CVPR 2019 论文解读 | 小样本域适应的目标检测

引文
最近笔者也在寻找目标检测的其他方向,一般可以继续挖掘的方向是从目标检测的数据入手,困难样本的目标检测,如检测物体被遮挡,极小人脸检测,亦或者数据样本不足的算法。这里笔者介绍一篇小样本(few-shot)数据方向下的域适应(Domain Adaptation)的目标检测算法,这篇新加坡国立大学&华为诺亚方舟实验室的paper《Few-shot Adaptive Faster R-CNN》被收录于CVPR2019,解决的具体问题场景是我们有在普通常见场景下的汽车目标检测,我们只有少量雾天暴雨极劣天气环境下的汽车样本,那么我们可以使用成对采样(pairing-sampling)的方法,源域(source domain)即普通场景下的汽车样本\(Car_{s}\)和目标域(target domain)即恶劣天气下的汽车样本\(Car_{t}\)成对\((Car_s,Car_t)\)组成负样本,另一方面源域下成对组成正样本\((Car_s,Car_s)\),使用GAN的结构,判别器(discriminator)尽可能去分辨正负样本的不同,也就是分辨出源域和目标域的样本,生成器(generator)是尝试去迷惑判别器。这就是这个算法的主要思想,主要是把域适应的思想应用到了目标检测上。
论文源码还没完全开源,只找到了个官方的repo:https://github.com/twangnh/FAFRCNN
思考
在介绍文章具体网络设计和损失函数的设计之前,我们可以带着一个问题去思考。
- 用GAN的结构,数据样本使用\(Car_s\)作为正样本、\(Car_t\)作为负样本也可以使判别器(discriminator)分辨出源域和目标域的样本,为什么这里要组成对的去训练?
算法设计
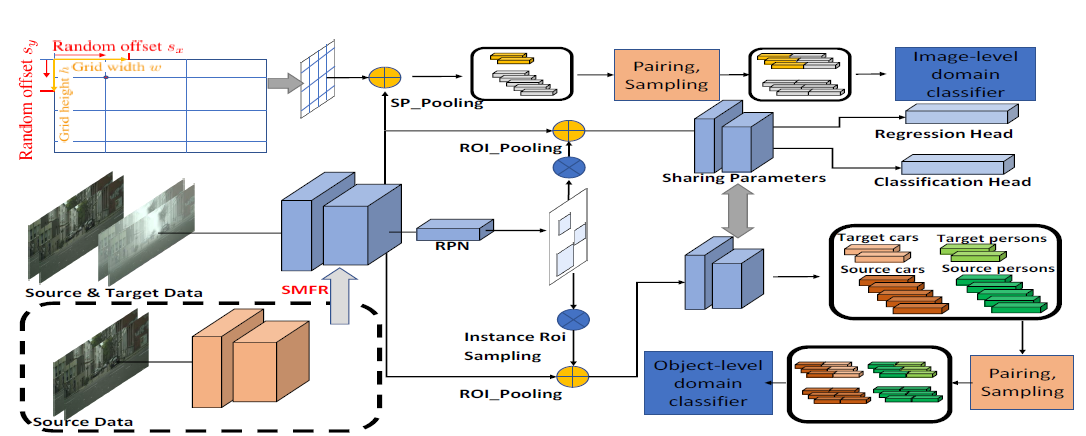
Fig 1. Few-shot Adaptive Faster R-CNN (FAFRCNN)的整体网络结构(其中的SMFR模块后面会介绍到)
在目标检测的任务中,论文作者把域适应问题分成**两个层次**:
- 图像级别的域适应
- 实例级别的域适应
具体可以看下面Fig2的第一行和第三行,图像级别下的域迁移是整体图像各个像素组成的域迁移,实例级别的域迁移是汽车样本下的域迁移。
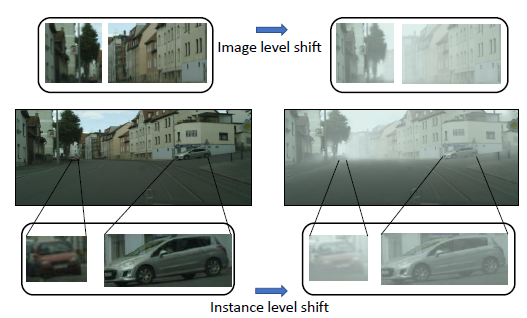
Fig 2. 中间为两张来自Cityspaces和Foggy Cityspaces的图片。第一行为图像级别的域迁移,第三行为实例级别的域迁移。
图像级别的域适应
图像级别的域适应(Image-level Adaptation) 是为了完成image-to-image的转换,论文提出了split pooling(SP)的方法,作用是为了随机放置grid,做法也是十分简单,grid cell的宽为w,高为h,然后随机生成sx和xy,grid根据sx和sy调整位置。

Fig 3. grid的选择
得到grid之后,论文把grid与Faster R-CNN中选取anchor boxes一样,采取了三种scale和三种ratio,split pooling对应在提取的特征$f(x)$中也是有大(l)、中(m)、小(s)三种scale: $sp_l(f(x)),sp_m(f(x)),sp_s(f(x))$。
后面就可以用对抗训练的方式训练生成器和判别器了,但是因为目标域的样本是小样本数据,所以这里提出了成对训练的方式,即源域对\(G_{s_1}={(g_s,g_s)}\)和源域-目标域对\(G_{s_2}={(g_s,g_t)}\)。判别器判断样本来源,生成器是特征提取器器目标是混淆判别器。
\]
\]
\]
另外论文在图像级别的域适应用了三个GAN,实用性不知道如何。
实例级别的域适应
跟Faster R-CNN中不同的是:foreground ROIs要求更高的IOU阈值(比如原本IOU要求是0.5的,现在可能要0.7)。获得了ROI特征之后会根据ROI的label分组,源域目标特征是\(O_{is}\),目标域目标特征为\(O_{it}\),如果一共有C类,\(i\in[0,C]\),第0类为背景,其实跟图像级别的成对方式一样,源域对\(N_{i1}=\{(n_{is},n_{is})\}\)和源域目标域对\(N_{i2}=\{(n_{is},n_{it})\}\),其中\(n_{is}\sim O_{is},n_{it}\sim O_{it}\),以下为域判别器的损失函数:
\]
以下为feature generator的损失函数:
\]
源域模型特征正则化
这个部分就是Fig 1中的SMFR模块,全称为Source Model Feature Regularization,他的作用是正则化源域模型,具体来说,就是源域样本\(x_s\)经过论文的域适应adaptation之后的特征提取器\(f_t\)和初始时拥有的仅有源域样本训练的特征提取器\(f_s\)要尽可能的一致,这样才能使模型更加鲁棒,文章用了L2正则。
\]
但是因为是目标检测模型,我们更关注的是图片的前景目标本身,所以我们要求的是源域样本\(x_s\)经过特征提取器之后的前景部分变化不大。
\]
其中\(M\)为前景的mask,k为正例掩码位置的个数。
实验结果
实验中数据集采用以下5种:
- Scenario-1: SIM10K to Udacity (\(S\rightarrow U\));
- Scenario-2: SIM10K to Cityscapes (\(S\rightarrow C\));
- Scenario-3: Cityscapes to Udacity (\(C\rightarrow U\));
- Scenario-4: Udacity to Cityscapes (\(U\rightarrow C\));
- Scenario-5: Cityscapes to Foggy Cityscapes (\(C\rightarrow F\)).
以下都是采用AP作为对比评价指标。
 |
 |
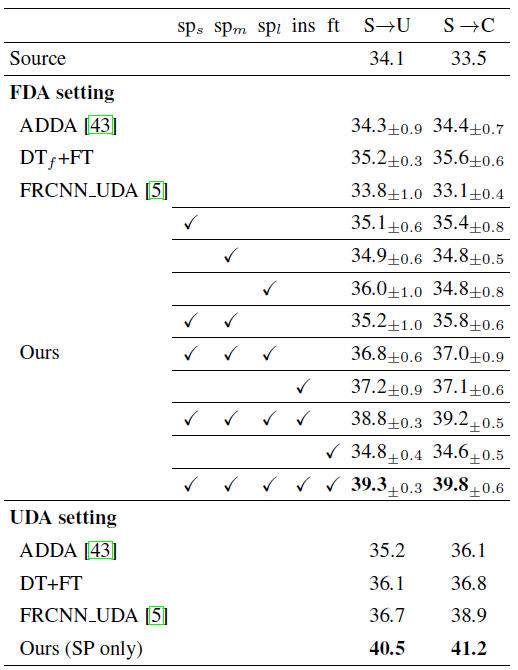
Fig 4. 左边是SP技术在Scenario-1和Scenario-2的效果。右边是SP技术在Scenario-3和Scenario-4的效果。sp表示的是split pooling,ins表示加入实例级别的域适应,ft表示加入fine-tunning loss。
可以看出,在加入SP技术之后AP得到明显的提高,比**ADDA [1]**高了5个点。
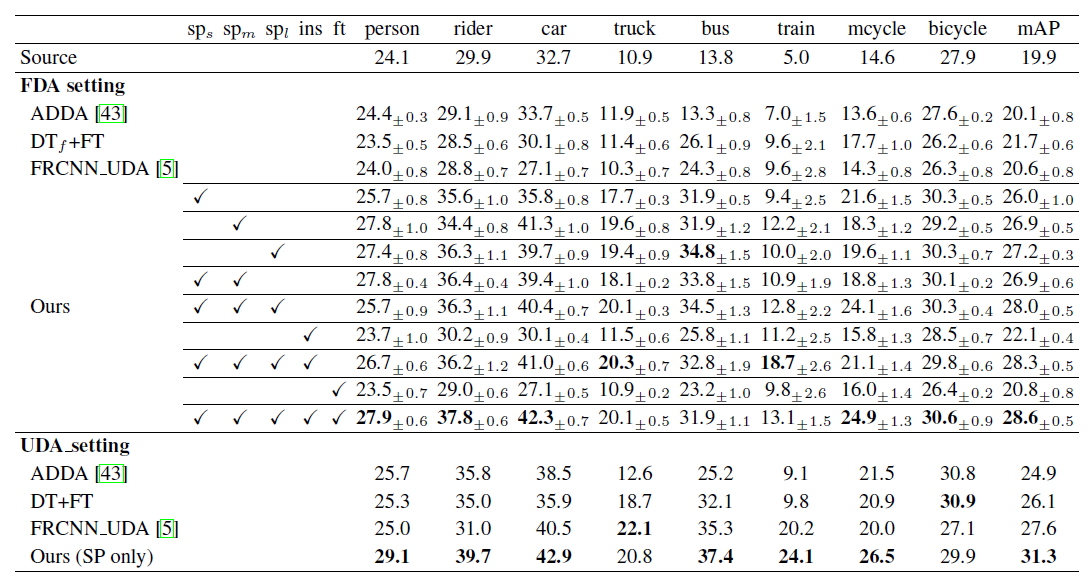
Fig 5. 论文提出的方法在Scenario-5中的各个实例的AP指标对比
从UDA_setting中看到其实并不是全部都能取到最优成绩。
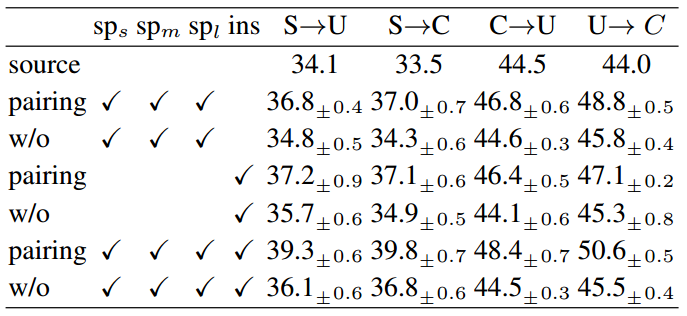
Fig 6. 引入pairing理论的效果
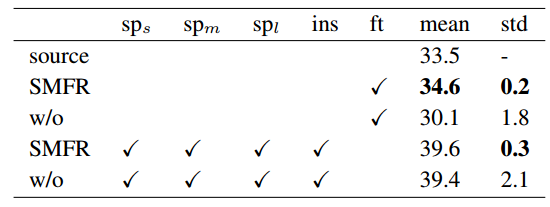
Fig 7. SMFR的效果
总结思考
回答文首的问题,相信很多读者读完全文之后肯定也知道答案了,paper题目就是基于小样本学习方向的,其实需要成对训练的目的就是增加训练样本,如果源域样本\(Car_s\)有n个,目标域样本\(Car_t\)有m个(n>m),那么最后负样本的个数仅仅只有m个,因为是小样本,训练出来的效果也会十分的差。但是如果成对训练(pairing-sampling),正样本为\((Car_s,Car_s)\),理论上样本数量为\(n^2\),为s负样本为\((Car_s,Car_t)\),理论上样本数量为\(n*m\),虽然经过这样笛卡尔积之后的正负样本比没有变,但是负样本数量却是增多了。这也是整篇文章的主要思想,pairing-sampling的去训练。
参考文献
- [1]. Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In Computer Vision and Pattern Recognition (CVPR), volume 1, page 4, 2017.
CVPR 2019 论文解读 | 小样本域适应的目标检测的更多相关文章
- CVPR 2019|PoolNet:基于池化技术的显著性检测 论文解读
作者 | 文永亮 研究方向 | 目标检测.GAN 研究动机 这是一篇发表于CVPR2019的关于显著性目标检测的paper,在U型结构的特征网络中,高层富含语义特征捕获的位置信息在自底向上的传播过 ...
- 医学AI论文解读 |Circulation|2018| 超声心动图的全自动检测在临床上的应用
文章来自微信公众号:机器学习炼丹术.号主炼丹兄WX:cyx645016617.文章有问题或者想交流的话欢迎- 参考目录: @ 目录 0 论文 1 概述 2 pipeline 3 技术细节 3.1 预处 ...
- CVPR 2019 行人检测新思路:
CVPR 2019 行人检测新思路:高级语义特征检测取得精度新突破 原创: CV君 我爱计算机视觉 今天 点击我爱计算机视觉置顶或标星,更快获取CVML新技术 今天跟大家分享一篇昨天新出的CVPR 2 ...
- 经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
前言: 目标检测的预测框经过了滑动窗口.selective search.RPN.anchor based等一系列生成方法的发展,到18年开始,开始流行anchor free系列,CornerNe ...
- 腾讯推出超强少样本目标检测算法,公开千类少样本检测训练集FSOD | CVPR 2020
论文提出了新的少样本目标检测算法,创新点包括Attention-RPN.多关系检测器以及对比训练策略,另外还构建了包含1000类的少样本检测数据集FSOD,在FSOD上训练得到的论文模型能够直接迁移到 ...
- 增量学习不只有finetune,三星AI提出增量式少样本目标检测算法ONCE | CVPR 2020
论文提出增量式少样本目标检测算法ONCE,与主流的少样本目标检测算法不太一样,目前很多性能高的方法大都基于比对的方式进行有目标的检测,并且需要大量的数据进行模型训练再应用到新类中,要检测所有的类别则需 ...
- 【论文解读】行人检测:What Can Help Pedestrian Detection?(CVPR'17)
前言 本篇文章出自CVPR2017,四名作者为Tsinghua University,Peking University, 外加两名来自Megvii(旷视科技)的大佬. 文章中对能够帮助行人检测的ex ...
- Object Detection · RCNN论文解读
转载请注明作者:梦里茶 Object Detection,顾名思义就是从图像中检测出目标对象,具体而言是找到对象的位置,常见的数据集是PASCAL VOC系列.2010年-2012年,Object D ...
- CVPR2020论文解读:CNN合成的图片鉴别
CVPR2020论文解读:CNN合成的图片鉴别 <CNN-generated images are surprisingly easy to spot... for now> 论文链接:h ...
随机推荐
- XHTML 和 HTML 中的 iframe
1. XHTML 有什么? XHTML是更严谨更纯净的HTML版本. 2.HTML和XHTML之间的差异 ①XHTML元素必须被正确的嵌套 /!--错误写法--/ <p><i> ...
- Windows下Python 3.6 + VS2017 + Anaconda 解决Unable to find vcvarsall.bat问题
Python 3.6 + VS2017 + Anaconda 解决Unable to find vcvarsall.bat问题 已经安装了VS2017,需要将项目中的C代码翻译为Python代码,在编 ...
- 前端开发-CSS语法标准
一.命名规则说明: 1.命名规则说明: 所有的命名最好都小写 属性的值一定要用双引号("")括起来,且一定要有值如class="nav",id="na ...
- Python Web Flask源码解读(三)——模板渲染过程
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- json-server的安装及使用
首先介绍一下什么是json-server,用处是什么,其实很简单:JSON-Server 是一个 Node 模块,运行 Express 服务器,你可以指定一个 json 文件作为 api 的数据源. ...
- CodeForces 283C World Eater Brothers
World Eater Brothers 题解: 树DP, 枚举每2个点作为国家. 然后计算出最小的答案. 首先我们枚举根, 枚举根了之后, 我们算出每个点的子树内部和谐之后的值是多少. 这样val[ ...
- Atcode B - Colorful Hats(思维)
题目链接:http://agc016.contest.atcoder.jp/tasks/agc016_b 题解:挺有意思的题目主要还是模拟出最多有几种不可能的情况,要知道ai的差距不能超过1这个想想就 ...
- Spring@Autowired java.lang.NullPointerException 空指针
在使用@Autowired注解注入出现的空指针 java.lang.NullPointerException 可能存在的错误原因: 1.注解的扫描有问题 在xml配置了这个标签后,spring可以 ...
- 自动化专业如何转SLAM或机器学习岗?
由于不方便放链接,更好的阅读体验请查看:自动化专业如何转SLAM或机器学习岗? 本文来自知乎上的同名问题,原文链接: https://www.zhihu.com/question/266685012/ ...
- Dokit支持iOS本地crash查看功能
一.前言 在日常开发中或者测试过程中,我们的应用可能会出现Crash的问题.对于这类问题我们要抱着零容忍的态度,因为如果线上出现了这类问题,将会严重影响用户的体验. 如果Crash出现的时候恰好是在开 ...