Flink的Job启动TaskManager端(源码分析)
前面说到了 Flink的JobManager启动(源码分析) 启动了TaskManager
然后 Flink的Job启动JobManager端(源码分析) 说到JobManager会将转化得到的TDD发送到TaskManager的RPC
这篇主要就讲一下,Job在TaskManager端是如何启动的
先来看一下,TaskManager端用来接收JobManager发送过来的TDD对象的RPC接口
在TaskExecutor.java中

这个方法用于接收了一个TaskDeploymentDescriptor对象用于启动任务(上一篇知道这里executionGraph的每一个并行度都会调用deploy方法生成一个TDD)
来看一下具体接收到以后做了什么


创建了一个Task并且将其内部的一个线程启动起来了
注意这里从TDD中得到了InputGate,Partition的信息,用于创建InputGate,ResultPartition
InputGate用于对接上游产生的数据(消费)
ResultPartition用于往下游发送自己产生的数据(生产)
来看一下Task创建,在Task的构造方法中
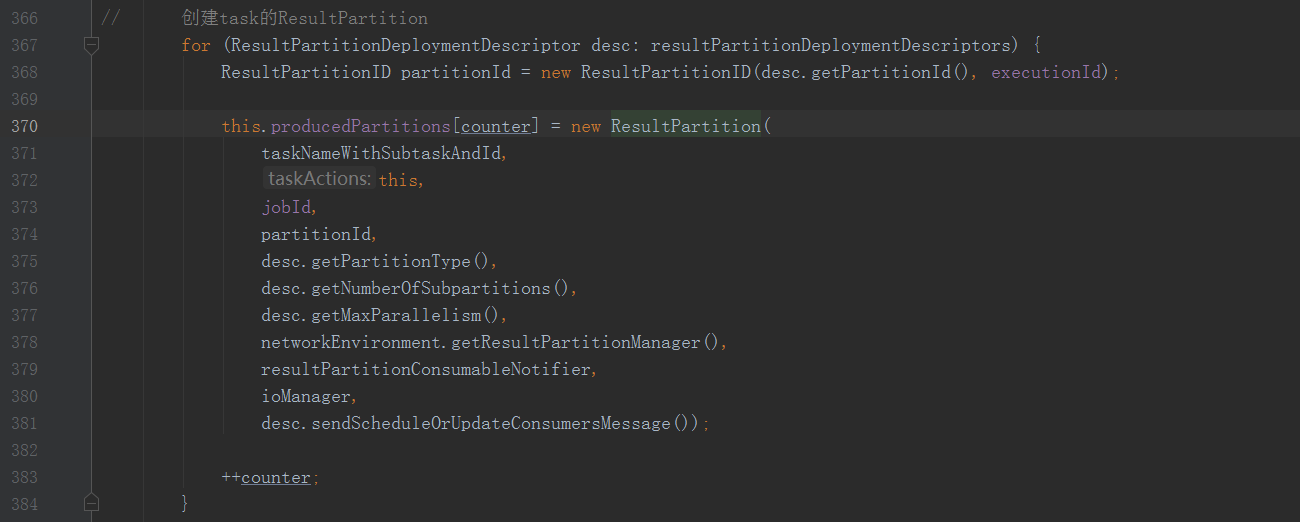
这里看到创建了对应往下游发送数据的ResultPartition
ResultPartition中创建的SubPartition具体分为
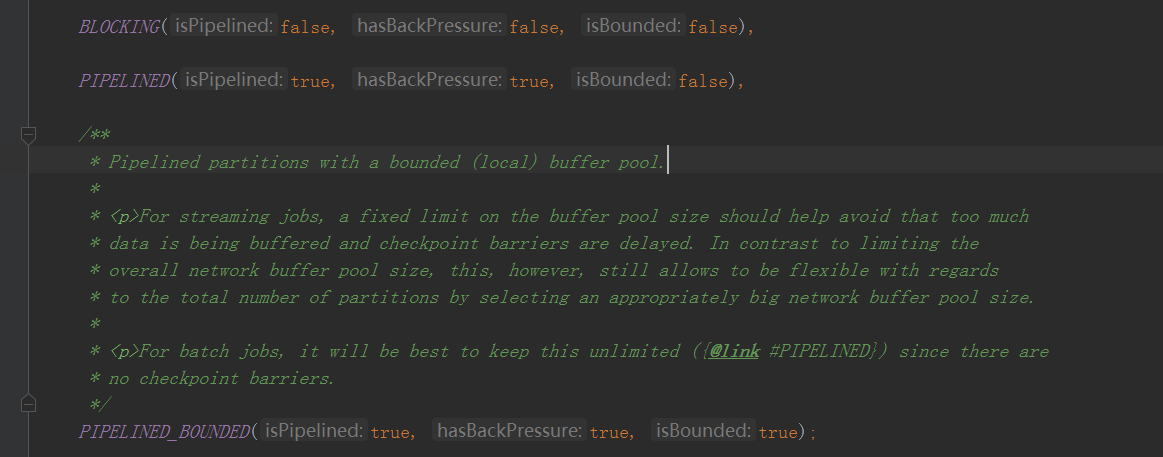
可以看到就是说三个参数分别对应
PIPELINED 可以边消费边生产,是有背压的,这个partition没有buffer数量的限制(因为背压的控制是通过接,收数据端公用同一个指定大小的bufferPool,以后背压的时候讲)
其他同理
这里看一下不同类型的ResultPartitionType是创建的什么subpartitions

BLOCKING 这种创建了一个SpillableSubpartition并且传进去了一个ioManager(这个ioManager以后io管理细讲)
大致看了一下就是说这种Subpartition是会落盘的
PIPELINED 而这种方式是完全基于内存的
根据上游的信息创建好ResultPartition以后

接着创建了InputGate用于接收上游的数据,并且在create方法中

会根据partition的位置创建对应的channel,这里可以分为
Local 就是说下游和自己是在同一台机器
Remote 下游是需要通过网络发送的

并且在这里将inputGate和它所有的inputChannels关联了起来
创建完inputGate以后Task就初始化完了,然后会被start()起来,来看下Task的run方法
在run方法中

这个地方会为初始化inputGate与ResultPartition的bufferPool(以后讲到反压在讲)
继续

这里通过反射创建了一个StreamTask的实例
并且

调用了他的invoke()方法,这里也是Job开始的逻辑,来看一下invoke方法
在invoke方法中

只要知道这里会初始化OperatorChain这里包含了我们用户算子的逻辑(这里不细讲,随缘讲到Task操作责任链的时候讲)
然后得到了operatorChain的头headoperator其实这里的头就包含了用户的第一个算子逻辑在里面
然后init()方法中用上面的headoperator初始化了一个inputProcess对象并且关联上了上面创建的inputGate(也是留到责任链讲)
接着


这里就是上面在init方法中创建的inputProcess,并且调用了他的processInput方法
重头戏来了,来看一下processInput方法

这里有个while(true)也就是说这里会一直循环下去
来看一下他循环做什么
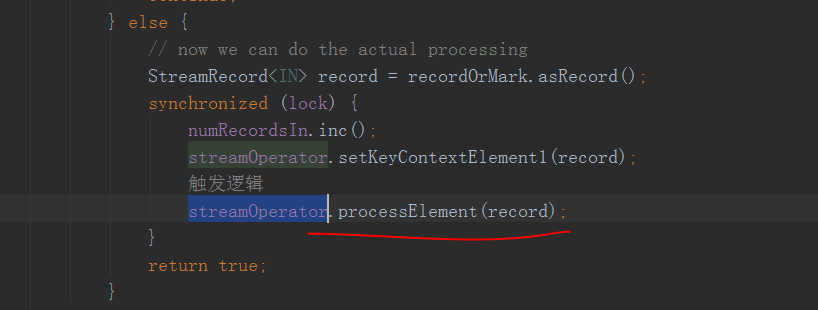
这里!!!!这个streamOperator就是上面构造inputProcess时传入的headOperator
这个processElement方法里面就是调用用户的方法啦
也就是不停的从上游接收到数据以后,调用用户具体的处理逻辑
这里job就启动完成了
注意这个while循环内既然开始走我们用户的逻辑,那肯定会先从inputGate关联到的上游获取数据
这里就非常重要了,因为接收数据就包含了很多的机制的实现
包含了watermark处理的逻辑,水印对齐的逻辑,水印更新的逻辑,如下

以及idle停滞流逻辑,流状态更新逻辑

以及如何接收数据逻辑,接收端反压的逻辑,barriers对齐的逻辑,checkpoint触发的逻辑

所以这个StreamInputProcessor.processInput()方法是一个非常重要的方法,以后随缘更新各种机制的时候也会经常看到
Flink的Job启动TaskManager端(源码分析)的更多相关文章
- Flink的Job启动JobManager端(源码分析)
通过前面的文章了解到 Driver将用户代码转换成streamGraph再转换成Jobgraph后向Jobmanager端提交 JobManager启动以后会在Dispatcher.java起来RPC ...
- Flink的Job启动Driver端(源码分析)
整个Flink的Job启动是通过在Driver端通过用户的Envirement的execute()方法将用户的算子转化成StreamGraph,然后得到JobGraph通过远程RPC将这个JobGra ...
- Flink中Idle停滞流机制(源码分析)
前几天在社区群上,有人问了一个问题 既然上游最小水印会决定窗口触发,那如果我上游其中一条流突然没有了数据,我的窗口还会继续触发吗? 看到这个问题,我蒙了???? 对哈,因为我是选择上游所有流中水印最小 ...
- Android Activity Deeplink启动来源获取源码分析
一.前言 目前有很多的业务模块提供了Deeplink服务,Deeplink简单来说就是对外部应用提供入口. 针对不同的跳入类型,app可能会选择提供不一致的服务,这个时候就需要对外部跳入的应用进行区分 ...
- Netty服务端启动过程相关源码分析
1.Netty 是怎么创建服务端Channel的呢? 我们在使用ServerBootstrap.bind(端口)方法时,最终调用其父类AbstractBootstrap中的doBind方法,相关源码如 ...
- Flink中异步AsyncIO的实现 (源码分析)
先上张图整体了解Flink中的异步io 阿里贡献给flink的,优点就不说了嘛,官网上都有,就是写库不会柱塞性能更好 然后来看一下, Flink 中异步io主要分为两种 一种是有序Ordered 一种 ...
- Flink中的CEP复杂事件处理 (源码分析)
其实CEP复杂事件处理,简单来说你可以用通过类似正则表达式的方式去表示你的逻辑,表现能力非常的强,用过的人都知道 开篇先偷一张图,整体了解Flink中的CEP中的 一种重要的图 NFA非确定有限状 ...
- Flink 中LatencyMarks延迟监控(源码分析)
流式计算中处理延迟是一个非常重要的监控metric flink中通过开启配置 metrics.latency.interval 来开启latency后就可以在metric中看到askManage ...
- spring mvc 启动过程及源码分析
由于公司开源框架选用的spring+spring mvc + mybatis.使用这些框架,网上都有现成的案例:需要那些配置文件.每种类型的配置文件的节点该如何书写等等.如果只是需要项目能够跑起来,只 ...
随机推荐
- 确保Web安全的HTTPS
HTTP在安全方面主要有以下不足: 1. 通信使用明文不加密,内容可能会被窃听:(TCP/IP就是可能被窃听的网络) 2. 不验证通信方的身份,因此有可能遭遇伪装: (无法判断请求或响应是否正确,是否 ...
- React入门理解demo
1.React文档结构 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- Angular JS 中的服务注册方法
在Angular JS中创建服务的几种方法 factory() service() constant() value() provider() factory(name,fn(){}) 该服务为单例的 ...
- iOS 注释
1) 参数的注释: UIButton *btnSend;/**< 发送按钮 */ 效果: 2) 方法的注释: type1(无参数): /** table 相关设置 */ -(void)confi ...
- Linux进程间通信——信号
一.认识信号 信号(Signals)是Unix.类Unix以及其他POSIX兼容的操作系统中进程间通讯的一种有限制的方式.它是一种异步的通知机制,用来提醒进程一个事件已经发生.当一个信号发送给一个进程 ...
- codeforces 371A K-Periodic Array
很简单,就是找第i位.i+k位.i+2*k位...........i+m*k位有多少个数字,计算出每个数出现的次数,找到出现最多的数,那么K-Periodic的第K位数肯定是这个了.这样的话需要替换的 ...
- Mobile game forensics
My friend Carrie'd like to know "Garena 传说对决" violates any mobile risks such as insecure d ...
- Winform DataGridView 取消默认选中行
困境 网上有很多解决方法,可是很多读者照做并不生效.追究其原因,问题出现在许多博主没有搞清楚DataGridView绑定与当前触发事件的关系. 复现 private void Frm_Load(obj ...
- fiddler设置断点
1.有两种方法设置断点 before response:也就是发送请求之后,但是Fiddler代理中转之前,这时可以修改请求的数据 after response:也就是服务器响应之后,但是在Fiddl ...
- n的阶乘 -牛客
题目描述 输入一个整数n,输出n的阶乘(每组测试用例可能包含多组数据,请注意处理) 输入描述: 一个整数n(1<=n<=20) 输出描述: n的阶乘 解题思路 采用递归求解,也可以使用循环 ...