dnn文本分类
简介
- 收集用户query数据。
- 清洗,标记。
- 模型设计。
- 模型学习效果评估。
运行
输入/输出
label text(分词后)
预估样本:
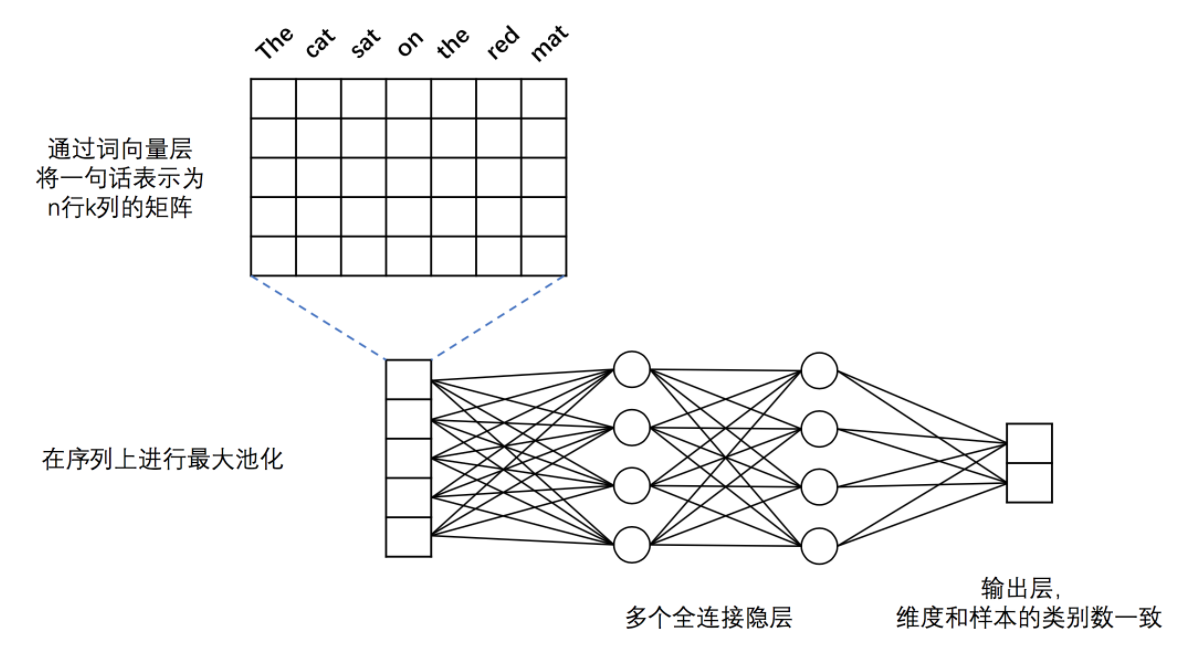
DNN 模型
{kind=link}
- 词向量层:为了更好地表示不同词之间语义上的关系,首先将词语转化为固定维度的向量。训练完成后,词与词语义上的相似程度可以用它们的词向量之间的距离来表示,语义上越相似,距离越近。关于词向量的更多信息请参考PaddleBook中的词向量一节。
- 最大池化层:最大池化在时间序列上进行,池化过程消除了不同语料样本在单词数量多少上的差异,并提炼出词向量中每一下标位置上的最大值。经过池化后,词向量层输出的向量序列被转化为一条固定维度的向量。例如,假设最大池化前向量的序列为[[2,3,5],[7,3,6],[1,4,0]],则最大池化的结果为:[7,4,6]。
- 全连接隐层:经过最大池化后的向量被送入两个连续的隐层,隐层之间为全连接结构。
- 输出层:输出层的神经元数量和样本的类别数一致,例如在二分类问题中,输出层会有2个神经元。通过Softmax激活函数,输出结果是一个归一化的概率分布,和为1,因此第$i$个神经元的输出就可以认为是样本属于第$i$类的预测概率。
源码:
import sys
import math
import gzip from paddle.v2.layer import parse_network
import paddle.v2 as paddle __all__ = ["fc_net", "convolution_net"] def fc_net(dict_dim,
class_num,
emb_dim=,
hidden_layer_sizes=[, ],
is_infer=False):
"""
define the topology of the dnn network
:param dict_dim: size of word dictionary
:type input_dim: int
:params class_num: number of instance class
:type class_num: int
:params emb_dim: embedding vector dimension
:type emb_dim: int
""" # define the input layers
data = paddle.layer.data("word",
paddle.data_type.integer_value_sequence(dict_dim))
if not is_infer:
lbl = paddle.layer.data("label",
paddle.data_type.integer_value(class_num)) # define the embedding layer
emb = paddle.layer.embedding(input=data, size=emb_dim)
# max pooling to reduce the input sequence into a vector (non-sequence)
seq_pool = paddle.layer.pooling(
input=emb, pooling_type=paddle.pooling.Max()) for idx, hidden_size in enumerate(hidden_layer_sizes):
hidden_init_std = 1.0 / math.sqrt(hidden_size)
hidden = paddle.layer.fc(
input=hidden if idx else seq_pool,
size=hidden_size,
act=paddle.activation.Tanh(),
param_attr=paddle.attr.Param(initial_std=hidden_init_std)) prob = paddle.layer.fc(
input=hidden,
size=class_num,
act=paddle.activation.Softmax(),
param_attr=paddle.attr.Param(initial_std=1.0 / math.sqrt(class_num))) if is_infer:
return prob
else:
return paddle.layer.classification_cost(
input=prob, label=lbl), prob, lbl def convolution_net(dict_dim,
class_dim=,
emb_dim=,
hid_dim=,
is_infer=False):
"""
cnn network definition
:param dict_dim: size of word dictionary
:type input_dim: int
:params class_dim: number of instance class
:type class_dim: int
:params emb_dim: embedding vector dimension
:type emb_dim: int
:params hid_dim: number of same size convolution kernels
:type hid_dim: int
""" # input layers
data = paddle.layer.data("word",
paddle.data_type.integer_value_sequence(dict_dim))
lbl = paddle.layer.data("label", paddle.data_type.integer_value(class_dim)) # embedding layer
emb = paddle.layer.embedding(input=data, size=emb_dim) # convolution layers with max pooling
conv_3 = paddle.networks.sequence_conv_pool(
input=emb, context_len=, hidden_size=hid_dim)
conv_4 = paddle.networks.sequence_conv_pool(
input=emb, context_len=, hidden_size=hid_dim) # fc and output layer
prob = paddle.layer.fc(
input=[conv_3, conv_4], size=class_dim, act=paddle.activation.Softmax()) if is_infer:
return prob
else:
cost = paddle.layer.classification_cost(input=prob, label=lbl) return cost, prob, lbl
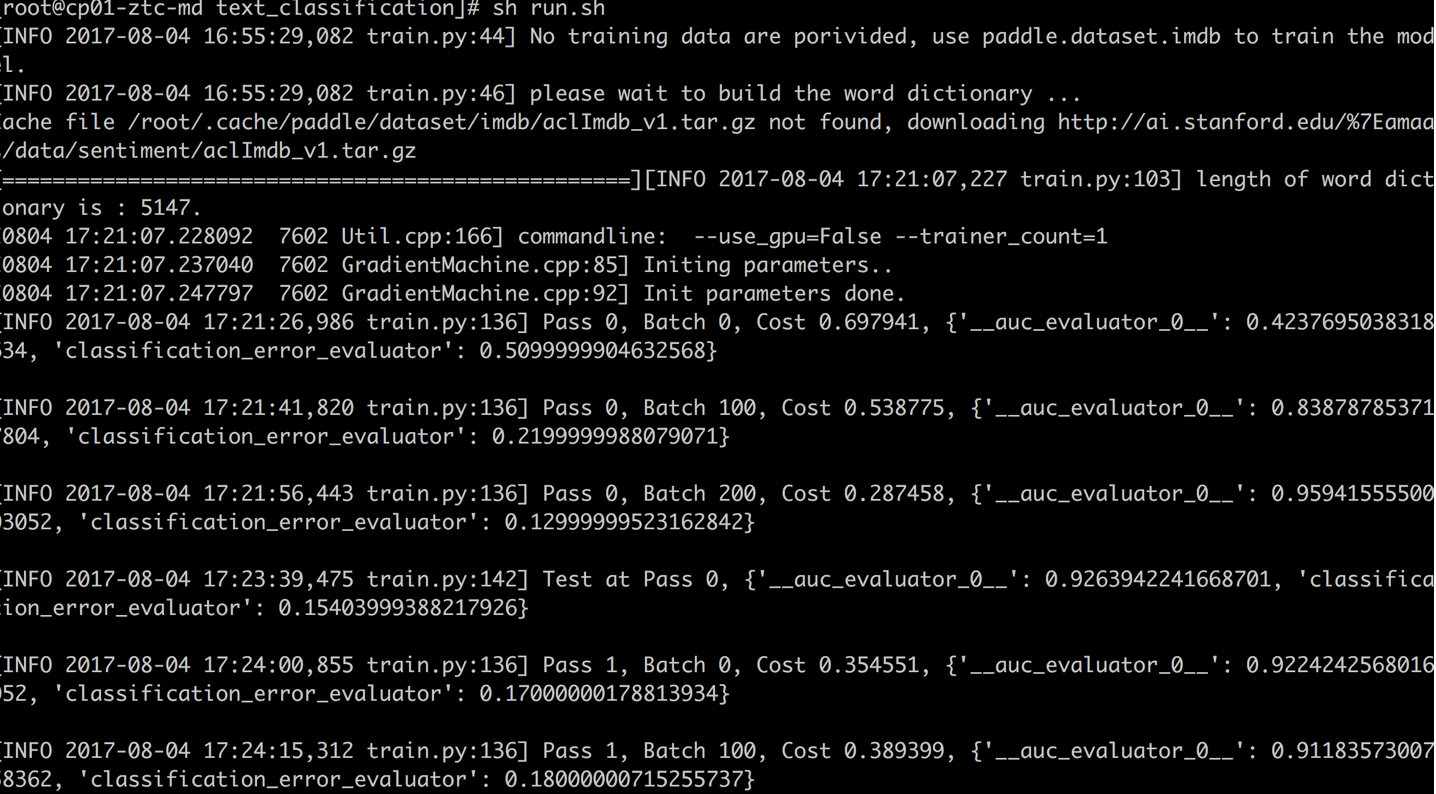
训练结果如下图:
预估结果:

dnn文本分类的更多相关文章
- tensoFlow之DNN文本分类
TensorFlow文本分类: 亲测可用:https://blog.csdn.net/u012052268/article/details/77862202 简单实例:https://www.leip ...
- 一文详解如何用 TensorFlow 实现基于 LSTM 的文本分类(附源码)
雷锋网按:本文作者陆池,原文载于作者个人博客,雷锋网已获授权. 引言 学习一段时间的tensor flow之后,想找个项目试试手,然后想起了之前在看Theano教程中的一个文本分类的实例,这个星期就用 ...
- [深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心)
[深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心) 配合阅读: [深度概念]·Attention机制概念学习笔记 [TensorFlow深度学习深入]实战三·分别使用 ...
- 使用CNN做文本分类——将图像2维卷积换成1维
使用CNN做文本分类 from __future__ import division, print_function, absolute_import import tensorflow as tf ...
- Tensorflow二分类处理dense或者sparse(文本分类)的输入数据
这里做了一些小的修改,感谢谷歌rd的帮助,使得能够统一处理dense的数据,或者类似文本分类这样sparse的输入数据.后续会做进一步学习优化,比如如何多线程处理. 具体如何处理sparse 主要是使 ...
- Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案
Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案 1.1. 七.什么是贝叶斯过滤器?1 1.2. 八.建立历史资料库2 1.3. 十.联合概率的计算3 1.4. 十一. ...
- 基于weka的文本分类实现
weka介绍 参见 1)百度百科:http://baike.baidu.com/link?url=V9GKiFxiAoFkaUvPULJ7gK_xoEDnSfUNR1woed0YTmo20Wjo0wY ...
- LingPipe-TextClassification(文本分类)
What is Text Classification? Text classification typically involves assigning a document to a catego ...
- 文本分类之特征描述vsm和bow
当我们尝试使用统计机器学习方法解决文本的有关问题时,第一个需要的解决的问题是,如果在计算机中表示出一个文本样本.一种经典而且被广泛运用的文本表示方法,即向量空间模型(VSM),俗称“词袋模型”. 我们 ...
随机推荐
- BeanCopier类
网上学习了一番BeanCopier类. cglib是一款比较底层的操作java字节码的框架. 下面通过拷贝bean对象来测试BeanCopier的特性: public class OrderEntit ...
- 第1次作业:使用Packet Tracer分析HTTP数据包
个人信息: • 姓名:李微微 • 班级:计算1811 • 学号:201821121001 一.摘要 本文将会描述使用Packet Tracer工具用到的网络结构 ...
- Sublime Text 3 中实现编译C语言程序
这个是真坑,感觉用devc++写c程序特别的不爽,所以就用了sublime,但是,编译的时候又有不少问题, 下面就把我踩的坑记录下来 tools>Build System>New Buil ...
- 让API实现版本管理的实践
API版本管理的重要性不言而喻,对于API的设计者和使用者而言,版本管理都有着非常重要的意义.下面会从WEB API 版本管理的角度提供几种常见办法: 首先,对于API的设计和实现者而言,需要考虑向后 ...
- xshell调用xmanager,打开linux远程桌面
xshell输入命令:gnome-panel
- 7.Sentinel源码分析—Sentinel是怎么和控制台通信的?
这里会介绍: Sentinel会使用多线程的方式实现一个类Reactor的IO模型 Sentinel会使用心跳检测来观察控制台是否正常 Sentinel源码解析系列: 1.Sentinel源码分析-F ...
- 我面向 Google 编程,他面向薪资编程
面试官:同学,说一说面向对象有什么好处? 神仙开发者:我觉的面向对象编程没有什么好处. 面试官:为什么(摊手.问号脸)? 神仙开发者:因为在面向对象的时候,我对象总是跟我说话,问我在淘宝上挑的衣服哪个 ...
- AppBoxFuture: Raft快照及日志截断回收
AppBoxFuture的存储引擎依赖Raft一致性协议来保证各个分区副本的一致性,如果不处理Raft日志将不断增长,因此需要特定的机制(定期或每处理一定数量的日志)来回收那些无用的日志数据.通过 ...
- 关于react-router最新版本的使用
现在react-router已经更新到了5.1.1版本,在一些使用方法上较之前有了很多改变,现做初步列举,以后会陆续更新. 关于引入react-router和基本使用 旧版本中引入react-rout ...
- java获取配置文件中的key=value值
1.献上工具类 package com.test.util; import java.io.FileInputStream; import java.io.FileNotFoundException; ...