python_机器学习_最临近规则分类(K-Nearest Neighbor)KNN算法
1. 概念:
https://scikit-learn.org/stable/modules/neighbors.html
1. Cover和Hart在1968年提出了最初的临近算法
2. 分类算法(classification)
3. 输入基于实例的学习(instance-based leaning)。懒惰学习(lazy learning)
开始时候不广泛建立模型,在归类的时候才分类
2. 例子:
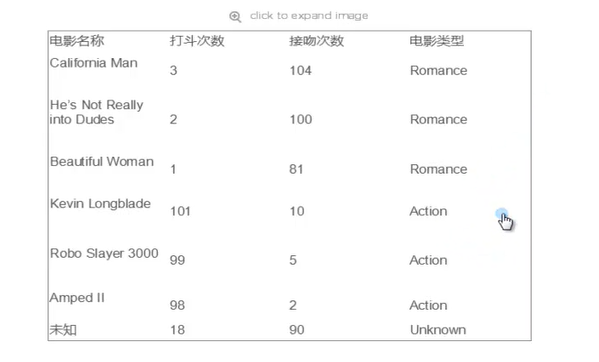
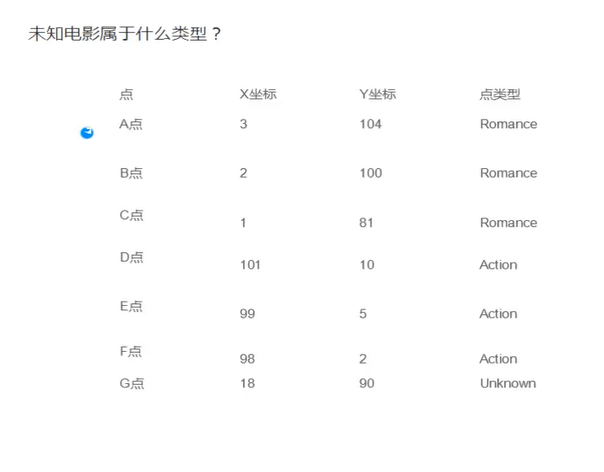
3. 算法详述

1. 步骤:
为了判断未知实例的类别,以所有已知类别的实例作为参照
选择参数K
计算未知实例与所有已知实例的距离
选择最近K个已知实例 ---》 通常是奇数,更好的选择
根据少数服从多数的投票法则, 让未知实例归类为K个最邻近样本肿最多数的类别
2. 细节:
关于K
关于距离的衡量方法:
1). Euclidean Distance定义


3. 举例:


4. 算法优缺点
1. 算法优点:
简单
易于理解
容易实现
通过对K的选择可具备丢噪音数据的健壮性
2. 算法缺点

需要大量空间存储所有已知实例
算法复杂度高(需要比较所有已知实例与要分类的实例)
比如Y那个点属于不平衡,属于短板
当其样本分布不平衡时, 比如其中一类样本过大(实例数量过多)占主导的时候, 新的未知实例容易被分类为这个主导样本, 因为这类样本实例的数量过大,但这个新的
未知实例并没有接近目标样本
5. 改进版本
考虑距离, 根据距离增加权重
比如1/d(d:距离)
6. 应用
虹膜花数据集介绍

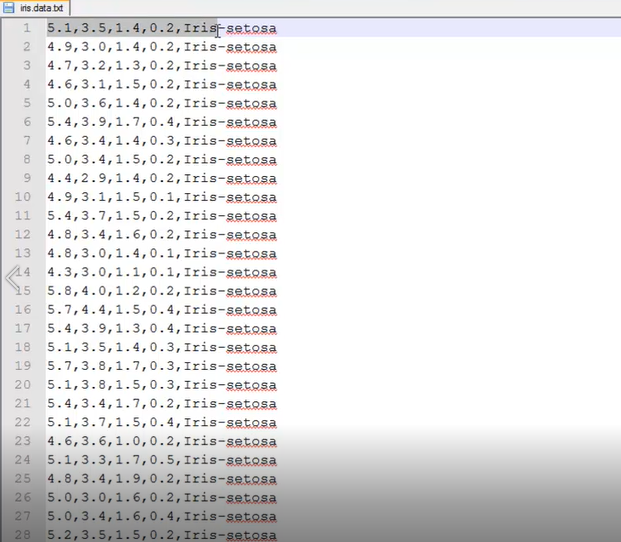
python3.6.3
# -*- coding:utf-8 -*- from sklearn import neighbors
from sklearn import datasets knn = neighbors.KNeighborsClassifier()
# 返回一个数据库 iris ---> 默认的参数
# 'filename': 'C:\\python3.6.3\\lib\\site-packages\\sklearn\\datasets\\data\\iris.csv'
iris = datasets.load_iris() print(iris) # 模型建立
# data为特征值
# target 为向量,每一行对应的分类,一维的模型
knn.fit(iris.data, iris.target)
# 预测
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
print("===========================\n\n\n\n\n\n\n")
# [0] 属于第一类花的名字
# 'target_names': array(['setosa', 'versicolor', 'virginica']
print(predictedLabel)
模拟过程自己封装--》不是我写的,是我抄的--》代码也没测试
# -*- coding:utf-8 -*- import csv
import random
import math
import operator def loadDataset(filename, split, trainingSet=[], testSet=[]):
with open(filename, 'rb') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset) -1 ):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x]) def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance) def getNeighbors(trainingSet, testInstance, k):
distance = []
length = len(testInstance) -1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distance.append((trainingSet[x], dist))
distance.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distance[x][0])
return neighbors def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0] def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet))) * 100.0 def main():
trainingSet = []
testSet = [] split = 0.57
loadDataset(r"...", split, trainingSet) print "Train set: " + repr(len(trainingSet))
print "Train set: " + repr(len(testSet)) predictions = []
k = 3
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print("> predicted= " + repr(result) + ', actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print("Accuracy: " + repr(accuracy) + "%") main()
python_机器学习_最临近规则分类(K-Nearest Neighbor)KNN算法的更多相关文章
- K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KN ...
- K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法和K-M ...
- python_机器学习_监督学习模型_决策树
决策树模型练习:https://www.kaggle.com/c/GiveMeSomeCredit/overview 1. 监督学习--分类 机器学习肿分类和预测算法的评估: a. 准确率 b.速度 ...
- 最邻近规则分类(K-Nearest Neighbor)KNN算法
自写代码: # Author Chenglong Qian from numpy import * #科学计算模块 import operator #运算符模块 def createDaraSet( ...
- 4.2 最邻近规则分类(K-Nearest Neighbor)KNN算法应用
1 数据集介绍: 虹膜 150个实例 萼片长度,萼片宽度,花瓣长度,花瓣宽度 (sepal length, sepal width, petal length and petal wi ...
- K nearest neighbor cs229
vectorized code 带来的好处. import numpy as np from sklearn.datasets import fetch_mldata import time impo ...
- K-Means和K Nearest Neighbor
来自酷壳: http://coolshell.cn/articles/7779.html http://coolshell.cn/articles/8052.html
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 机器学习实战(笔记)------------KNN算法
1.KNN算法 KNN算法即K-临近算法,采用测量不同特征值之间的距离的方法进行分类. 以二维情况举例: 假设一条样本含有两个特征.将这两种特征进行数值化,我们就可以假设这两种特种分别 ...
随机推荐
- 数据分析三剑客 numpy,oandas,matplotlib
数据分析: 是不把隐藏在看似杂乱无章的数据域背后的信息提炼出来,总结出所研究对象内在规律 NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩 ...
- JS高阶---线程与事件机制(小结)
[大纲] [主体] 注意:先进先出 事件轮询: 事件初始化代码执行完毕后,开始执行事件队列里的待处理事件 .
- 用Python打印九九乘法表与金字塔(*)星号
''' 1*1=1 2*1=2 2*2=4 3*1=3 3*2=6 3*3=9 4*1=4 4*2=8 4*3=12 4*4=16 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 ...
- (Apache服务)个人用户主页功能
1.开启个人用户主页功能 (1)输入命令“vi /etc/httpd/conf.d/userdir.conf” (2)将第17行UserDir disabled前加一个# 将第24行UserDi ...
- 新建全色或者resize(毫无价值,只是做记录)
import glob import os,sys import shutil import numpy as np import cv2 import matplotlib.pyplot as pl ...
- Visual Studio 2015 Tools for Unity使用基础
Unity4.x编辑器侧 具体版本号:Visual Studio 2015 Tools for Unity 3.7.0.1 该插件在:Microsoft Visual Studio Tools for ...
- 洛谷 P1840 【Color the Axis_NOI导刊2011提高(05)】 题解
看了一下题解,显然在做无用功啊,而且麻烦了许多,但是这道题真心不难,显然是一个区间修改的题目,然后查询的题目 我的线段树只需要记录一个量:区间和 看了一下其他题解的pushdown函数,发现真心写的很 ...
- python在字节流中对int24的转换
python在字节流中对int24的转换 概述 最近在写项目的过程中,需要对从串口中读取的数据进行处理,本来用C写完了,但是却一直拿不到正确的数据包,可能是因为自己太菜了.后来用了python重新写了 ...
- CompletableFuture3
public class CompletableFuture3 { public static void main(String[] args) throws ExecutionException, ...
- vue中引入mintui、vux重构简单的APP项目
最近在学习vue时也了解到一些常用的UI组件,有用于PC的和用于移动端的.用于PC的有:Element(饿了么).iView等:用于移动端APP的有Vux.Mint UI(饿了么).Vant(有赞团队 ...