SparkSql 整合 Hive
SparkSql整合Hive
需要Hive的元数据,hive的元数据存储在Mysql里,sparkSql替换了yarn,不需要启动yarn,需要启动hdfs
首先你得有hive,然后你得有spark,如果是高可用hadoop还得有zookeeper,还得有dfs(hadoop中的)
我这里有3台节点node01,node02,node03
ps:DATEDIFF(A,B)做差集
node01
先copy hive的hive-site.xml到spark 的config
cp hive-site.xml /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /export/servers/spark-2.0.2/conf/
然后在spark config目录scp到其它节点
scp hive-site.xml node02:$PWD
scp hive-site.xml node03:$PWD

拷贝mysql驱动包到spark jars目录(之前装hive因为Hive要把元数据存在mysql中,所以我之前将Mysql驱动包copy至hive/lib下)
cp /export/servers/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.38.jar /export/servers/spark-2.0.2/jars/
将mysql驱动拷贝至其他节点spark目录下
首先进入到spark/jars目录
cd /export/servers/spark-2.0.2/jars/
拷贝(我配了免密登录,并且有主机名映射ip)
scp mysql-connector-java-5.1.38.jar node02:$PWD
scp mysql-connector-java-5.1.38.jar node03:$PWD

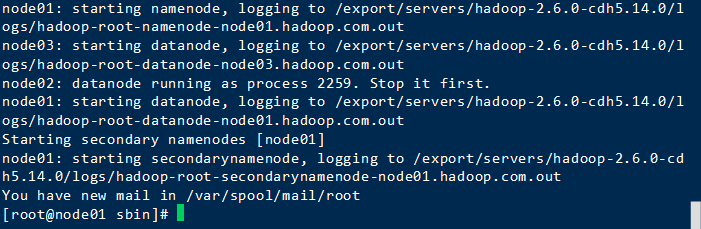
因为待会要在hdfs的文件中测试,所以需要启动dfs,不启动yarn
进入hadoop/sbin目录后,启动
./start-dfs.sh
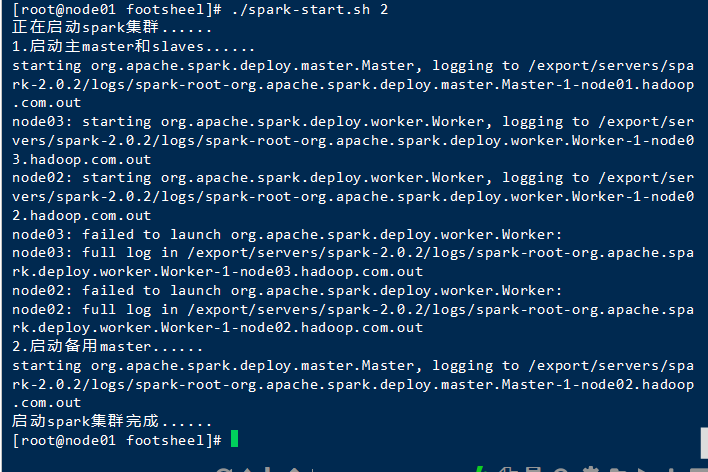
启动spark集群(我把他们封装到了一个脚本里=>如果需要,请点击我下载待定)
脚本启动
./spark-start.sh 2
测试
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
失败了

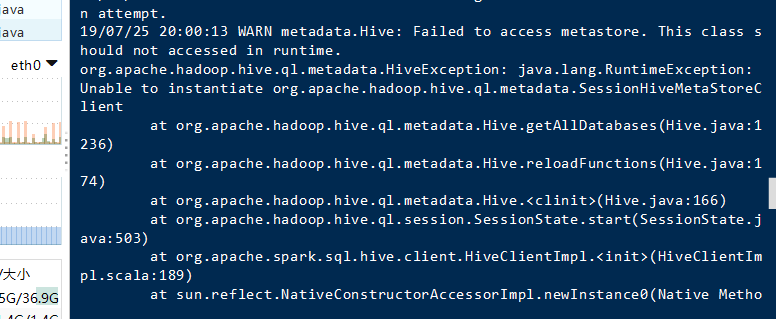
这行代码错误的原因是,因为之前我和impala整合过,但是我未启动impala。
解决方案
进入node01
hive/conf下打开hive-site.xml
注释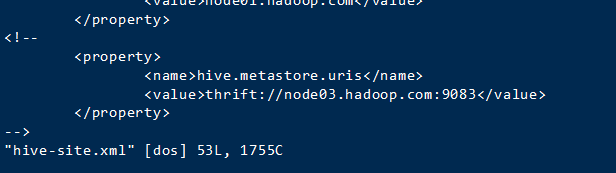
重新启动
spark-sql \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--conf spark.sql.warehouse.dir=hdfs://node01:8020/user/hive/warehouse/myhive.db
成功
SparkSql 整合 Hive的更多相关文章
- Spark之 SparkSql整合hive
整合: 1,需要将hive-site.xml文件拷贝到Spark的conf目录下,这样就可以通过这个配置文件找到Hive的元数据以及数据存放位置. 2,如果Hive的元数据存放在Mysql中,我们还需 ...
- 3.sparkSQL整合Hive
spark SQL经常需要访问Hive metastore,Spark SQL可以通过Hive metastore获取Hive表的元数据.从Spark 1.4.0开始,Spark SQL只需简单的配置 ...
- 【Spark】帮你搞明白怎么通过SparkSQL整合Hive
文章目录 一.创建maven工程,导包 二.开发代码 一.创建maven工程,导包 <properties> <scala.version>2.11.8</scala.v ...
- Hive环境搭建和SparkSql整合
一.搭建准备环境 在搭建Hive和SparkSql进行整合之前,首先需要搭建完成HDFS和Spark相关环境 这里使用Hive和Spark进行整合的目的主要是: 1.使用Hive对SparkSql中产 ...
- 关于sparksql操作hive,读取本地csv文件并以parquet的形式装入hive中
说明:spark版本:2.2.0 hive版本:1.2.1 需求: 有本地csv格式的一个文件,格式为${当天日期}visit.txt,例如20180707visit.txt,现在需要将其通过spar ...
- Spark整合Hive
spark-sql 写代码方式 1.idea里面将代码编写好打包上传到集群中运行,上线使用 spark-submit提交 2.spark shell (repl) 里面使用sqlContext 测试使 ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- SparkSQL与Hive on Spark的比较
简要介绍了SparkSQL与Hive on Spark的区别与联系 一.关于Spark 简介 在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题 ...
随机推荐
- 创建线程之三:实现Callable接口
通过Callable和Future创建线程 i. 创建Callable接口的实现类,并实现call方法,该call方法将作为线程执行体,并且有返回值,可以抛出异常. ii. 创建Callable实现类 ...
- vscode中js文件失去高亮/没有智能提示
vscode中js文件失去高亮/没有智能提示 两步: 第一步:基本的语法高亮提示,需要将vetur删掉,然后把vscode的历史记录缓存删掉,重启vscode. 第二步:js的智能提示,使用插件typ ...
- 转战物联网·基础篇07-深入理解MQTT协议之控制报文(数据包)格式
在MQTT协议中,一个控制报文(数据包)的结构按照前后顺序分如下三部分: 结构名 中文名 解释说明 Fixed header 固定报头 报文的最开始部分,所有报文都包含这个部分 Variable ...
- Violet音乐社区界面原型手册
目录 Violet音乐社区界面原型手册 一.引言 1.0 项目前阶段相关文档 1.1 编写目的 1.2 开发背景 二.界面原型展示 2.0 界面设计说明 2.1 首页 2.2 歌单/专辑/单曲界面 2 ...
- PyCharm批量修改变量名
方法和 PyCharm重命名文件时更改引用的地方相同
- [apue] syslog 导致 accept 出错?
前几天在看apue第16章关于socket的例子,就是一个非常典型的socket服务器,关键代码如下: void serve (int sockfd) { int ret; int clfd; int ...
- go设计模式--单例singleton
创建型第一个,使用TDD作的. singleton.go package singleton type Singleton interface { AddOne() int } type single ...
- 四、排序算法总结二(归并排序)(C++版本)
一.什么是归并排序? 归并排序是基于分而治之的思想建立起来的. 所谓的分而治之,也就是将一个数据规模为N的数据集,分解为两个规模大小差不多的数据集(n/2),然而分别处理这两个更小的问题,就相当于解决 ...
- 11.web5
先补充点小知识: 关于jjencode 和 aaencode(颜文字) 1.什么是jjencode? 将JS代码转换成只有符号的字符串 2.什么是aaencode? 将JS代码转换成常用的网络表情 ...
- 80%应聘者都不及格的JS面试题
共 5024 字,读完需 6 分钟,速读需 2 分钟,本文首发于知乎专栏前端周刊.写在前面,笔者在做面试官这 2 年多的时间内,面试了数百个前端工程师,惊讶的发现,超过 80% 的候选人对下面这道题的 ...