Flink的Job启动TaskManager端(源码分析)
前面说到了 Flink的JobManager启动(源码分析) 启动了TaskManager
然后 Flink的Job启动JobManager端(源码分析) 说到JobManager会将转化得到的TDD发送到TaskManager的RPC
这篇主要就讲一下,Job在TaskManager端是如何启动的
先来看一下,TaskManager端用来接收JobManager发送过来的TDD对象的RPC接口
在TaskExecutor.java中

这个方法用于接收了一个TaskDeploymentDescriptor对象用于启动任务(上一篇知道这里executionGraph的每一个并行度都会调用deploy方法生成一个TDD)
来看一下具体接收到以后做了什么


创建了一个Task并且将其内部的一个线程启动起来了
注意这里从TDD中得到了InputGate,Partition的信息,用于创建InputGate,ResultPartition
InputGate用于对接上游产生的数据(消费)
ResultPartition用于往下游发送自己产生的数据(生产)
来看一下Task创建,在Task的构造方法中
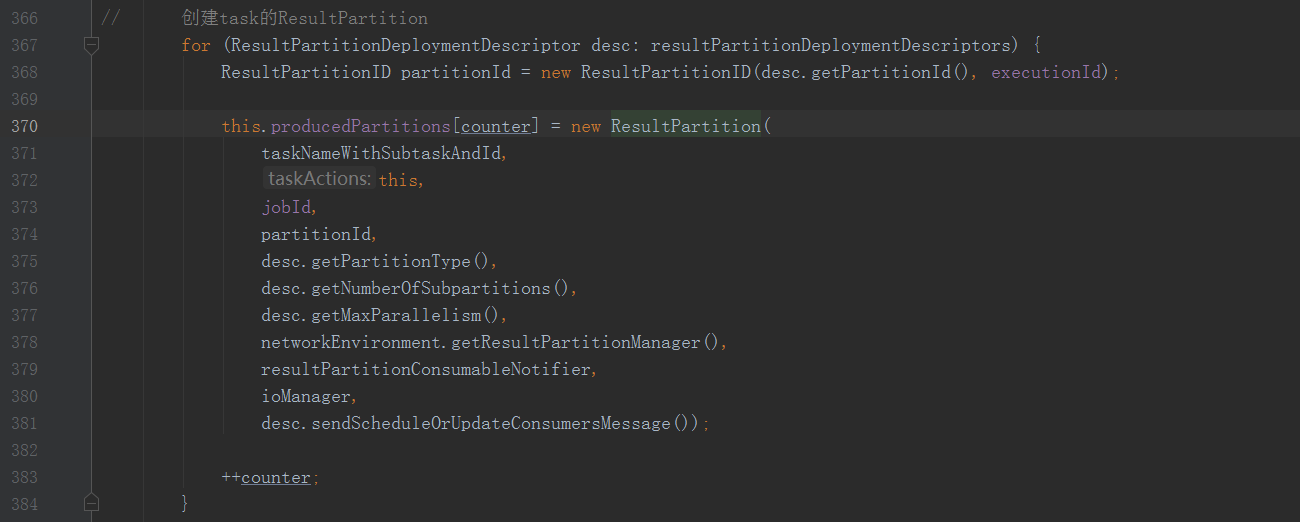
这里看到创建了对应往下游发送数据的ResultPartition
ResultPartition中创建的SubPartition具体分为
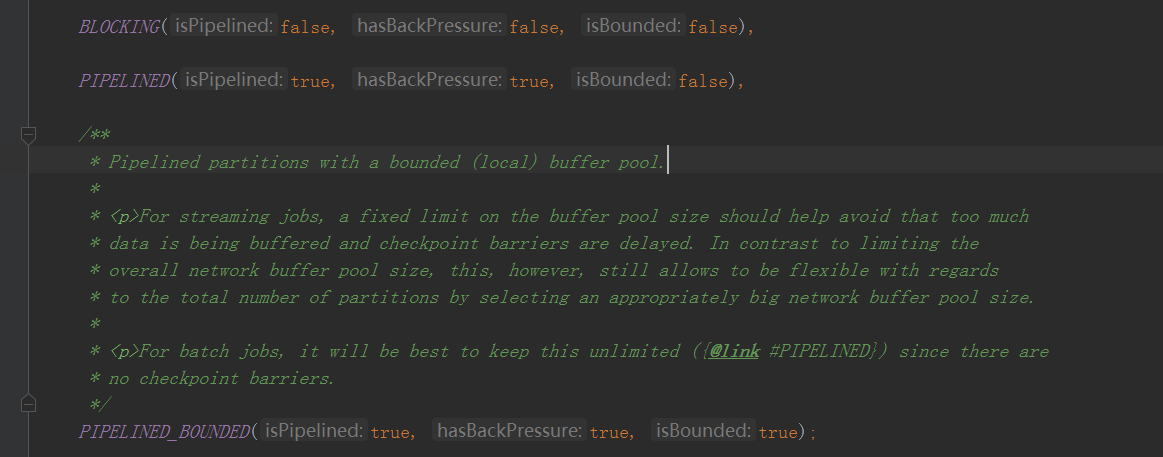
可以看到就是说三个参数分别对应
PIPELINED 可以边消费边生产,是有背压的,这个partition没有buffer数量的限制(因为背压的控制是通过接,收数据端公用同一个指定大小的bufferPool,以后背压的时候讲)
其他同理
这里看一下不同类型的ResultPartitionType是创建的什么subpartitions

BLOCKING 这种创建了一个SpillableSubpartition并且传进去了一个ioManager(这个ioManager以后io管理细讲)
大致看了一下就是说这种Subpartition是会落盘的
PIPELINED 而这种方式是完全基于内存的
根据上游的信息创建好ResultPartition以后

接着创建了InputGate用于接收上游的数据,并且在create方法中

会根据partition的位置创建对应的channel,这里可以分为
Local 就是说下游和自己是在同一台机器
Remote 下游是需要通过网络发送的

并且在这里将inputGate和它所有的inputChannels关联了起来
创建完inputGate以后Task就初始化完了,然后会被start()起来,来看下Task的run方法
在run方法中

这个地方会为初始化inputGate与ResultPartition的bufferPool(以后讲到反压在讲)
继续

这里通过反射创建了一个StreamTask的实例
并且

调用了他的invoke()方法,这里也是Job开始的逻辑,来看一下invoke方法
在invoke方法中

只要知道这里会初始化OperatorChain这里包含了我们用户算子的逻辑(这里不细讲,随缘讲到Task操作责任链的时候讲)
然后得到了operatorChain的头headoperator其实这里的头就包含了用户的第一个算子逻辑在里面
然后init()方法中用上面的headoperator初始化了一个inputProcess对象并且关联上了上面创建的inputGate(也是留到责任链讲)
接着


这里就是上面在init方法中创建的inputProcess,并且调用了他的processInput方法
重头戏来了,来看一下processInput方法

这里有个while(true)也就是说这里会一直循环下去
来看一下他循环做什么
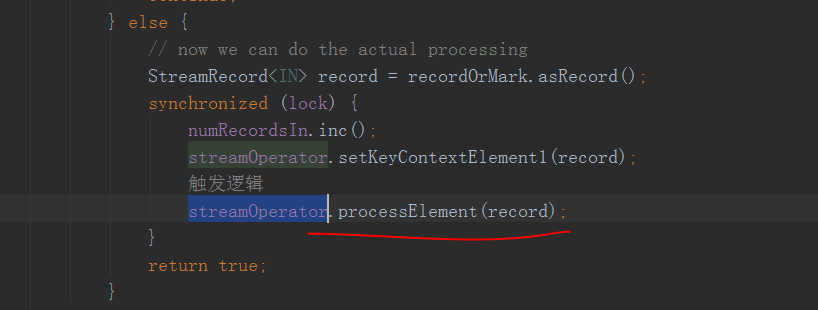
这里!!!!这个streamOperator就是上面构造inputProcess时传入的headOperator
这个processElement方法里面就是调用用户的方法啦
也就是不停的从上游接收到数据以后,调用用户具体的处理逻辑
这里job就启动完成了
注意这个while循环内既然开始走我们用户的逻辑,那肯定会先从inputGate关联到的上游获取数据
这里就非常重要了,因为接收数据就包含了很多的机制的实现
包含了watermark处理的逻辑,水印对齐的逻辑,水印更新的逻辑,如下

以及idle停滞流逻辑,流状态更新逻辑

以及如何接收数据逻辑,接收端反压的逻辑,barriers对齐的逻辑,checkpoint触发的逻辑

所以这个StreamInputProcessor.processInput()方法是一个非常重要的方法,以后随缘更新各种机制的时候也会经常看到
Flink的Job启动TaskManager端(源码分析)的更多相关文章
- Flink的Job启动JobManager端(源码分析)
通过前面的文章了解到 Driver将用户代码转换成streamGraph再转换成Jobgraph后向Jobmanager端提交 JobManager启动以后会在Dispatcher.java起来RPC ...
- Flink的Job启动Driver端(源码分析)
整个Flink的Job启动是通过在Driver端通过用户的Envirement的execute()方法将用户的算子转化成StreamGraph,然后得到JobGraph通过远程RPC将这个JobGra ...
- Flink中Idle停滞流机制(源码分析)
前几天在社区群上,有人问了一个问题 既然上游最小水印会决定窗口触发,那如果我上游其中一条流突然没有了数据,我的窗口还会继续触发吗? 看到这个问题,我蒙了???? 对哈,因为我是选择上游所有流中水印最小 ...
- Android Activity Deeplink启动来源获取源码分析
一.前言 目前有很多的业务模块提供了Deeplink服务,Deeplink简单来说就是对外部应用提供入口. 针对不同的跳入类型,app可能会选择提供不一致的服务,这个时候就需要对外部跳入的应用进行区分 ...
- Netty服务端启动过程相关源码分析
1.Netty 是怎么创建服务端Channel的呢? 我们在使用ServerBootstrap.bind(端口)方法时,最终调用其父类AbstractBootstrap中的doBind方法,相关源码如 ...
- Flink中异步AsyncIO的实现 (源码分析)
先上张图整体了解Flink中的异步io 阿里贡献给flink的,优点就不说了嘛,官网上都有,就是写库不会柱塞性能更好 然后来看一下, Flink 中异步io主要分为两种 一种是有序Ordered 一种 ...
- Flink中的CEP复杂事件处理 (源码分析)
其实CEP复杂事件处理,简单来说你可以用通过类似正则表达式的方式去表示你的逻辑,表现能力非常的强,用过的人都知道 开篇先偷一张图,整体了解Flink中的CEP中的 一种重要的图 NFA非确定有限状 ...
- Flink 中LatencyMarks延迟监控(源码分析)
流式计算中处理延迟是一个非常重要的监控metric flink中通过开启配置 metrics.latency.interval 来开启latency后就可以在metric中看到askManage ...
- spring mvc 启动过程及源码分析
由于公司开源框架选用的spring+spring mvc + mybatis.使用这些框架,网上都有现成的案例:需要那些配置文件.每种类型的配置文件的节点该如何书写等等.如果只是需要项目能够跑起来,只 ...
随机推荐
- UTF—8与UTF—8(无bom)格式
BOM——Byte Order Mark,就是字节序标记 在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF.而FFFE在U ...
- 用wxpy管理微信公众号,并利用微信获取自己的开源数据。
之前了解到itchat 乃至于 wxpy时 是利用tuling聊天机器人的接口.调用接口并保存双方的问答结果可以作为自己的问答词库的一个数据库累计.这些数据可以用于自己训练. 而最近希望获取一些语音资 ...
- Java 内存模型详解
概述 Java的内存模型(Java Memory Model )简称JMM.首先应该明白,Java内存模型是一个规范,主要规定了以下两点: 规定了一个线程如何以及何时可以看到其他线程修改过后的共享变量 ...
- 洛谷 P5150 题解
题面 因为 n=lcm(a,b)n = lcm(a, b)n=lcm(a,b) ,可以得出: a 和 b 的质因数都是 n 的质因数 对于 n 的每个质因数 x ,在 n 中的次数为 y ,那么 ...
- GridLayout and GridData
GridLayout的风格 GridLayout类提供了GridLayout 布局中划分网格的信息,主要通过以下几个参数进行设置. 属性: NumColumns:通过“gridLayout.numCo ...
- WPF:window设置单一开启
方法一: Window window = new Window();window.ShowDialog; 方法二: 设置一个判断窗口打开状态的全局控制变量 private bool i ...
- Git 服务使用搭建集合
Git 服务使用搭建集合 一.本地Git 仓库搭建与使用 1.Git 概念介绍 版本控制系统 版本控制是一种记录若干文件内容变化,以便将来查阅特定版本修订情况的系统.大部分时候我们使用最频繁的还是对源 ...
- [Spring cloud 一步步实现广告系统] 16. 增量索引实现以及投送数据到MQ(kafka)
实现增量数据索引 上一节中,我们为实现增量索引的加载做了充足的准备,使用到mysql-binlog-connector-java 开源组件来实现MySQL 的binlog监听,关于binlog的相关知 ...
- Zookeeper的命令行操作(三)
Zookeeper的命令行操作 1. ZooKeeper服务命令 在准备好相应的配置之后,可以直接通过zkServer.sh 这个脚本进行服务的相关操作 1. 启动ZK服务: sh bin/zkSer ...
- JVM 内存模型概述
我们都知道,Java程序在执行前首先会被编译成字节码文件,然后再由Java虚拟机执行这些字节码文件从而使得Java程序得以执行.事实上,在程序执行过程中,内存的使用和管理一直是值得关注的问题.Java ...