xml中是否配置.or ...
随机推荐
- 如何搭建node - express 项目
基于博主也是个菜鸟,亲身体验后步骤如下: 首先,我们需要安装node.js, https://www.runoob.com/nodejs/nodejs-install-setup.html 安装完成 ...
- 中间人攻击,HTTPS也可以被碾压
摘要: 当年12306竟然要自己安装证书... 原文:知道所有道理,真的可以为所欲为 公众号:可乐 Fundebug经授权转载,版权归原作者所有. 一.什么是MITM 中间人攻击(man-in-the ...
- SQL Server要拷贝默认目录下的使用数据库需要停止的服务
- mssql 系统函数 字符串函数 space 功能简介
转自: http://www.maomao365.com/?p=4672 一.space 函数功能简介 space功能:返回指定数量的空格参数简介: 参数1: 指定数量,参数需为int类型 注意事项 ...
- 1. Linux-3.14.12内存管理笔记【系统启动阶段的memblock算法(1)】
memblock算法是linux内核初始化阶段的一个内存分配器(它取代了原来的bootmem算法),实现较为简单.负责page allocator初始化之前的内存管理和分配请求. 分析memblock ...
- Octave中的矩阵常用操作2
sum(a):矩阵里的数据求和prod(a):乘积floor(a):向上取整ceil(a):向下取整max(A,[],1):取每一列的最大值max(A,[],2):取每一行的最大值max(max(A) ...
- Docker组成三要素
目录 镜像 容器 仓库 总结 Docker的基本组成三要素 镜像 容器 仓库 镜像 Docker 镜像(Image)就是一个只读的模板.镜像可以用来创建 Docker 容器,一个镜像可以创建很多容器. ...
- Python迭代器的用法,next()方法的调用
迭代器的用法: 首先说两个概念,一个是可迭代的对象,一个是迭代器对象,两个不同 可迭代的(Iterable):就是可以for循环取数据的,比如字典.列表.元组.字符串等,不可使用next()方法. 迭 ...
- misc-适合作为桌面
今年黑盾杯的misc之一,居然是两年前的世安杯原题 神器stegsolve获得二维码 用QR-Research获得一段十六进制 用winhex填充数据 ascll->hex(之前只做到这里,看 ...
- AcWing 13. 找出数组中重复的数字
习题地址 https://www.acwing.com/solution/acwing/content/2919/. 题目描述给定一个长度为 n 的整数数组 nums,数组中所有的数字都在 0∼n−1 ...