SparkSql 整合 Hive
SparkSql整合Hive
需要Hive的元数据,hive的元数据存储在Mysql里,sparkSql替换了yarn,不需要启动yarn,需要启动hdfs
首先你得有hive,然后你得有spark,如果是高可用hadoop还得有zookeeper,还得有dfs(hadoop中的)
我这里有3台节点node01,node02,node03
ps:DATEDIFF(A,B)做差集
node01
先copy hive的hive-site.xml到spark 的config
cp hive-site.xml /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /export/servers/spark-2.0.2/conf/
然后在spark config目录scp到其它节点
scp hive-site.xml node02:$PWD
scp hive-site.xml node03:$PWD

拷贝mysql驱动包到spark jars目录(之前装hive因为Hive要把元数据存在mysql中,所以我之前将Mysql驱动包copy至hive/lib下)
cp /export/servers/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.38.jar /export/servers/spark-2.0.2/jars/
将mysql驱动拷贝至其他节点spark目录下
首先进入到spark/jars目录
cd /export/servers/spark-2.0.2/jars/
拷贝(我配了免密登录,并且有主机名映射ip)
scp mysql-connector-java-5.1.38.jar node02:$PWD
scp mysql-connector-java-5.1.38.jar node03:$PWD

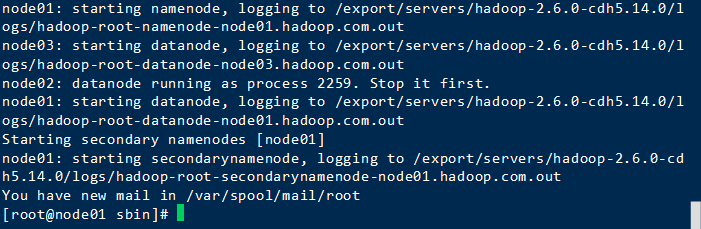
因为待会要在hdfs的文件中测试,所以需要启动dfs,不启动yarn
进入hadoop/sbin目录后,启动
./start-dfs.sh
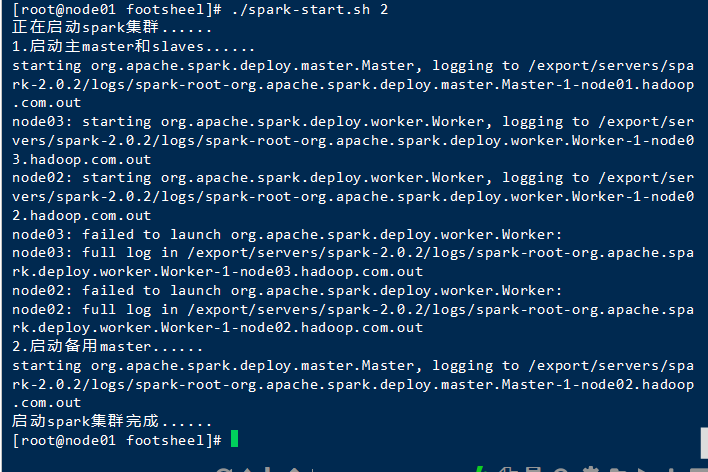
启动spark集群(我把他们封装到了一个脚本里=>如果需要,请点击我下载待定)
脚本启动
./spark-start.sh 2
测试
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
失败了

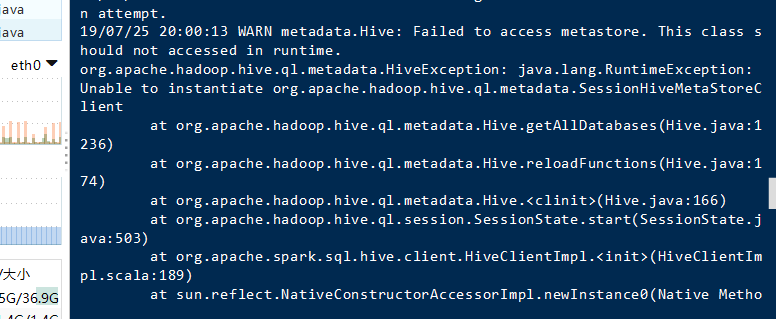
这行代码错误的原因是,因为之前我和impala整合过,但是我未启动impala。
解决方案
进入node01
hive/conf下打开hive-site.xml
注释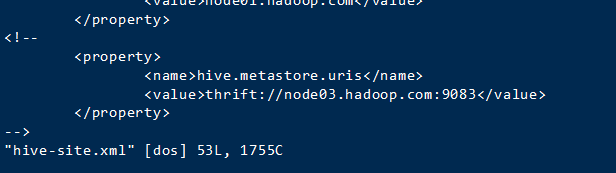
重新启动
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
成功
SparkSql 整合 Hive的更多相关文章
- Spark之 SparkSql整合hive
整合: 1,需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置. 2,如果Hive的元数据存放在Mysql中,我们还需 ...
- 3.sparkSQL整合Hive
spark SQL经常需要访问Hive metastore,Spark SQL可以通过Hive metastore获取Hive表的元数据.从Spark 1.4.0开始,Spark SQL只需简单的配置 ...
- 【Spark】帮你搞明白怎么通过SparkSQL整合Hive
文章目录 一.创建maven工程,导包 二.开发代码 一.创建maven工程,导包 <properties> <scala.version>2.11.8</scala.v ...
- Hive环境搭建和SparkSql整合
一.搭建准备环境 在搭建Hive和SparkSql进行整合之前,首先需要搭建完成HDFS和Spark相关环境 这里使用Hive和Spark进行整合的目的主要是: 1.使用Hive对SparkSql中产 ...
- 关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0 hive版本:1.2.1 需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spar ...
- Spark整合Hive
spark-sql 写代码方式 1.idea里面将代码编写好打包上传到集群中运行,上线使用 spark-submit提交 2.spark shell (repl) 里面使用sqlContext 测试使 ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
随机推荐
- 洗牌算法及 random 中 shuffle 方法和 sample 方法浅析
对于算法书买了一本又一本却没一本读完超过 10%,Leetcode 刷题从来没坚持超过 3 天的我来说,算法能力真的是渣渣.但是,今天决定写一篇跟算法有关的文章.起因是读了吴师兄的文章<扫雷与算 ...
- 高强度学习训练第十四天总结:HashMap
HashMap 简介 HashMap 主要用来存放键值对,它基于哈希表的Map接口实现,是常用的Java集合之一. JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap ...
- js相同的正则多次调用test()返回的值却不同
项目中文件上传需要验证文件的格式,第一次正常,第二次就验证不通过了.在验证的地方console.log()两遍,发现结果不一样 !!! 正则和文件名都没变,但是两次的验证结果不同. this.reg ...
- iOS关于制作动画运动轨迹(UIBezierPath介绍)
参考链接: https://www.jianshu.com/p/6c9aa9c5dd68
- MongoDB的模糊查询操作(类关系型数据库的 like 和 not like)
1.作用与语法描述 作用: 正则表达式是使用指定字符串来描述.匹配一系列符合某个句法规则的字符串.许多程序设计语言都支持利用正则表达式进行字符串操作.MongoDB 使用 $regex 操作符来设置匹 ...
- 自己写的一个连数据库的音乐调用模块 MusicRj
#自己定义 class MusicRj: # 创音乐表t_music # sql = '''CREATE TABLE t_music1( # id INT PRIMARY KEY AUTO_INCRE ...
- 初识Kotlin之函数
本章通过介绍Kotlin的基本函数,默认参数函数,参数不定长函数,尾递归函数,高阶函数,Lamdba表达式.来对Kotlin函数做进一步了解.将上一篇的Kotlin变量的知识得以运用.Kotlin变量 ...
- 关于rabbitmq
关于rabbitmq 1 简单介绍rabbitmq RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件).RabbitMQ服务器是用Erlang语言编写的,而 ...
- 基于socketserver实现并发的socket编程
目录 一.基于TCP协议 1.1 server类 1.2 request类 1.3 继承关系 1.4 服务端 1.5 客户端 1.6 客户端1 二.基于UDP协议 2.1 服务端 2.2 客户端 2. ...
- 搭建Jupyter学习环境
`python notebook`是一个基于浏览器的python数据分析工具,使用起来非常方便,具有极强的交互方式和富文本的展示效果.jupyter是它的升级版,它的安装也非常方便,一般`Anacon ...